Business Analytics Report: Brand Equity and Customer Loyalty Analysis
VerifiedAdded on 2022/11/11
|9
|1955
|255
Report
AI Summary
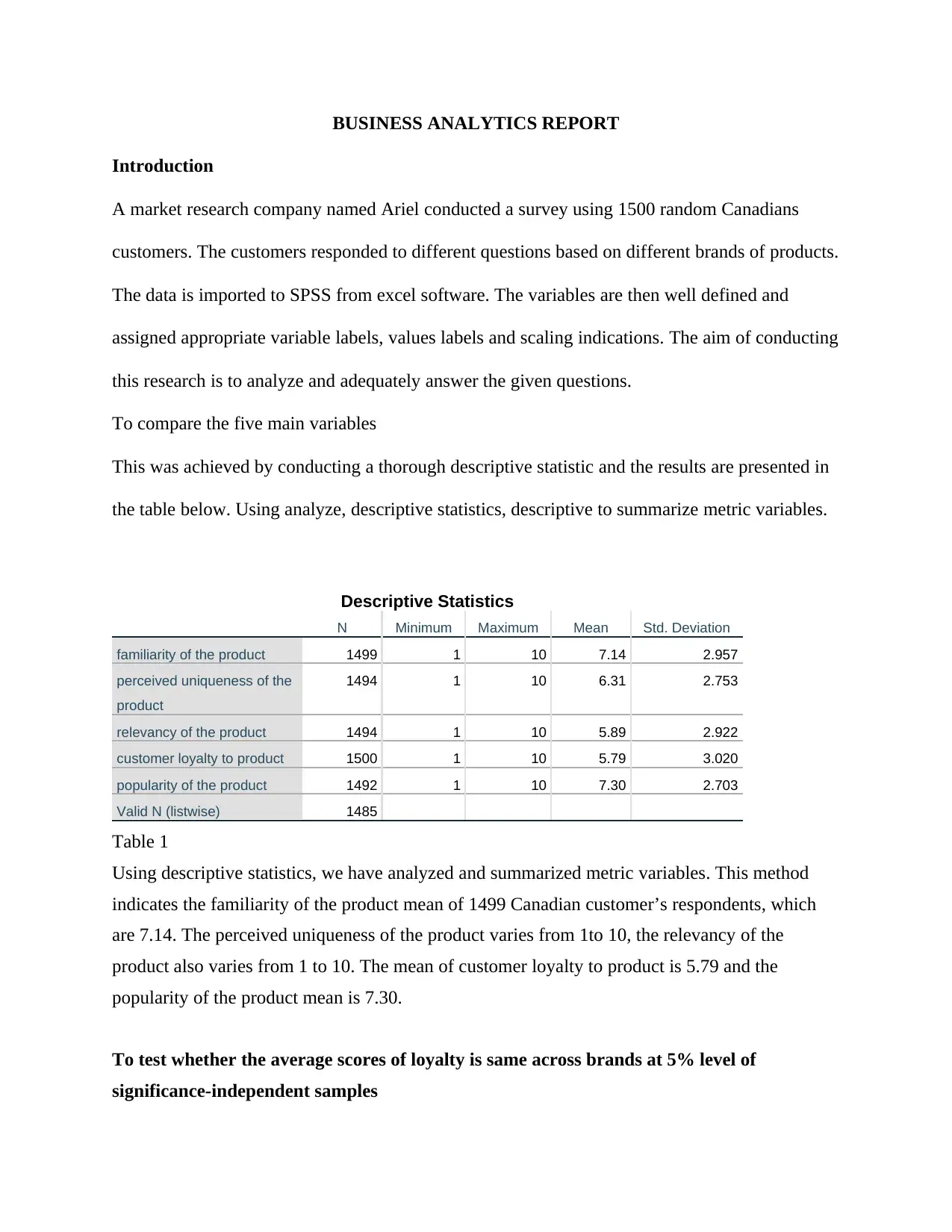
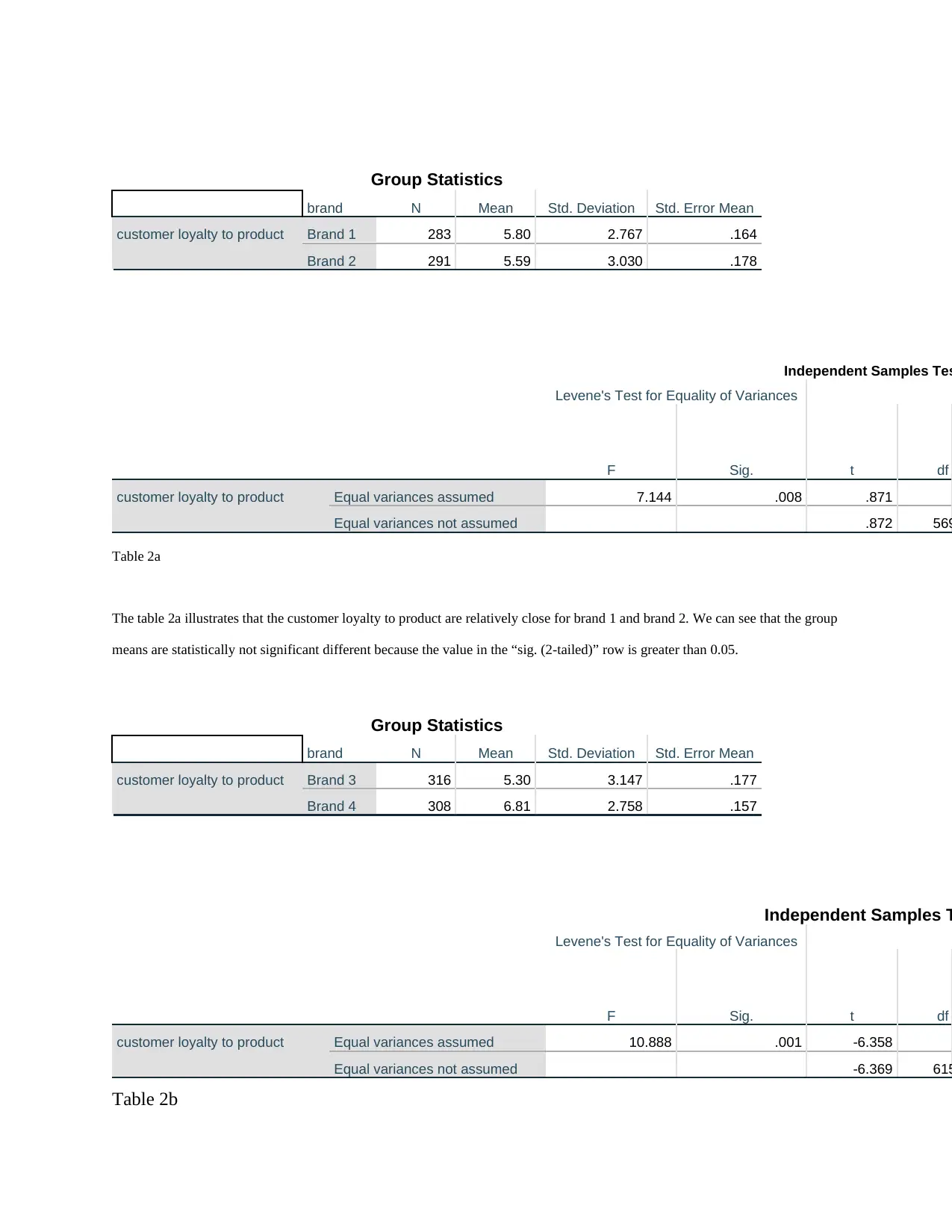
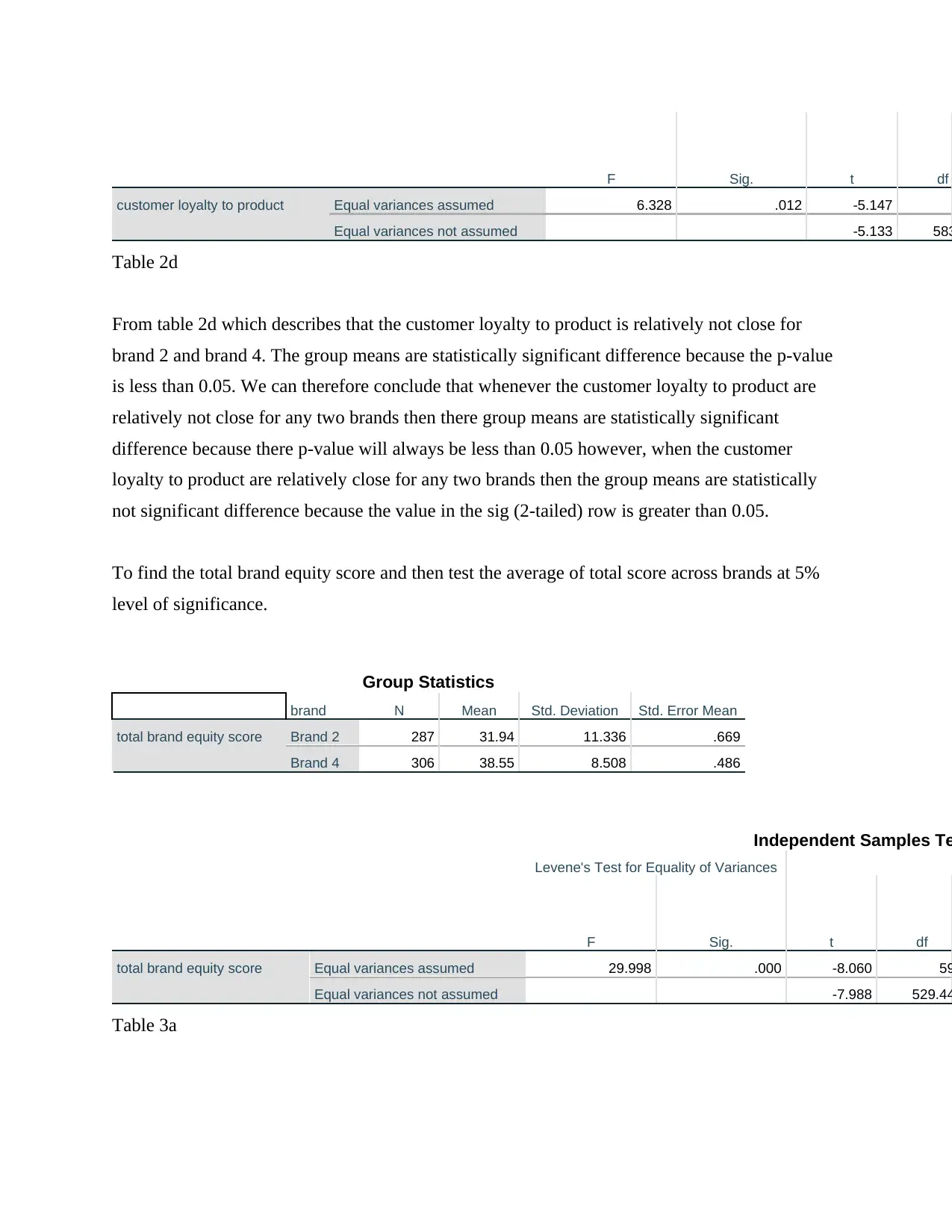
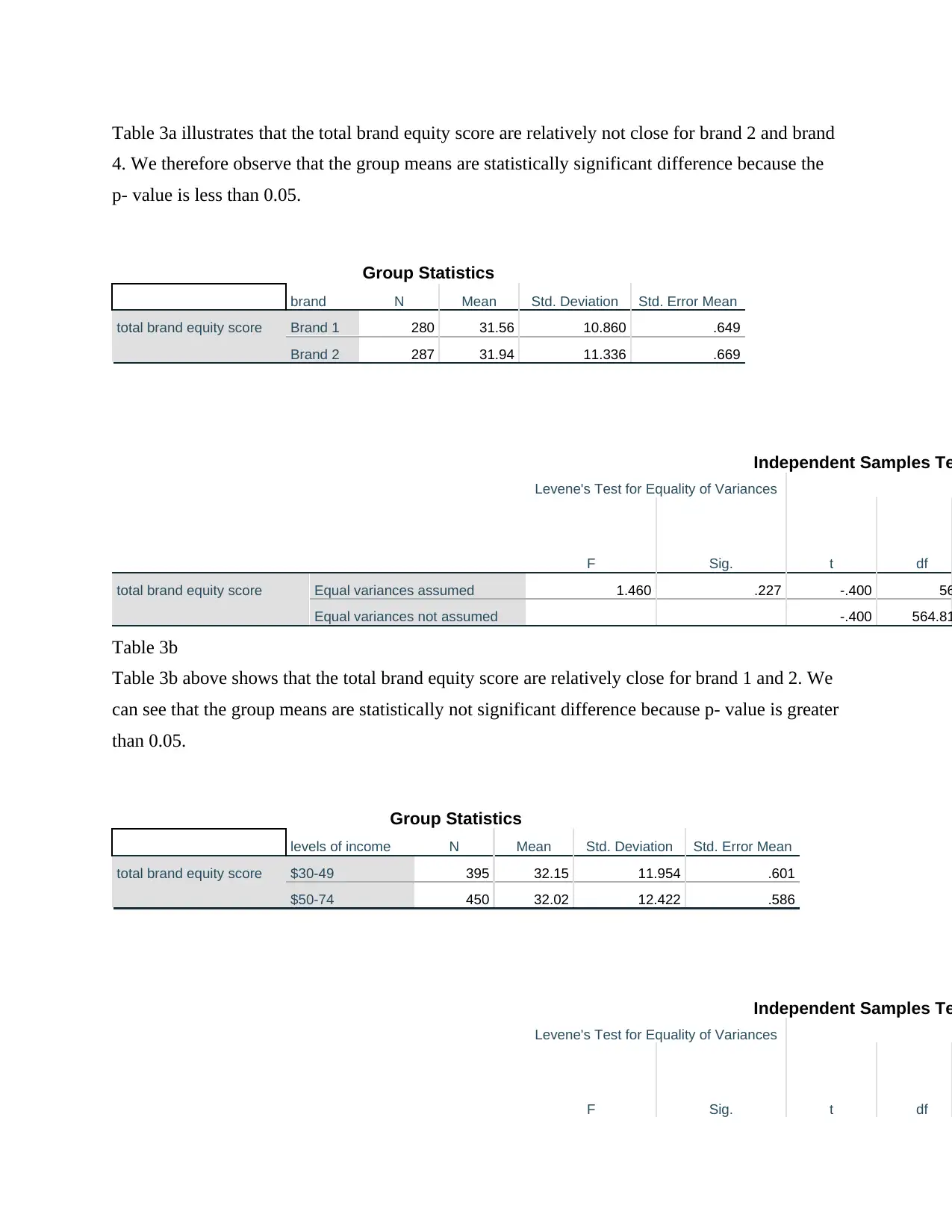
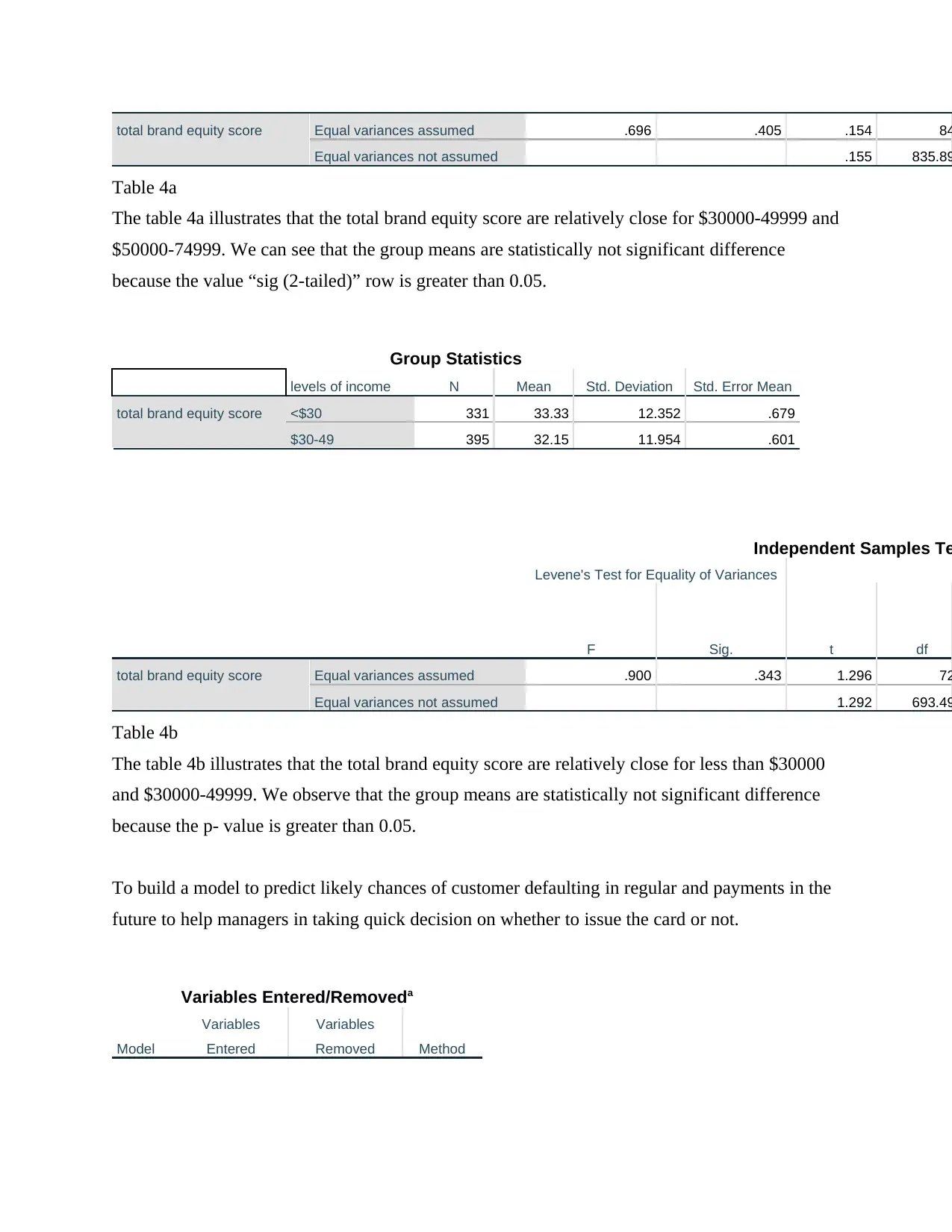
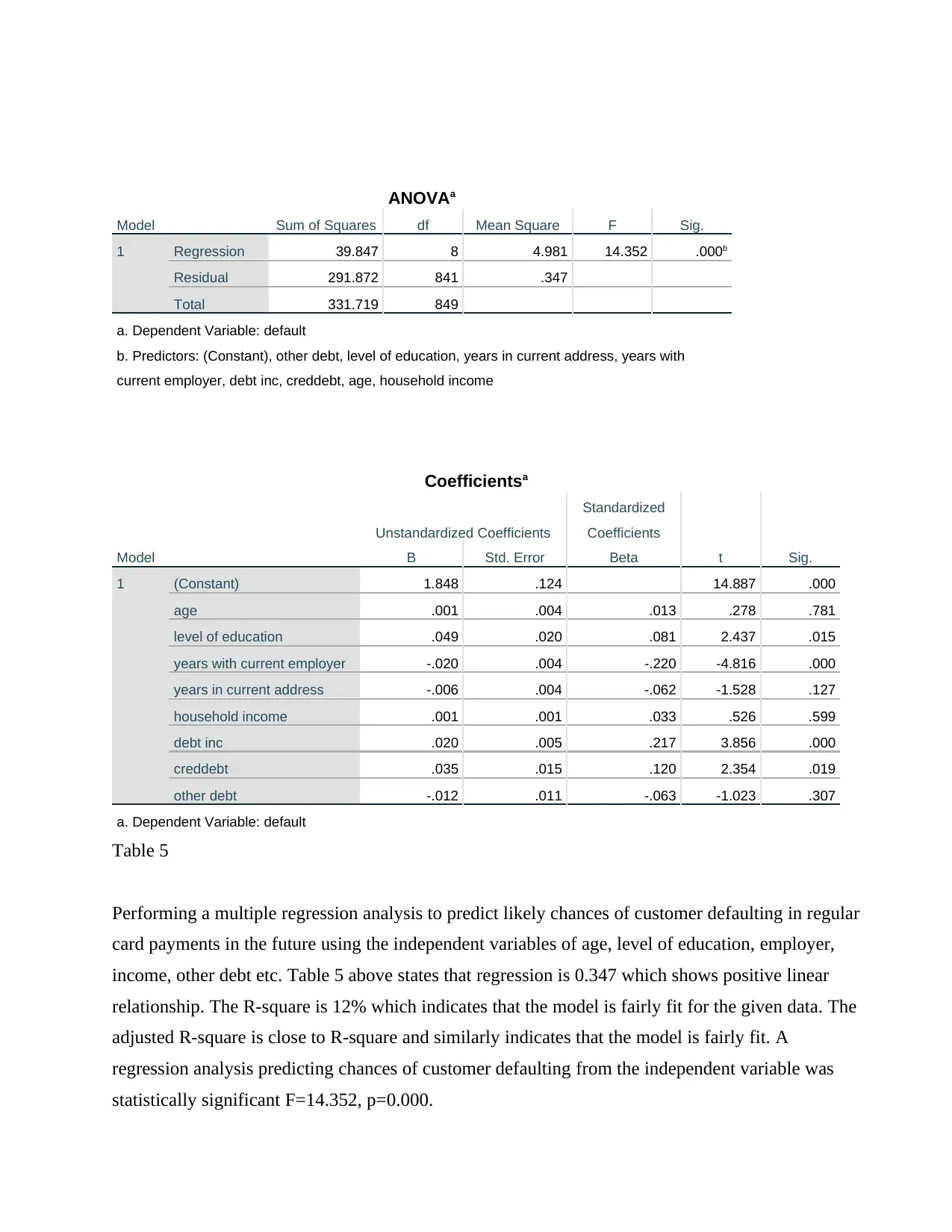
This business analytics report analyzes a dataset from a Canadian customer survey conducted by Ariel Research, focusing on brand equity. The report utilizes SPSS to perform descriptive statistics, t-tests, and multiple regression analysis. It examines key variables such as product familiarity, uniqueness, relevancy, customer loyalty, and product popularity across different brands. The analysis includes comparing customer loyalty across brands using independent samples t-tests, determining the total brand equity score, and testing the average score across brands. Furthermore, the report builds a multiple regression model to predict the likelihood of customer default in regular payments, using variables like age, education, employment history, and debt. The findings offer insights into brand performance, customer behavior, and the factors influencing customer default, providing valuable information for marketing decisions.



1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.