Data Mining: Techniques, Algorithms, and Real-World Applications
VerifiedAdded on 2021/06/14
|18
|2339
|324
Report
AI Summary
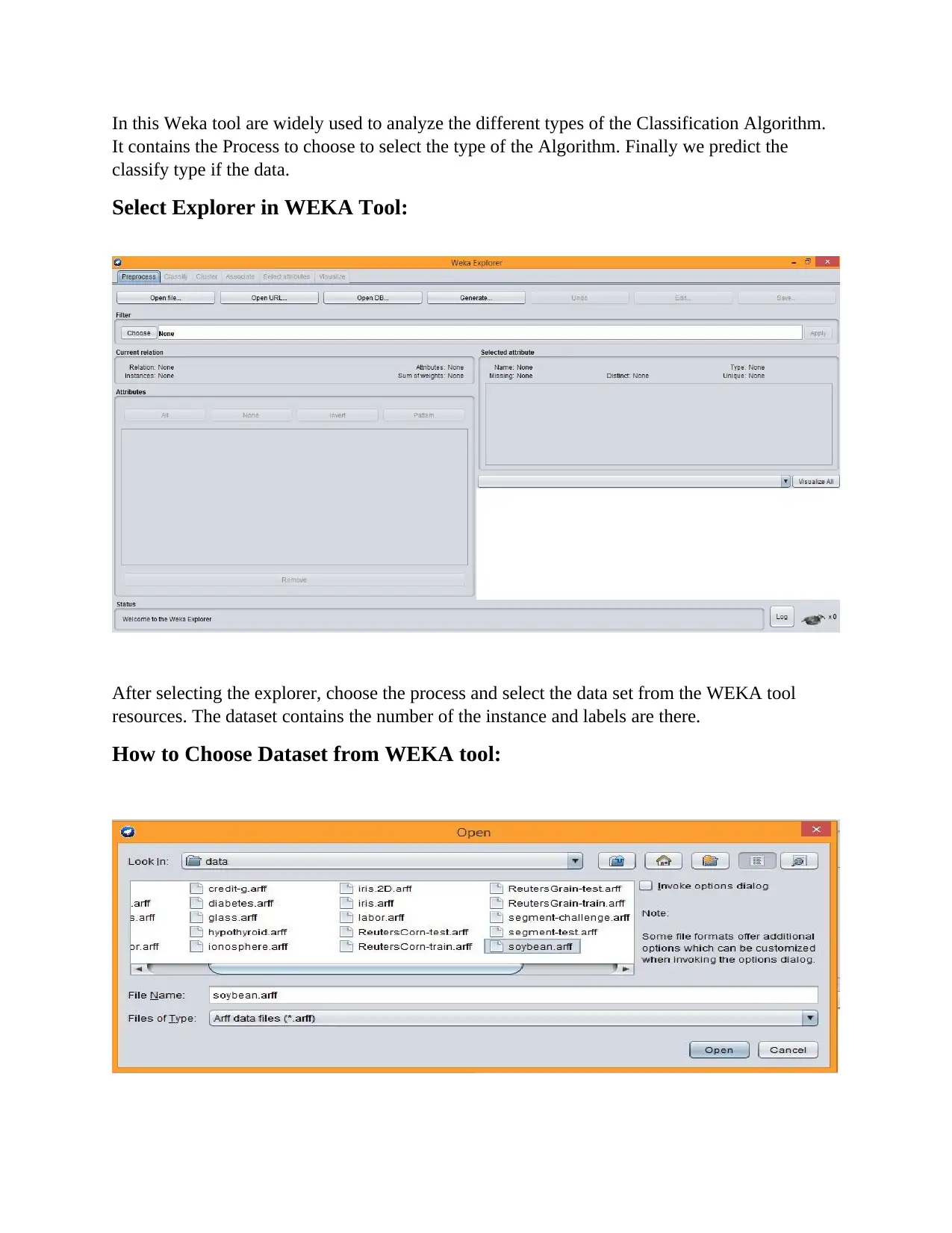
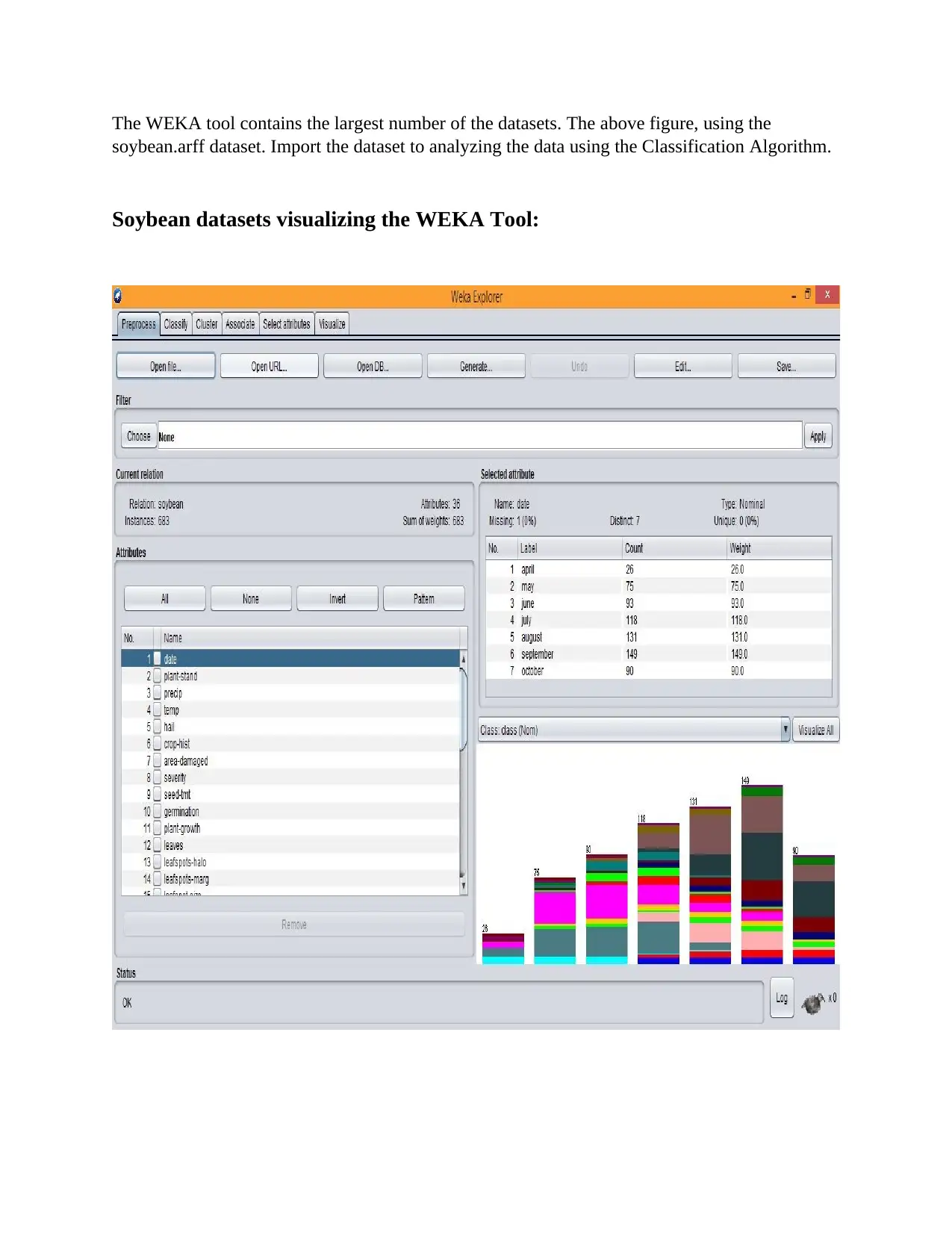
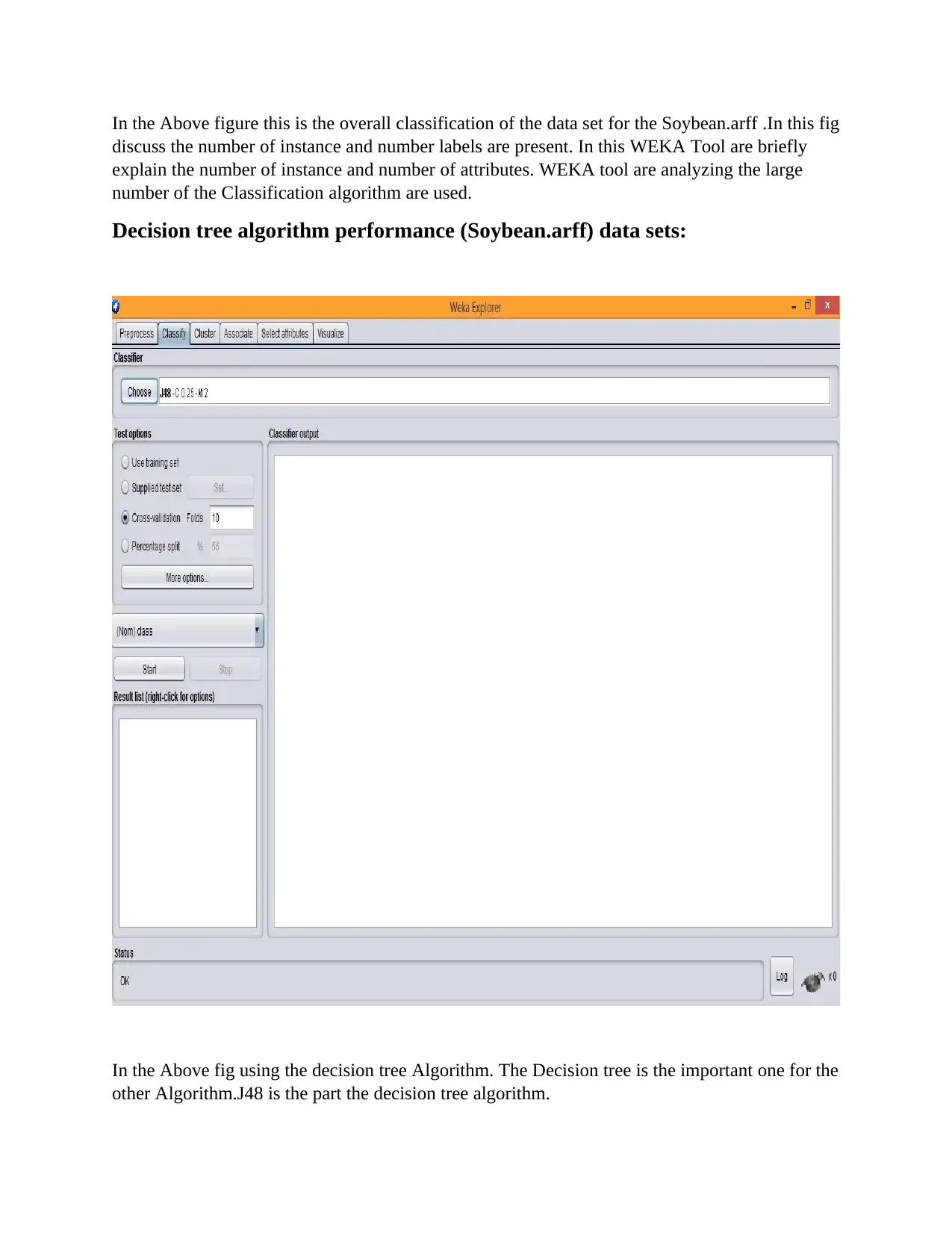
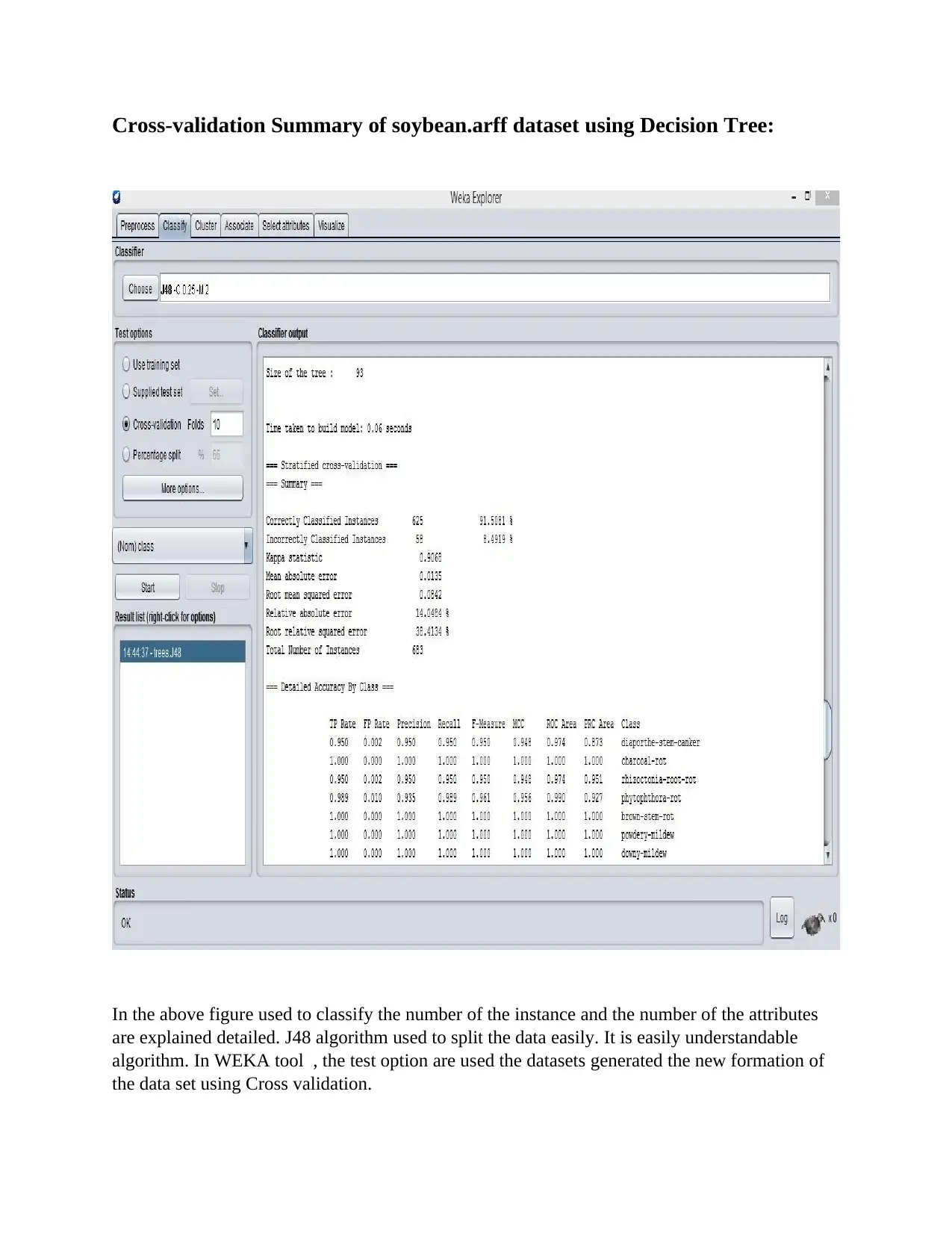
This report provides a comprehensive overview of data mining, beginning with its core objective: extracting valuable information from datasets and transforming it into an understandable format. It delves into the key processes of data mining, including data cleaning, integration, transformation, pattern evaluation, and data presentation. The report highlights the broad scope of data mining, emphasizing its efficiency in handling large datasets, its ability to represent data in logical order, and its utility in deriving classifications. It then categorizes data mining functionalities into descriptive and predictive methods, providing examples of each. The report explores various data mining tools, including R-language, RapidMiner, WEKA, and others, and details various data mining techniques such as statistics, classification, association, outlier detection, clustering, regression, and prediction. It further emphasizes the benefits of data mining, such as discovering information, creating accurate models, and improving decision-making processes. The report then discusses cutting-edge data mining techniques, including real-time examples like NFC technology and Geo-fencing, and outlines various applications of data mining across different domains, such as risk management, fraud detection, and market analysis. A significant portion of the report is dedicated to WEKA analysis, highlighting its role in data mining, the algorithms it supports (classification, association rules, preprocessing, clustering, regression), and its open-source nature. The report examines the Decision Tree, K-Nearest Neighbor, and Naive Bayes algorithms, providing detailed explanations, algorithms, and performance analyses. The report includes an in-depth analysis of the Decision Tree algorithm using the Soybean.arff dataset in WEKA, including cross-validation summaries, confusion matrices, and visualization curves. The report concludes with a performance analysis of the Naive Bayes algorithm using the Soybean dataset. This report provides a solid foundation for understanding data mining techniques and their practical applications.








1 out of 18
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.