Report on Data Mining Techniques: Decision Tree, Naive Bayes, and KNN
VerifiedAdded on 2023/06/05
|9
|1750
|265
Report
AI Summary
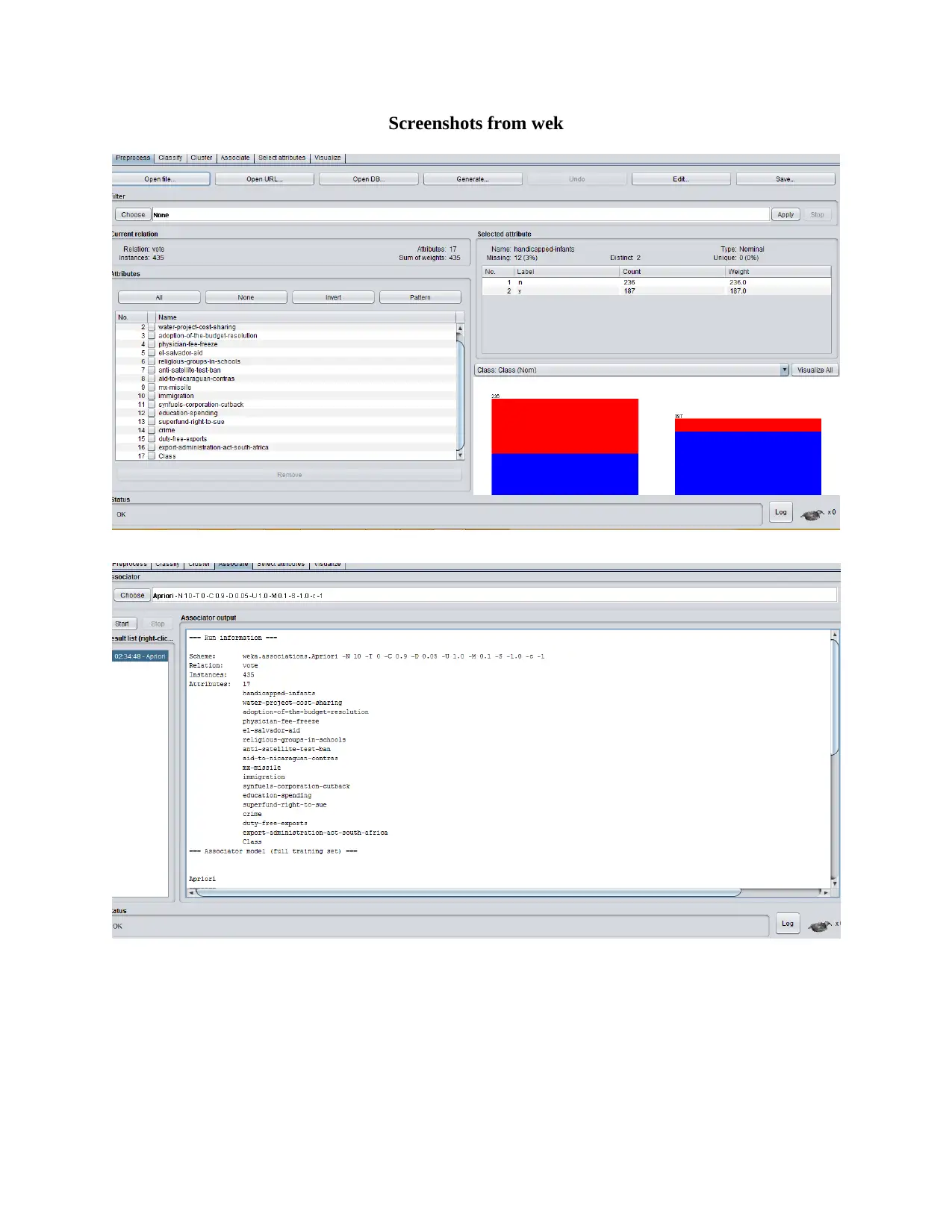
This report provides an analysis of three major data mining techniques: Decision Tree, Naive Bayes, and K-Nearest Neighbor (KNN). It explains how each algorithm works, highlighting their strengths and weaknesses. The Decision Tree algorithm creates a predictive model by learning decision rules from data, while Naive Bayes classifies data based on prior probabilities and conditional probabilities. KNN, a non-parametric method, classifies data points based on the majority class among its nearest neighbors. The report also discusses the use of a confusion matrix for evaluating the performance of classification algorithms, emphasizing its importance in understanding the types of errors made by the classifier. It also presents a comparative analysis of the algorithms' performance, noting the K-nearest neighbor provides more accurate information in comparison to the rest of the algorithms. Screenshots from Weka are included to illustrate the concepts. Desklib offers this and other solved assignments to aid students in their studies.








1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.