Data Modeling in R: Simulation, Probability, and MLE Analysis
VerifiedAdded on 2023/06/14
|20
|3680
|203
Homework Assignment
AI Summary
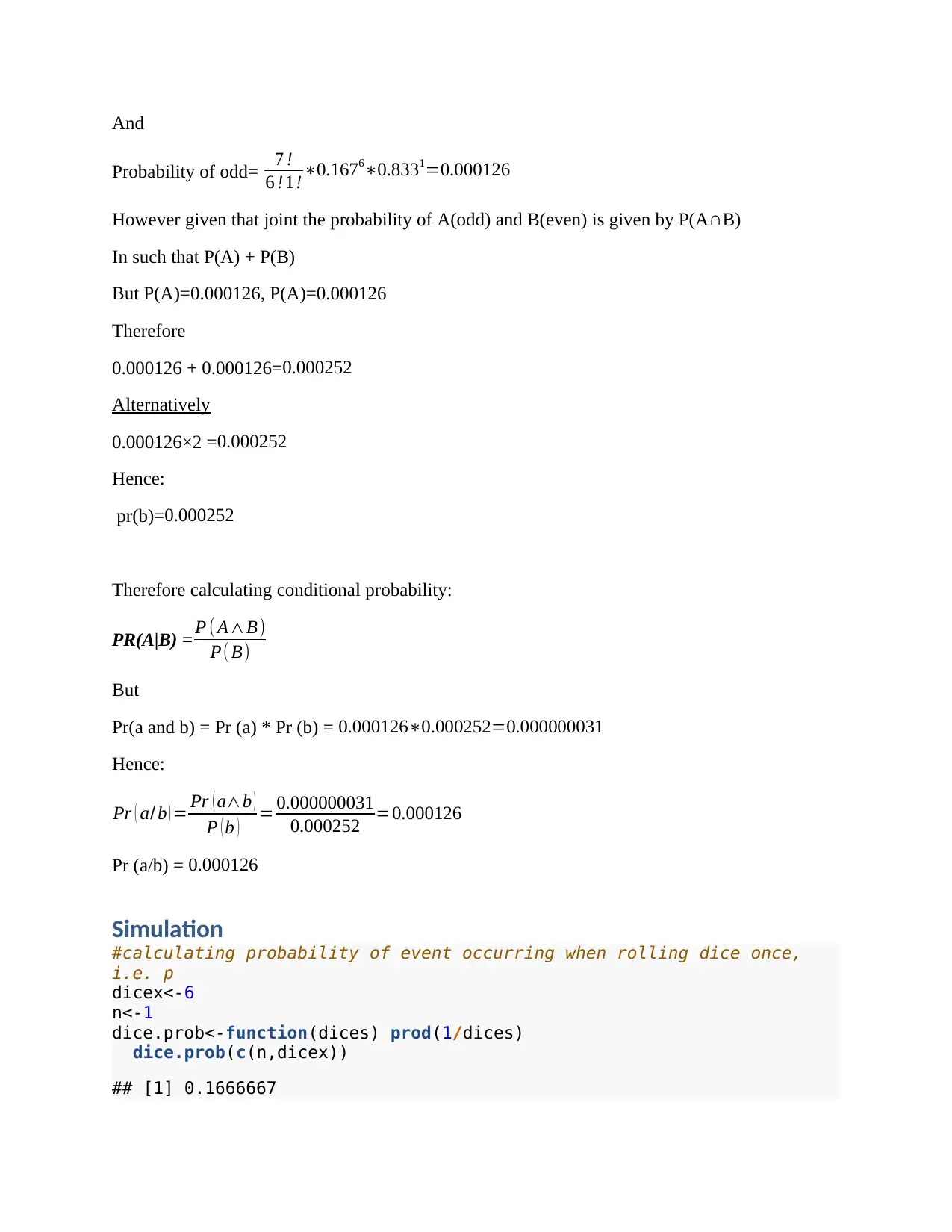
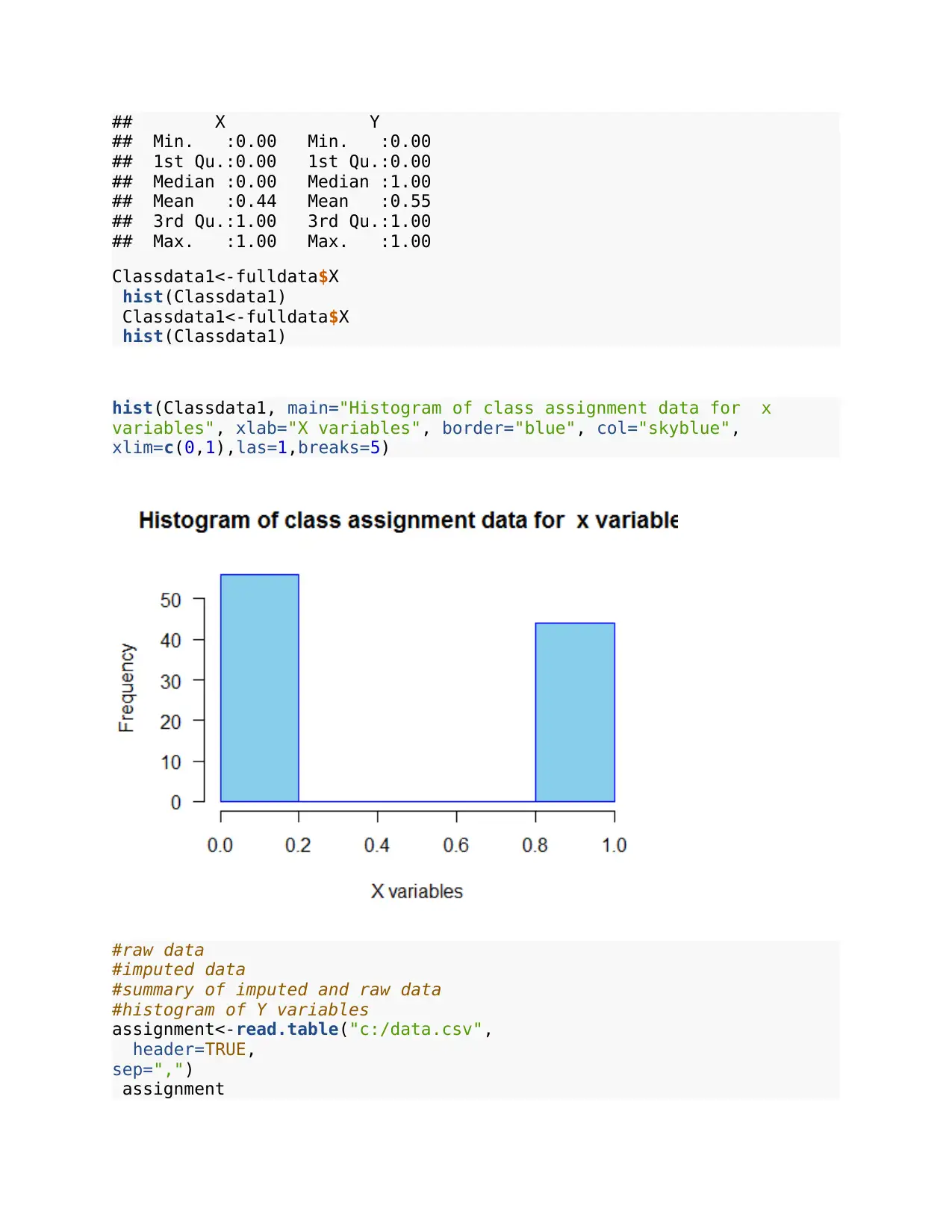
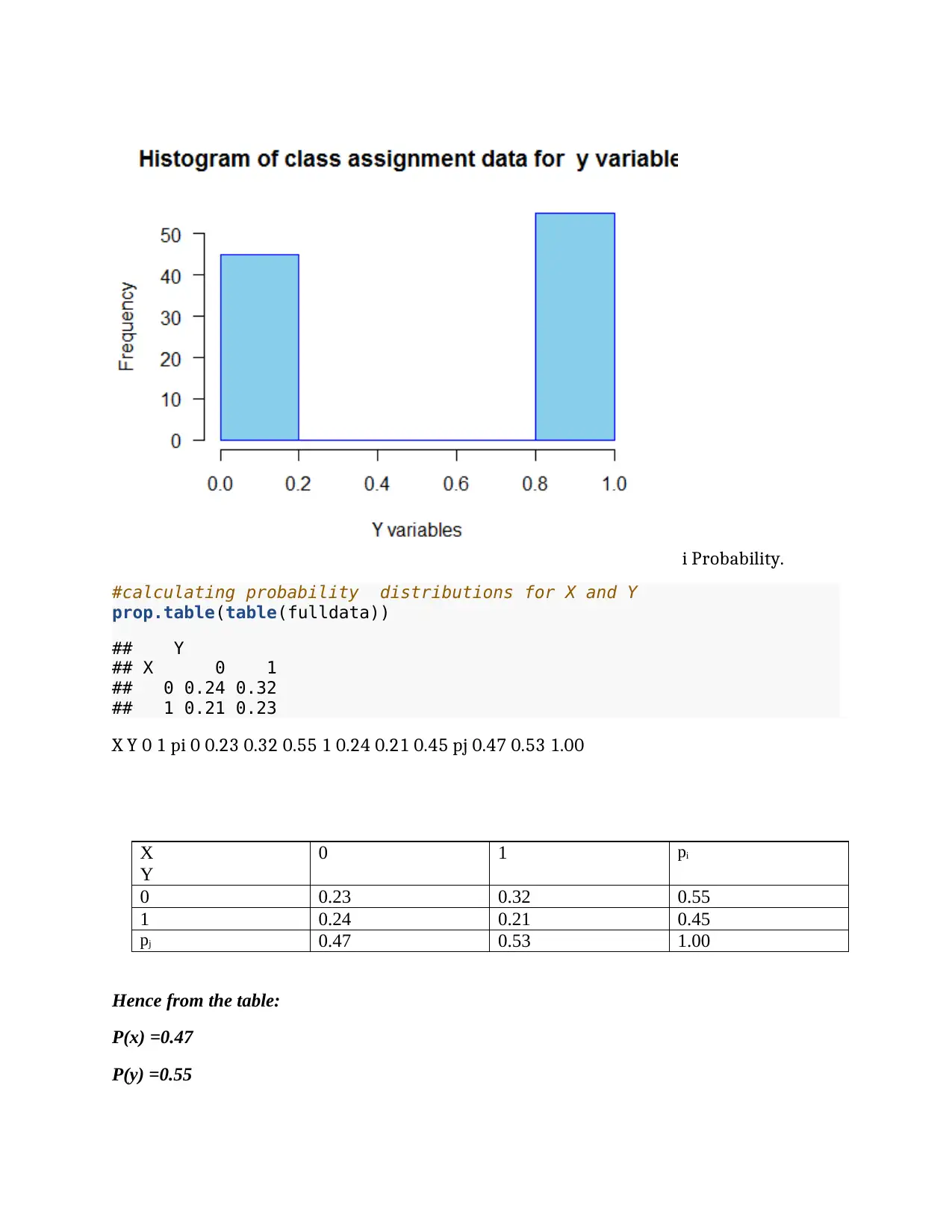
This assignment focuses on data modeling using R, addressing key concepts such as conditional probability, entropy, correlation, maximum likelihood estimation (MLE), and the central limit theorem. The conditional probability question involves calculating the probability of specific events when tossing a fair die, solved both analytically and through simulation. The entropy section deals with handling missing data in a Boolean dataset, calculating probability distributions, and determining entropy for X and Y variables. Correlation and covariance coefficients are explored using Gaussian random variables, with both analytical solutions and simulations. The MLE section focuses on determining the maximum likelihood estimator from a Poisson distribution. Finally, the assignment justifies the central limit theorem using different sample sizes and R code for a normal Poisson distribution. The solutions are supported by R code and detailed explanations.









1 out of 20


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.