Econometrics Assignment: Analyzing Distributions and Regression Models
VerifiedAdded on 2023/01/16
|9
|1116
|32
Homework Assignment
AI Summary
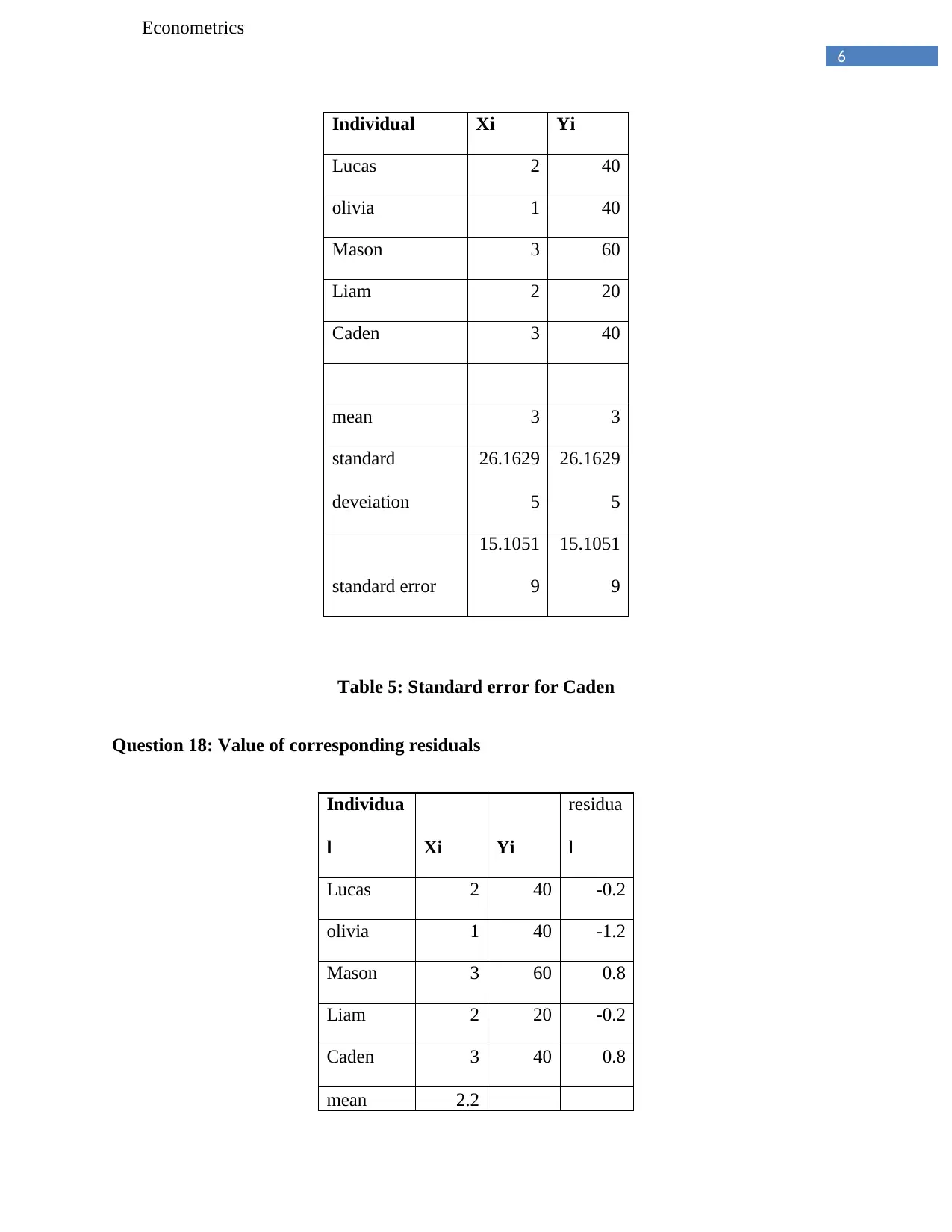
This econometrics assignment explores key concepts in statistical analysis and econometrics, including the calculation of joint and marginal probability distributions, expected values, variance, and covariance. It delves into conditional distributions, population regression lines, and the relationship between population slopes, variance, and covariance. The assignment also examines the relationship between dependent and independent variables, the estimation and comparison of regression equations, and the determination of error terms and residuals. The solution includes detailed calculations, interpretations, and a regression analysis output, providing a comprehensive understanding of the statistical methods applied in the field of econometrics. The assignment covers a range of topics, from basic probability to regression modeling.



1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.