Lamarckian Genetic Algorithm in Neural Networking for Face Detection System
VerifiedAdded on 2023/04/25
|14
|3213
|305
AI Summary
This paper presents an algorithm based on neural network-based system, which has the capability of detecting faces (front view) under gray-scale imaging. The applied methods of training and algorithms are generalized to be applied to recognition problems with respect to different faces, objects, and patterns. The system's performance had also been examined, and results were suitably eminent to signify the importance of the system. The study is concluded along with the future scope of further research.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.
LAMARCKIAN GENETIC ALGORITHM IN NEURAL NETWORKING
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

LAMARCKIAN GENETIC ALGORITHM IN NEURAL NETWORKING
Face Detection System-based on Neural Network
Name of the Student:
Name of the University:
Author Note
Table of Content
[DATE]
[Company name]
[Company address]
Face Detection System-based on Neural Network
Name of the Student:
Name of the University:
Author Note
Table of Content
[DATE]
[Company name]
[Company address]

1ReferencesReferences
s
Introduction................................................................................................................................3
Background................................................................................................................................3
Discussion..................................................................................................................................4
Stage 1:...................................................................................................................................4
Stage 2:...................................................................................................................................7
Testing and Results....................................................................................................................7
Conclusion and Future Work...................................................................................................10
References................................................................................................................................12
s
Introduction................................................................................................................................3
Background................................................................................................................................3
Discussion..................................................................................................................................4
Stage 1:...................................................................................................................................4
Stage 2:...................................................................................................................................7
Testing and Results....................................................................................................................7
Conclusion and Future Work...................................................................................................10
References................................................................................................................................12

2ReferencesReferences
Introduction
Training of a neural network for the task of detecting faces is considered to be a
challenging task, mostly due to the complexity and hardships during recognition of ‘non-
facial’ image prototypes. Face recognition simply implements discrimination of alike faces
among two classes, thus, spotting ‘facial images’ to ‘non-facial images’. Collecting
representative image samples (containing faces) is easy, however, it is hard to detect the ones
which does not have any. The training set’s size in the next class has been observed to grow
rapidly.
Thus, the following paper is aimed to present an algorithm based on neural network-
based system, which has the capability of detecting faces (front view) under gray-scale
imaging (Ronao & Cho 2016). The applied methods of training and algorithms are
generalized to be applied to recognition problems with respect to different faces, objects and
patterns, also. The following work is carried out, under specific avoidance of massive training
set usage; thus, the only selected images were added to the training set during the
progression. Moreover, the training methods are described (with network architecture) in the
Discussion section. Also, the system’s performance had also been examined, and results were
suitably eminent to signify the importance of the system (Results and Testing). Additionally,
the system is also described in an extended manner for better understanding. Lastly, the study
is concluded along with the future scope of further research.
Background
Facing recognition is based on the ground of image processing using any machinery
language, such as python, MATLAB and more. However, primarily the idea of image
processing is required to be understood to continue further with the study. Image processing
is defined as the procedure for conversion of an image file into a digitalized format, and also
Introduction
Training of a neural network for the task of detecting faces is considered to be a
challenging task, mostly due to the complexity and hardships during recognition of ‘non-
facial’ image prototypes. Face recognition simply implements discrimination of alike faces
among two classes, thus, spotting ‘facial images’ to ‘non-facial images’. Collecting
representative image samples (containing faces) is easy, however, it is hard to detect the ones
which does not have any. The training set’s size in the next class has been observed to grow
rapidly.
Thus, the following paper is aimed to present an algorithm based on neural network-
based system, which has the capability of detecting faces (front view) under gray-scale
imaging (Ronao & Cho 2016). The applied methods of training and algorithms are
generalized to be applied to recognition problems with respect to different faces, objects and
patterns, also. The following work is carried out, under specific avoidance of massive training
set usage; thus, the only selected images were added to the training set during the
progression. Moreover, the training methods are described (with network architecture) in the
Discussion section. Also, the system’s performance had also been examined, and results were
suitably eminent to signify the importance of the system (Results and Testing). Additionally,
the system is also described in an extended manner for better understanding. Lastly, the study
is concluded along with the future scope of further research.
Background
Facing recognition is based on the ground of image processing using any machinery
language, such as python, MATLAB and more. However, primarily the idea of image
processing is required to be understood to continue further with the study. Image processing
is defined as the procedure for conversion of an image file into a digitalized format, and also
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

3ReferencesReferences
extending the features by performing external operations for extracting useful information
from the questioned image file (Yang et al. 2017). Examples of such files include
photographs, video frames or any output associated to images (Parkhi, Vedaldi & Zisserman
2015). Image processing treats images by differentiating two-dimensional signals, during the
implementation of set signal processing procedures. The major purpose of the image
processing are visualization, image retrieval, image restoration and sharpening, image
recognition and pattern measurement (Sun 2015). Here, neural network plays a vital part for
easy execution of image processing methods. The aimed objective of the neural network is
primarily the elimination of vector-designing in a manual procedures (by hand). Net (Hu et
al. 2015) is the mimic of brain’s working which designates the system through appropriate
extraction of features (automatically), according to the relevancy. The recorded highlights of
the net are currently observed to be in Convolutions (Yang et al. 2017), Locally Connected
Networks (He et al. 2016) and Pooling (Sutskever, Vinyals & Le 2014).
Discussion
The following system’s operation is observed to be undertaken under two stages.
Firstly, image receives a set of filters (neural network-based), and next authorizes the filter
outputs. The examination of the located images at multiple scales are executed by the filter,
which trace a face. Merging of individual filters are merged and detected by the arbitrator,
and further overlapping issues are eliminated.
Stage 1:
Starting component is a filter which takes 20x20 pixel out of an image, and produces
output from 1 to -1 range (1=present of face, -1=absent of face). The same filter is distributed
in every portion of the image. The filter’s algorithm is shown in the following figure.
extending the features by performing external operations for extracting useful information
from the questioned image file (Yang et al. 2017). Examples of such files include
photographs, video frames or any output associated to images (Parkhi, Vedaldi & Zisserman
2015). Image processing treats images by differentiating two-dimensional signals, during the
implementation of set signal processing procedures. The major purpose of the image
processing are visualization, image retrieval, image restoration and sharpening, image
recognition and pattern measurement (Sun 2015). Here, neural network plays a vital part for
easy execution of image processing methods. The aimed objective of the neural network is
primarily the elimination of vector-designing in a manual procedures (by hand). Net (Hu et
al. 2015) is the mimic of brain’s working which designates the system through appropriate
extraction of features (automatically), according to the relevancy. The recorded highlights of
the net are currently observed to be in Convolutions (Yang et al. 2017), Locally Connected
Networks (He et al. 2016) and Pooling (Sutskever, Vinyals & Le 2014).
Discussion
The following system’s operation is observed to be undertaken under two stages.
Firstly, image receives a set of filters (neural network-based), and next authorizes the filter
outputs. The examination of the located images at multiple scales are executed by the filter,
which trace a face. Merging of individual filters are merged and detected by the arbitrator,
and further overlapping issues are eliminated.
Stage 1:
Starting component is a filter which takes 20x20 pixel out of an image, and produces
output from 1 to -1 range (1=present of face, -1=absent of face). The same filter is distributed
in every portion of the image. The filter’s algorithm is shown in the following figure.

4ReferencesReferences
Fig 1: Face detection (basic algorithm)
(Source: Author)
Adapted pre-processing step (Juell & Marsh 1996) is firstly evaluated to the image window.
Then, window passes through the neural network, deciding to spot a face in the window.
Externally located pixels (outside of oval), are subjected to represent the background, with
varying intensity and lighting than those across the face. Afterwards, histogram equalization
is initiated to perform the mapping and expansion of intensity values. This generally
compensates the separation in gains of the camera’s input and promotes the contrast (in few
cases).
After passing through neural network, the network sends retinal connections to the
layer of the input as hidden units (Figure 1). The types of hidden units are: 6 on overlapping
20*5 horizontally striped pixel, 16 on 5*5 sub-regional pixels and 4 on 10*10 sub-regional
pixel. These allow representation of localized characteristics of face detection.
For the checking, exactly 1050 faces were collected from different universities
including Harvard and CMU. The images had different shapes, orientation and no similarities
in facial features. The scaling of the individual face’s eyes and upper lip’s centre was traced
manually as:
Fig 1: Face detection (basic algorithm)
(Source: Author)
Adapted pre-processing step (Juell & Marsh 1996) is firstly evaluated to the image window.
Then, window passes through the neural network, deciding to spot a face in the window.
Externally located pixels (outside of oval), are subjected to represent the background, with
varying intensity and lighting than those across the face. Afterwards, histogram equalization
is initiated to perform the mapping and expansion of intensity values. This generally
compensates the separation in gains of the camera’s input and promotes the contrast (in few
cases).
After passing through neural network, the network sends retinal connections to the
layer of the input as hidden units (Figure 1). The types of hidden units are: 6 on overlapping
20*5 horizontally striped pixel, 16 on 5*5 sub-regional pixels and 4 on 10*10 sub-regional
pixel. These allow representation of localized characteristics of face detection.
For the checking, exactly 1050 faces were collected from different universities
including Harvard and CMU. The images had different shapes, orientation and no similarities
in facial features. The scaling of the individual face’s eyes and upper lip’s centre was traced
manually as:

5ReferencesReferences
1. Rotation of image to make visibility of eye (horizontally).
2. Scaling the image to maintain distance from upper lip to eye by 13 pixels.
3. Extraction of a 20x20 pixel section and, centre location just a pixel above
upper lip and eye point.
In the set of training, 16 facial examples were extracted from the original sources, under
random rotation of images within 90-112% scaling, signifying half of a pixel and mirroring.
Individual 20x20 window were pre-processed through the processes of histogram
equalization and lighting correction. Moreover, collection of small yet relatable sets of non-
facial images was a difficult task. Thus, images were collected and executed during the
training through the steps of (ideas adapted from Yang et al. 2015) -
1. Creation of 1000 random non-facial images with different intensities of pixels,
and pre-processing was also applied. Neural network was also adapted to
produce outputs of 1 to -1 (as stated before). The applied algorithm induced
error-backpropagation methods (Haddadnia & Ahmadi 2004).
2. Execution of the system were run on a non-face scenic image. Further, sub-
images were collected, where the error of network identifying a face was
detected (output>0).
3. Also, selection of 250+ sub-images were evaluated randomly to be applied in
the pre-processing periods, to initiate addition to the negative examples in the
training sets. Then, go to step 2.
Moreover, 120 images with different scenario were used for the collection of negative
illustrations in the bootstrap method. Regular training run selected exact number of 8000
unrecognized non-facial images from 145,213,120 sub-images, which were available in all
scales and locations of the set.
1. Rotation of image to make visibility of eye (horizontally).
2. Scaling the image to maintain distance from upper lip to eye by 13 pixels.
3. Extraction of a 20x20 pixel section and, centre location just a pixel above
upper lip and eye point.
In the set of training, 16 facial examples were extracted from the original sources, under
random rotation of images within 90-112% scaling, signifying half of a pixel and mirroring.
Individual 20x20 window were pre-processed through the processes of histogram
equalization and lighting correction. Moreover, collection of small yet relatable sets of non-
facial images was a difficult task. Thus, images were collected and executed during the
training through the steps of (ideas adapted from Yang et al. 2015) -
1. Creation of 1000 random non-facial images with different intensities of pixels,
and pre-processing was also applied. Neural network was also adapted to
produce outputs of 1 to -1 (as stated before). The applied algorithm induced
error-backpropagation methods (Haddadnia & Ahmadi 2004).
2. Execution of the system were run on a non-face scenic image. Further, sub-
images were collected, where the error of network identifying a face was
detected (output>0).
3. Also, selection of 250+ sub-images were evaluated randomly to be applied in
the pre-processing periods, to initiate addition to the negative examples in the
training sets. Then, go to step 2.
Moreover, 120 images with different scenario were used for the collection of negative
illustrations in the bootstrap method. Regular training run selected exact number of 8000
unrecognized non-facial images from 145,213,120 sub-images, which were available in all
scales and locations of the set.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

6ReferencesReferences
Stage 2:
The above discussion in Stage 1 (under single neural network) was observed to
produce false detections in some periods. Thus, following techniques were subjected to
mitigate the errors. Extended details on the same stage can be found on the reference material
of Mollahosseini, Chan & Mahoor (2016).
Due to the little amount of scale and position in the filter, authentic faces are mostly
recognized under nearby multiple scales and positions, whereas untrue detections only were
spotted at an individual position. Thus, maintaining an optimized threshold during the
detections, false detections were seen to be eliminated. The rare fact of image-overlapping is
the second heuristic. Overlapping of one detection with another could be mitigated through
the optimization of confidence of the detection.
During the evaluation of the training, similar networks under un-identical predefined
weights (Schmidhuber 2015) would choose alike sets of pessimistic examples, which would
make different errors with alike biases. Thus, the system can be exploited through arbitrating
the multiple network’s outputs. For example, when two networks approve that a face is
recognized, then only a signal is detected.
Testing and Results
Three massive sets of images in the following experiment indicated the versatility of
results. First Set was from CMU, and consisted of 40 scanned newspaper pictures, photos,
images gathered through World Wide Web and other sources. The images consisted of 170
front views (containing faces), which made the network examine 22,074 20x20 windows.
Second set consisted of 25 images showing 155 faces (9, 36,223 windows). Third set was
Stage 2:
The above discussion in Stage 1 (under single neural network) was observed to
produce false detections in some periods. Thus, following techniques were subjected to
mitigate the errors. Extended details on the same stage can be found on the reference material
of Mollahosseini, Chan & Mahoor (2016).
Due to the little amount of scale and position in the filter, authentic faces are mostly
recognized under nearby multiple scales and positions, whereas untrue detections only were
spotted at an individual position. Thus, maintaining an optimized threshold during the
detections, false detections were seen to be eliminated. The rare fact of image-overlapping is
the second heuristic. Overlapping of one detection with another could be mitigated through
the optimization of confidence of the detection.
During the evaluation of the training, similar networks under un-identical predefined
weights (Schmidhuber 2015) would choose alike sets of pessimistic examples, which would
make different errors with alike biases. Thus, the system can be exploited through arbitrating
the multiple network’s outputs. For example, when two networks approve that a face is
recognized, then only a signal is detected.
Testing and Results
Three massive sets of images in the following experiment indicated the versatility of
results. First Set was from CMU, and consisted of 40 scanned newspaper pictures, photos,
images gathered through World Wide Web and other sources. The images consisted of 170
front views (containing faces), which made the network examine 22,074 20x20 windows.
Second set consisted of 25 images showing 155 faces (9, 36,223 windows). Third set was
7ReferencesReferences
similar to first set, however contained more complex images with more or no faces and
complicated background. It consisted of 68 images, 185 faces and 51, 328, 003 windows.
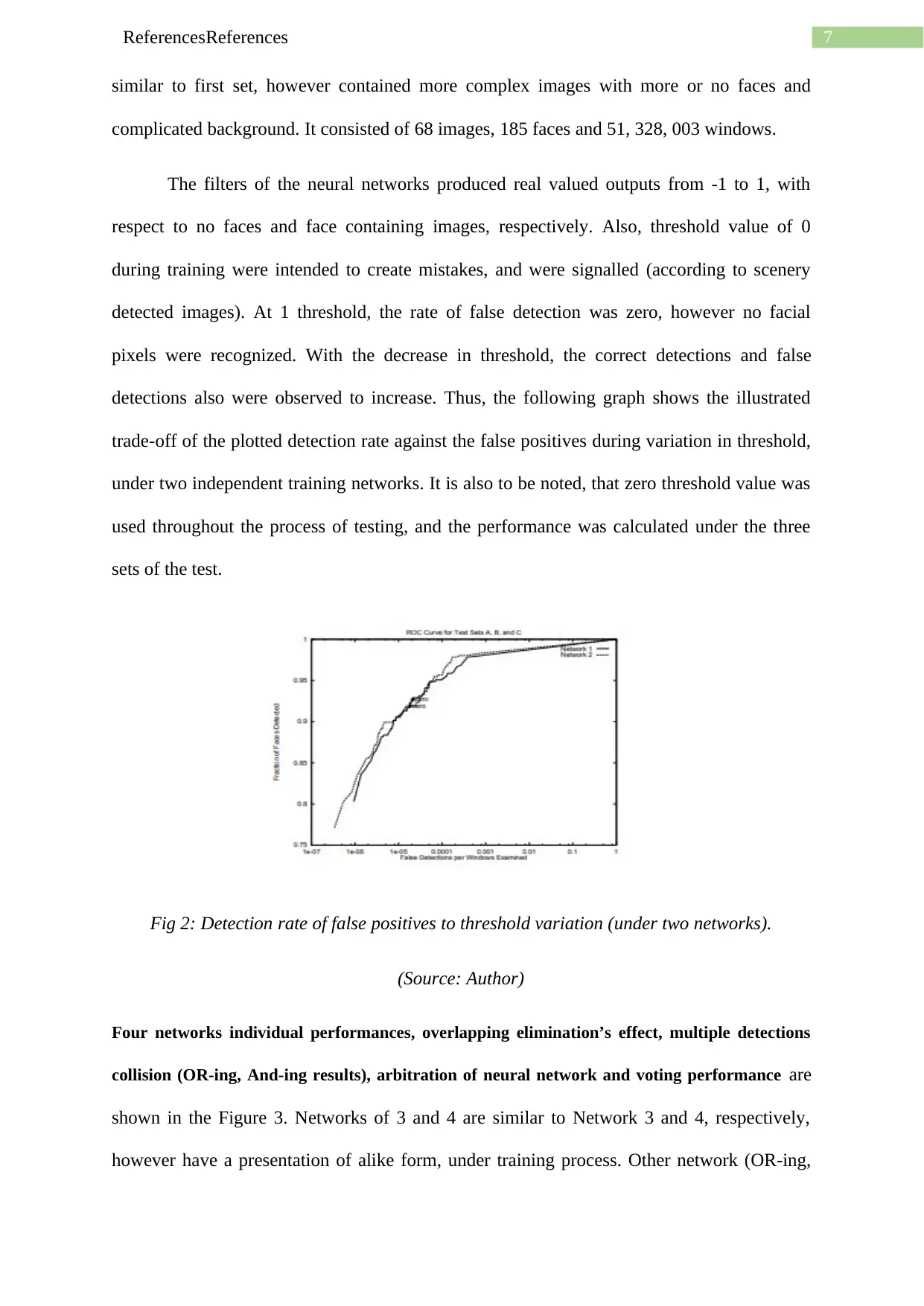
The filters of the neural networks produced real valued outputs from -1 to 1, with
respect to no faces and face containing images, respectively. Also, threshold value of 0
during training were intended to create mistakes, and were signalled (according to scenery
detected images). At 1 threshold, the rate of false detection was zero, however no facial
pixels were recognized. With the decrease in threshold, the correct detections and false
detections also were observed to increase. Thus, the following graph shows the illustrated
trade-off of the plotted detection rate against the false positives during variation in threshold,
under two independent training networks. It is also to be noted, that zero threshold value was
used throughout the process of testing, and the performance was calculated under the three
sets of the test.
Fig 2: Detection rate of false positives to threshold variation (under two networks).
(Source: Author)
Four networks individual performances, overlapping elimination’s effect, multiple detections
collision (OR-ing, And-ing results), arbitration of neural network and voting performance are
shown in the Figure 3. Networks of 3 and 4 are similar to Network 3 and 4, respectively,
however have a presentation of alike form, under training process. Other network (OR-ing,
similar to first set, however contained more complex images with more or no faces and
complicated background. It consisted of 68 images, 185 faces and 51, 328, 003 windows.
The filters of the neural networks produced real valued outputs from -1 to 1, with
respect to no faces and face containing images, respectively. Also, threshold value of 0
during training were intended to create mistakes, and were signalled (according to scenery
detected images). At 1 threshold, the rate of false detection was zero, however no facial
pixels were recognized. With the decrease in threshold, the correct detections and false
detections also were observed to increase. Thus, the following graph shows the illustrated
trade-off of the plotted detection rate against the false positives during variation in threshold,
under two independent training networks. It is also to be noted, that zero threshold value was
used throughout the process of testing, and the performance was calculated under the three
sets of the test.
Fig 2: Detection rate of false positives to threshold variation (under two networks).
(Source: Author)
Four networks individual performances, overlapping elimination’s effect, multiple detections
collision (OR-ing, And-ing results), arbitration of neural network and voting performance are
shown in the Figure 3. Networks of 3 and 4 are similar to Network 3 and 4, respectively,
however have a presentation of alike form, under training process. Other network (OR-ing,

8ReferencesReferences
And-ing results) is based on 1 and 2, while performance in voting were depended upon 1, 2
and 3. Total face correct and false detection percentage for all three sets are also provided in
the table. Aitkenheld and McDonalds (2003) illustrates of the performance’s breakdown for
an individual system inside the three sets, also provides the system performance under
arbitrary neural networks in the multi-detected networks.
Table 1: Rates of error and detection for Three Test Sets
(Source: Author)
The pure performance of the networks are shown in system 1 to 4. Systems of 3 to 8 utilize
similar networks, while thresholding and other steps might degrade the falsely detected
counts in a significant manner, under the expense of fake recognition rate. Other systems use
the arbitration among multi-networks. Low range of fake detection of windows produce
extremely less rate of 1 fake recognition per 231,054 windows to 1 in 12,143,212, under the
arbitration usage. 10, 11, 12- numbered systems show the tune of the system in a conservative
manner. Also, System 10 was calculated had low false positives and detected level was
around 79%. System 12 has higher rate of 91% (under OR-ing) but high false positives, while
system 11 is a compromised layer between the former two. The strategy of the arbitration has
made the difference in the system performances. During the use in AND-ing, the suppression
of false detection in an individual network was detected, whereas OR-ing produced correct
And-ing results) is based on 1 and 2, while performance in voting were depended upon 1, 2
and 3. Total face correct and false detection percentage for all three sets are also provided in
the table. Aitkenheld and McDonalds (2003) illustrates of the performance’s breakdown for
an individual system inside the three sets, also provides the system performance under
arbitrary neural networks in the multi-detected networks.
Table 1: Rates of error and detection for Three Test Sets
(Source: Author)
The pure performance of the networks are shown in system 1 to 4. Systems of 3 to 8 utilize
similar networks, while thresholding and other steps might degrade the falsely detected
counts in a significant manner, under the expense of fake recognition rate. Other systems use
the arbitration among multi-networks. Low range of fake detection of windows produce
extremely less rate of 1 fake recognition per 231,054 windows to 1 in 12,143,212, under the
arbitration usage. 10, 11, 12- numbered systems show the tune of the system in a conservative
manner. Also, System 10 was calculated had low false positives and detected level was
around 79%. System 12 has higher rate of 91% (under OR-ing) but high false positives, while
system 11 is a compromised layer between the former two. The strategy of the arbitration has
made the difference in the system performances. During the use in AND-ing, the suppression
of false detection in an individual network was detected, whereas OR-ing produced correct
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

9ReferencesReferences
face detection while the individual network was preserved and producing improvement in the
detection levels. The voting range was yielded equal rates of correct and false positive
detections for system 12 by the system 13.
The above Table 1 concluded with the System 11’s reasonable performance in trade-
off under the circumstances of detection rate and incorrect detections. The average detection
rage was 86% of correct faces, and average each false detection per 1,130,012 20x20
windowed pixels. The extracted (output) images from System 11 are shown in the Figure 3.
Figure 3: Output images from System 11 (shown in Table 1).
(Source: Author)
Conclusion and Future Work
The algorithm was capable of detecting 79-91% of faces in 140 sets of test images,
with considerable number of fake detections. Based on the evaluation, the conservativeness
of the system is sufficient to vary the arbitrated heuristics and thresholds usage. Variety of
face detection while the individual network was preserved and producing improvement in the
detection levels. The voting range was yielded equal rates of correct and false positive
detections for system 12 by the system 13.
The above Table 1 concluded with the System 11’s reasonable performance in trade-
off under the circumstances of detection rate and incorrect detections. The average detection
rage was 86% of correct faces, and average each false detection per 1,130,012 20x20
windowed pixels. The extracted (output) images from System 11 are shown in the Figure 3.
Figure 3: Output images from System 11 (shown in Table 1).
(Source: Author)
Conclusion and Future Work
The algorithm was capable of detecting 79-91% of faces in 140 sets of test images,
with considerable number of fake detections. Based on the evaluation, the conservativeness
of the system is sufficient to vary the arbitrated heuristics and thresholds usage. Variety of

10ReferencesReferences
image testing with different challenges and unconstrained background has been implemented
on the system. The system capably works with the neural networks and produces satisfactory
outcomes. The area of image processing has been shed light in this study, to produce better
outcomes in the future. Thus, future work on the current research is subjected to create
different and better results.
There are multiple directions for future research. The present system has a limitation
in detecting the straight-uptight faces, eyeing at the camera. More training on head
orientations could produce results under certain arbitrations. Other improvement methods
could be production of more sophisticated pre-processing of images and techniques of
normalization. For instance, the methods of colour segmentation in (Wen et al. 2016) can be
used for coloured-identifier face tracking for image filtering. The face detector will scan the
portions of the skin coloured image, thus producing a fast algorithm rate and further
elimination of fake detections.
The application of this work can be scoped to be used in media technology. Storing of
information is improving each and every year, while the rates are moving cheaper and
cheaper. Whereas, information content is highly limited on the facts of automated high-level
of classification. Thus, it is a bottleneck prohibiting media technology from achieving the
proper potentiality. The above described work enables a user to create question on the fact of
“Which scenarios in the videos consist of human faces?” and the question is answered in an
automatic manner.
image testing with different challenges and unconstrained background has been implemented
on the system. The system capably works with the neural networks and produces satisfactory
outcomes. The area of image processing has been shed light in this study, to produce better
outcomes in the future. Thus, future work on the current research is subjected to create
different and better results.
There are multiple directions for future research. The present system has a limitation
in detecting the straight-uptight faces, eyeing at the camera. More training on head
orientations could produce results under certain arbitrations. Other improvement methods
could be production of more sophisticated pre-processing of images and techniques of
normalization. For instance, the methods of colour segmentation in (Wen et al. 2016) can be
used for coloured-identifier face tracking for image filtering. The face detector will scan the
portions of the skin coloured image, thus producing a fast algorithm rate and further
elimination of fake detections.
The application of this work can be scoped to be used in media technology. Storing of
information is improving each and every year, while the rates are moving cheaper and
cheaper. Whereas, information content is highly limited on the facts of automated high-level
of classification. Thus, it is a bottleneck prohibiting media technology from achieving the
proper potentiality. The above described work enables a user to create question on the fact of
“Which scenarios in the videos consist of human faces?” and the question is answered in an
automatic manner.

11ReferencesReferences
References
Aitkenhead, M.J. and McDonald, A.J.S., 2003. A neural network face recognition
system. Engineering Applications of Artificial Intelligence, 16(3), pp.167-176.
Haddadnia, J. and Ahmadi, M., 2004. N-feature neural network human face
recognition. Image and Vision Computing, 22(12), pp.1071-1082.
He, K., Zhang, X., Ren, S. and Sun, J., 2016. Deep residual learning for image recognition.
In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-
778).
Hu, G., Yang, Y., Yi, D., Kittler, J., Christmas, W., Li, S.Z. and Hospedales, T., 2015. When
face recognition meets with deep learning: an evaluation of convolutional neural networks for
face recognition. In Proceedings of the IEEE international conference on computer vision
workshops (pp. 142-150).
Juell, P. and Marsh, R., 1996. A hierarchical neural network for human face
detection. Pattern Recognition, 29(5), pp.781-787.
Liang, M. and Hu, X., 2015. Recurrent convolutional neural network for object recognition.
In Proceedings of the IEEE conference on computer vision and pattern recognition (pp.
3367-3375).
Mollahosseini, A., Chan, D. and Mahoor, M.H., 2016, March. Going deeper in facial
expression recognition using deep neural networks. In 2016 IEEE Winter conference on
applications of computer vision (WACV) (pp. 1-10). IEEE.
Parkhi, O.M., Vedaldi, A. and Zisserman, A., 2015, September. Deep face recognition.
In bmvc (Vol. 1, No. 3, p. 6).
References
Aitkenhead, M.J. and McDonald, A.J.S., 2003. A neural network face recognition
system. Engineering Applications of Artificial Intelligence, 16(3), pp.167-176.
Haddadnia, J. and Ahmadi, M., 2004. N-feature neural network human face
recognition. Image and Vision Computing, 22(12), pp.1071-1082.
He, K., Zhang, X., Ren, S. and Sun, J., 2016. Deep residual learning for image recognition.
In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-
778).
Hu, G., Yang, Y., Yi, D., Kittler, J., Christmas, W., Li, S.Z. and Hospedales, T., 2015. When
face recognition meets with deep learning: an evaluation of convolutional neural networks for
face recognition. In Proceedings of the IEEE international conference on computer vision
workshops (pp. 142-150).
Juell, P. and Marsh, R., 1996. A hierarchical neural network for human face
detection. Pattern Recognition, 29(5), pp.781-787.
Liang, M. and Hu, X., 2015. Recurrent convolutional neural network for object recognition.
In Proceedings of the IEEE conference on computer vision and pattern recognition (pp.
3367-3375).
Mollahosseini, A., Chan, D. and Mahoor, M.H., 2016, March. Going deeper in facial
expression recognition using deep neural networks. In 2016 IEEE Winter conference on
applications of computer vision (WACV) (pp. 1-10). IEEE.
Parkhi, O.M., Vedaldi, A. and Zisserman, A., 2015, September. Deep face recognition.
In bmvc (Vol. 1, No. 3, p. 6).
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

12ReferencesReferences
Ronao, C.A. and Cho, S.B., 2016. Human activity recognition with smartphone sensors using
deep learning neural networks. Expert systems with applications, 59, pp.235-244.
Schmidhuber, J., 2015. Deep learning in neural networks: An overview. Neural networks, 61,
pp.85-117.
Sun, Y., Liang, D., Wang, X. and Tang, X., 2015. Deepid3: Face recognition with very deep
neural networks. arXiv preprint arXiv:1502.00873.
Sutskever, I., Vinyals, O. and Le, Q.V., 2014. Sequence to sequence learning with neural
networks. In Advances in neural information processing systems (pp. 3104-3112).
Wen, Y., Zhang, K., Li, Z. and Qiao, Y., 2016, October. A discriminative feature learning
approach for deep face recognition. In European conference on computer vision (pp. 499-
515). Springer, Cham.
Yang, J., Nguyen, M.N., San, P.P., Li, X.L. and Krishnaswamy, S., 2015, June. Deep
convolutional neural networks on multichannel time series for human activity recognition.
In Twenty-Fourth International Joint Conference on Artificial Intelligence.
Yang, J., Ren, P., Zhang, D., Chen, D., Wen, F., Li, H. and Hua, G., 2017. Neural
aggregation network for video face recognition. In Proceedings of the IEEE conference on
computer vision and pattern recognition (pp. 4362-4371).
Ronao, C.A. and Cho, S.B., 2016. Human activity recognition with smartphone sensors using
deep learning neural networks. Expert systems with applications, 59, pp.235-244.
Schmidhuber, J., 2015. Deep learning in neural networks: An overview. Neural networks, 61,
pp.85-117.
Sun, Y., Liang, D., Wang, X. and Tang, X., 2015. Deepid3: Face recognition with very deep
neural networks. arXiv preprint arXiv:1502.00873.
Sutskever, I., Vinyals, O. and Le, Q.V., 2014. Sequence to sequence learning with neural
networks. In Advances in neural information processing systems (pp. 3104-3112).
Wen, Y., Zhang, K., Li, Z. and Qiao, Y., 2016, October. A discriminative feature learning
approach for deep face recognition. In European conference on computer vision (pp. 499-
515). Springer, Cham.
Yang, J., Nguyen, M.N., San, P.P., Li, X.L. and Krishnaswamy, S., 2015, June. Deep
convolutional neural networks on multichannel time series for human activity recognition.
In Twenty-Fourth International Joint Conference on Artificial Intelligence.
Yang, J., Ren, P., Zhang, D., Chen, D., Wen, F., Li, H. and Hua, G., 2017. Neural
aggregation network for video face recognition. In Proceedings of the IEEE conference on
computer vision and pattern recognition (pp. 4362-4371).
1 out of 14
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.