IT 446 Data Mining and Data Warehousing | Assignment
VerifiedAdded on 2022/08/14
|9
|1556
|13
AI Summary
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Assignmen
t 1Student Details:
Name: ###
CRN: ###
ID: ###
Instructions:
You must submit two separate copies (one Word file and one PDF file) using the Assignment Template on
Blackboard via the allocated folder. These files must not be in compressed format.
It is your responsibility to check and make sure that you have uploaded both the correct files.
Zero mark will be given if you try to bypass the SafeAssign (e.g. misspell words, remove spaces between words,
hide characters, use different character sets or languages other than English or any kind of manipulation).
Email submission will not be accepted.
You are advised to make your work clear and well-presented. This includes filling your information on the cover
page.
You must use this template, failing which will result in zero mark.
You MUST show all your work, and text must not be converted into an image, unless specified otherwise by the
question.
Late submission will result in ZERO mark.
The work should be your own, copying from students or other resources will result in ZERO mark.
Use Times New Roman font for all your answers.
Data Mining and Data Warehousing
IT 446
t 1Student Details:
Name: ###
CRN: ###
ID: ###
Instructions:
You must submit two separate copies (one Word file and one PDF file) using the Assignment Template on
Blackboard via the allocated folder. These files must not be in compressed format.
It is your responsibility to check and make sure that you have uploaded both the correct files.
Zero mark will be given if you try to bypass the SafeAssign (e.g. misspell words, remove spaces between words,
hide characters, use different character sets or languages other than English or any kind of manipulation).
Email submission will not be accepted.
You are advised to make your work clear and well-presented. This includes filling your information on the cover
page.
You must use this template, failing which will result in zero mark.
You MUST show all your work, and text must not be converted into an image, unless specified otherwise by the
question.
Late submission will result in ZERO mark.
The work should be your own, copying from students or other resources will result in ZERO mark.
Use Times New Roman font for all your answers.
Data Mining and Data Warehousing
IT 446
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Pg. 1 Question FourQuestion Four
Question One
Use the following dataset to find Euclidian, Manhattan and Minkowski Distance
between object A and B. Assume lambda (h) is 3.
Object /
Attribute Cost Time Weight Incentive
Object A 0 3 4 5
Object B 7 6 3 -1
Euclidian,
=
√ ( 0−7 ) 2 + ( 3−6 ) 2+ ( 4−3 ) 2 + ( 5+1 ) 2
=
√49+9+1+36
=
√ 95 =9.75 (Answer)
Manhattan,
=
|0−7|+|3−6|+|4−3|+¿ 5+1|
=7+3+1+6 =17 (Answer)
Murkowski Distance,
Learning
Outcome(s):
Instructors: State
the Learning
Outcome(s) that
match this question
Marks: 1.5
Question One
Use the following dataset to find Euclidian, Manhattan and Minkowski Distance
between object A and B. Assume lambda (h) is 3.
Object /
Attribute Cost Time Weight Incentive
Object A 0 3 4 5
Object B 7 6 3 -1
Euclidian,
=
√ ( 0−7 ) 2 + ( 3−6 ) 2+ ( 4−3 ) 2 + ( 5+1 ) 2
=
√49+9+1+36
=
√ 95 =9.75 (Answer)
Manhattan,
=
|0−7|+|3−6|+|4−3|+¿ 5+1|
=7+3+1+6 =17 (Answer)
Murkowski Distance,
Learning
Outcome(s):
Instructors: State
the Learning
Outcome(s) that
match this question
Marks: 1.5

Pg. 2 Question FourQuestion Four
3
√ ( 0−7 ) 3 + ( 3−6 ) 3 + ( 4−3 )
3 + ( 5+1 )
3
= 3
√ 587 =9.50 (Answer)
3
√ ( 0−7 ) 3 + ( 3−6 ) 3 + ( 4−3 )
3 + ( 5+1 )
3
= 3
√ 587 =9.50 (Answer)

Pg. 3 Question FourQuestion Four
Question Two
What is data sampling in data mining? Explain four (4) types of data sampling
techniques.
Answer:
In statistical analysis data are being manipulate and analyzed by using subsets of data
to identify hidden patterns and trends which are used later on to take decisions, this whole
process is known as data sampling. These type of technology are been used by many data
analyst and data scientist to solve statistical problems by building predictive models which can
be used for predicting and forecasting purposes. Data sampling are useful when the dataset is
large enough to analyze properly.
There are different types of data sampling which depends on data set and the
requirements and is based on probability. Hence probability sampling includes-
One of the general used sampling method is simple random sampling where from the
total population each and every member will get equal chances to get selected. And if adequate
sampling size is selected in this method then the result of random sampling are considered to
be the best.
Systematic sampling is another kind of sampling technique where randomly the first
element in the population were chosen, afterwards the next elements are chosen in a systematic
way. Also these type of techniques don’t need a static population base and are systematic.
Multistage sampling is another type of sampling which is based on cluster sampling
where this sampling breaks the population into groups by dividing the population into clusters.
The staging continues as different subset are being identified, clustered and analyzed.
Learning
Outcome(s):
Instructors: State
the Learning
Outcome(s) that
match this question
Marks: 1.5
Question Two
What is data sampling in data mining? Explain four (4) types of data sampling
techniques.
Answer:
In statistical analysis data are being manipulate and analyzed by using subsets of data
to identify hidden patterns and trends which are used later on to take decisions, this whole
process is known as data sampling. These type of technology are been used by many data
analyst and data scientist to solve statistical problems by building predictive models which can
be used for predicting and forecasting purposes. Data sampling are useful when the dataset is
large enough to analyze properly.
There are different types of data sampling which depends on data set and the
requirements and is based on probability. Hence probability sampling includes-
One of the general used sampling method is simple random sampling where from the
total population each and every member will get equal chances to get selected. And if adequate
sampling size is selected in this method then the result of random sampling are considered to
be the best.
Systematic sampling is another kind of sampling technique where randomly the first
element in the population were chosen, afterwards the next elements are chosen in a systematic
way. Also these type of techniques don’t need a static population base and are systematic.
Multistage sampling is another type of sampling which is based on cluster sampling
where this sampling breaks the population into groups by dividing the population into clusters.
The staging continues as different subset are being identified, clustered and analyzed.
Learning
Outcome(s):
Instructors: State
the Learning
Outcome(s) that
match this question
Marks: 1.5
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Pg. 4 Question FourQuestion Four
Stratified Sampling is one of the kind of sampling where the condition is to find
similarity such that the between the small subgroups from the whole population such that the
group are homogeneous and heterogeneous among the other subgroups formed.
Stratified Sampling is one of the kind of sampling where the condition is to find
similarity such that the between the small subgroups from the whole population such that the
group are homogeneous and heterogeneous among the other subgroups formed.

Pg. 5 Question FourQuestion Four
Question Three
Do you think improvements in database technology helped the surge of data mining?
Explain your answer in details.
Answer:
At first let’s discuss what data-is-
Data are generally raw facts which are collected to get some knowledge out of it.
Data mining is done over huge dataset using data exploration, analysis and
visualization to discover meaningful patterns and insights of the data. Also data mining
techniques are used to build machine learning models that has got the power to predict future
instances.
Huge data are being generated on daily basis thus database technologies are used to
build storage platform which store these huge data for further analysis. With the evaluation of
database technologies different dataset are been generated which helped many data analyst and
data scientist to gain in depth knowledge of the dataset.
With the recent upgradation of data storing platform, there is huge need of data mining
techniques to get valuable and useful information from the database. Database technology are
used in every industries to store data in bulk and using data mining such data’s are analyzed to
get benefitted from future prediction or from the outcome of the analysis.
Database technology are the base of data mining technology, as with the evaluation of
structured storage system more data been stored which attracted many data analysis
enthusiastic to go deep which eventually helped the surge of data mining.
Application of data mining techniques includes fraud detection, sentimental analysis,
qualitative data mining and many more.
Learning
Outcome(s):
Instructors: State
the Learning
Outcome(s) that
match this question
Marks: 1.5
Question Three
Do you think improvements in database technology helped the surge of data mining?
Explain your answer in details.
Answer:
At first let’s discuss what data-is-
Data are generally raw facts which are collected to get some knowledge out of it.
Data mining is done over huge dataset using data exploration, analysis and
visualization to discover meaningful patterns and insights of the data. Also data mining
techniques are used to build machine learning models that has got the power to predict future
instances.
Huge data are being generated on daily basis thus database technologies are used to
build storage platform which store these huge data for further analysis. With the evaluation of
database technologies different dataset are been generated which helped many data analyst and
data scientist to gain in depth knowledge of the dataset.
With the recent upgradation of data storing platform, there is huge need of data mining
techniques to get valuable and useful information from the database. Database technology are
used in every industries to store data in bulk and using data mining such data’s are analyzed to
get benefitted from future prediction or from the outcome of the analysis.
Database technology are the base of data mining technology, as with the evaluation of
structured storage system more data been stored which attracted many data analysis
enthusiastic to go deep which eventually helped the surge of data mining.
Application of data mining techniques includes fraud detection, sentimental analysis,
qualitative data mining and many more.
Learning
Outcome(s):
Instructors: State
the Learning
Outcome(s) that
match this question
Marks: 1.5

Pg. 6 Question FourQuestion Four
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Pg. 7 Question FourQuestion Four
Question Four
Suppose that the data for analysis includes the attribute age. The age values for the
data tuples are (in increasing order) 13, 14, 15, 16, 20, 20, 20, 20, 20, 23, 24, 24, 25,
26, 27, 28, 30, 30, 30, 30, 30, 32, 33, 35, 36, 37, 39, 44, 45.
(a) What is the mean of the data?
(b) What is the median?
(c) What is the mode of the data?
(d) Comment on the data’s modality (i.e., bimodal, trimodal, etc.).
(e) Show a Histogram of the data (10 bars).
Answer:
a) Mean- 27.10
b) Median- 27
c) Mode- 20,30
d) In the dataset there are 2 modes, thus it can be said that the modality of the data is
bimodal.
Learning
Outcome(s):
Instructors: State
the Learning
Outcome(s) that
match this question
Marks: 1.5
Question Four
Suppose that the data for analysis includes the attribute age. The age values for the
data tuples are (in increasing order) 13, 14, 15, 16, 20, 20, 20, 20, 20, 23, 24, 24, 25,
26, 27, 28, 30, 30, 30, 30, 30, 32, 33, 35, 36, 37, 39, 44, 45.
(a) What is the mean of the data?
(b) What is the median?
(c) What is the mode of the data?
(d) Comment on the data’s modality (i.e., bimodal, trimodal, etc.).
(e) Show a Histogram of the data (10 bars).
Answer:
a) Mean- 27.10
b) Median- 27
c) Mode- 20,30
d) In the dataset there are 2 modes, thus it can be said that the modality of the data is
bimodal.
Learning
Outcome(s):
Instructors: State
the Learning
Outcome(s) that
match this question
Marks: 1.5
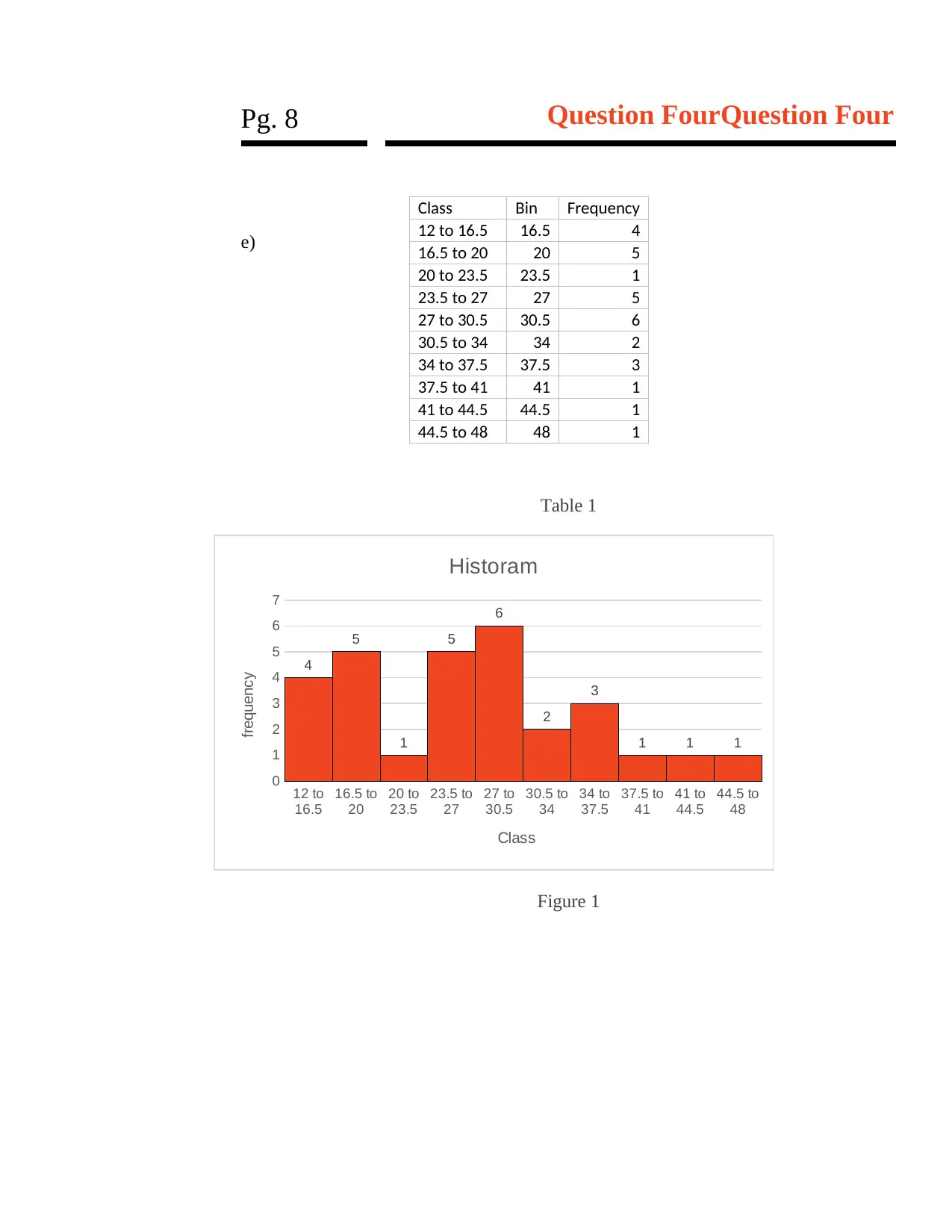
Pg. 8 Question FourQuestion Four
e)
Table 1
Figure 1
12 to
16.5
16.5 to
20
20 to
23.5
23.5 to
27
27 to
30.5
30.5 to
34
34 to
37.5
37.5 to
41
41 to
44.5
44.5 to
48
0
1
2
3
4
5
6
7
4
5
1
5
6
2
3
1 1 1
Historam
Class
frequency
Class Bin Frequency
12 to 16.5 16.5 4
16.5 to 20 20 5
20 to 23.5 23.5 1
23.5 to 27 27 5
27 to 30.5 30.5 6
30.5 to 34 34 2
34 to 37.5 37.5 3
37.5 to 41 41 1
41 to 44.5 44.5 1
44.5 to 48 48 1
e)
Table 1
Figure 1
12 to
16.5
16.5 to
20
20 to
23.5
23.5 to
27
27 to
30.5
30.5 to
34
34 to
37.5
37.5 to
41
41 to
44.5
44.5 to
48
0
1
2
3
4
5
6
7
4
5
1
5
6
2
3
1 1 1
Historam
Class
frequency
Class Bin Frequency
12 to 16.5 16.5 4
16.5 to 20 20 5
20 to 23.5 23.5 1
23.5 to 27 27 5
27 to 30.5 30.5 6
30.5 to 34 34 2
34 to 37.5 37.5 3
37.5 to 41 41 1
41 to 44.5 44.5 1
44.5 to 48 48 1
1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.