Object and Data Modelling
Added on 2022-09-30
30 Pages2071 Words459 Views
Running Head: MODELLING 1
Object and Data Modelling
Name of Student
School
Classification Performance Evaluation (Task 1).
Object and Data Modelling
Name of Student
School
Classification Performance Evaluation (Task 1).

MODELLING 2
In this part, there will be an evaluation of the performance of five machine learning models in
Weka. Weka is a non-coding machine learning software from Waikato University and it helps
curb most of the troubles that students who are not good in coding do have, like for example, a
mathematical student might want to get insights on the statistical relations that the variables have
and might decide to use statistical software. In any case, the student lacks the coding skills that
are required for example in the platforms such as Python and R then the student an always opt
for non-coding software and in this software we do have Weka and Rapid Minor as the best
examples.
Three datasets are provided in this case and each is, therefore, has to undergo five classification
machine learning models. The models' performances are then supposed to be compared in bid to
get the one that has the top most accuracy in the whole process. The models that have been listed
for comparison include; MultilayerPerceptron, Naive Bayes, decision tree’s J48, RandomForest
and RERTree (Kotthoff, Thornton, Hoos, Hutter & Leyton-Brown, 2019).
1. Iris Dataset
In this case, we will have to begin with the alignment of the Iris dataset and according to the
screen-shot below, we have up to 150 instances as well as 5 number of attributes to be
considered in for analysis. Figure 1 shows the actual descriptive statistics on the sepal length
variable to the right where the mean, standard deviation, the minimum and the maximum
characters are all indicated.
In this part, there will be an evaluation of the performance of five machine learning models in
Weka. Weka is a non-coding machine learning software from Waikato University and it helps
curb most of the troubles that students who are not good in coding do have, like for example, a
mathematical student might want to get insights on the statistical relations that the variables have
and might decide to use statistical software. In any case, the student lacks the coding skills that
are required for example in the platforms such as Python and R then the student an always opt
for non-coding software and in this software we do have Weka and Rapid Minor as the best
examples.
Three datasets are provided in this case and each is, therefore, has to undergo five classification
machine learning models. The models' performances are then supposed to be compared in bid to
get the one that has the top most accuracy in the whole process. The models that have been listed
for comparison include; MultilayerPerceptron, Naive Bayes, decision tree’s J48, RandomForest
and RERTree (Kotthoff, Thornton, Hoos, Hutter & Leyton-Brown, 2019).
1. Iris Dataset
In this case, we will have to begin with the alignment of the Iris dataset and according to the
screen-shot below, we have up to 150 instances as well as 5 number of attributes to be
considered in for analysis. Figure 1 shows the actual descriptive statistics on the sepal length
variable to the right where the mean, standard deviation, the minimum and the maximum
characters are all indicated.

MODELLING 3
figure 1.
figure 2.
Figure 2 gives statistics on sepal width and this gives 23 entries that are distinct from other
entries made. Moving on to the next variable, we have; figure 3 which is on petal length
figure 3.
figure 1.
figure 2.
Figure 2 gives statistics on sepal width and this gives 23 entries that are distinct from other
entries made. Moving on to the next variable, we have; figure 3 which is on petal length
figure 3.

MODELLING 4
figure 4.
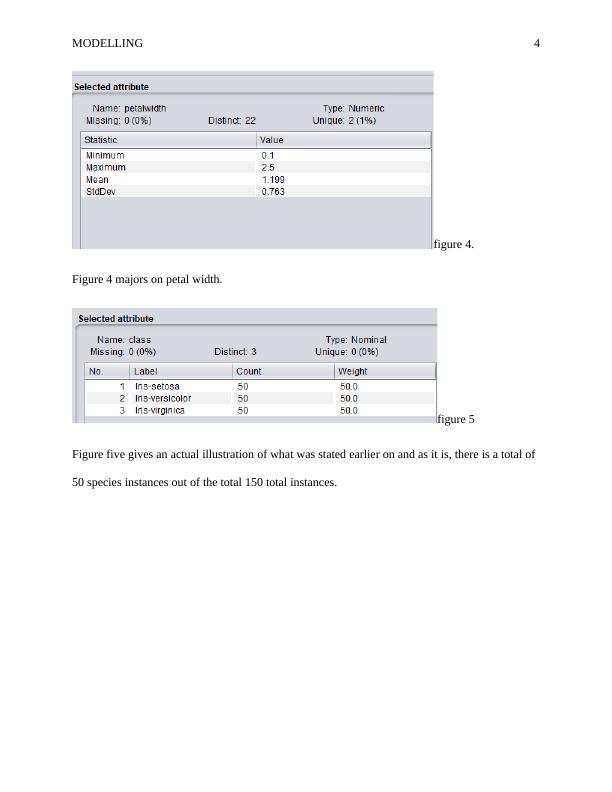
Figure 4 majors on petal width.
figure 5
Figure five gives an actual illustration of what was stated earlier on and as it is, there is a total of
50 species instances out of the total 150 total instances.
figure 4.
Figure 4 majors on petal width.
figure 5
Figure five gives an actual illustration of what was stated earlier on and as it is, there is a total of
50 species instances out of the total 150 total instances.
MODELLING 5
figure 6.
The above gives the graphical alignment of the entire distributions that are needed.
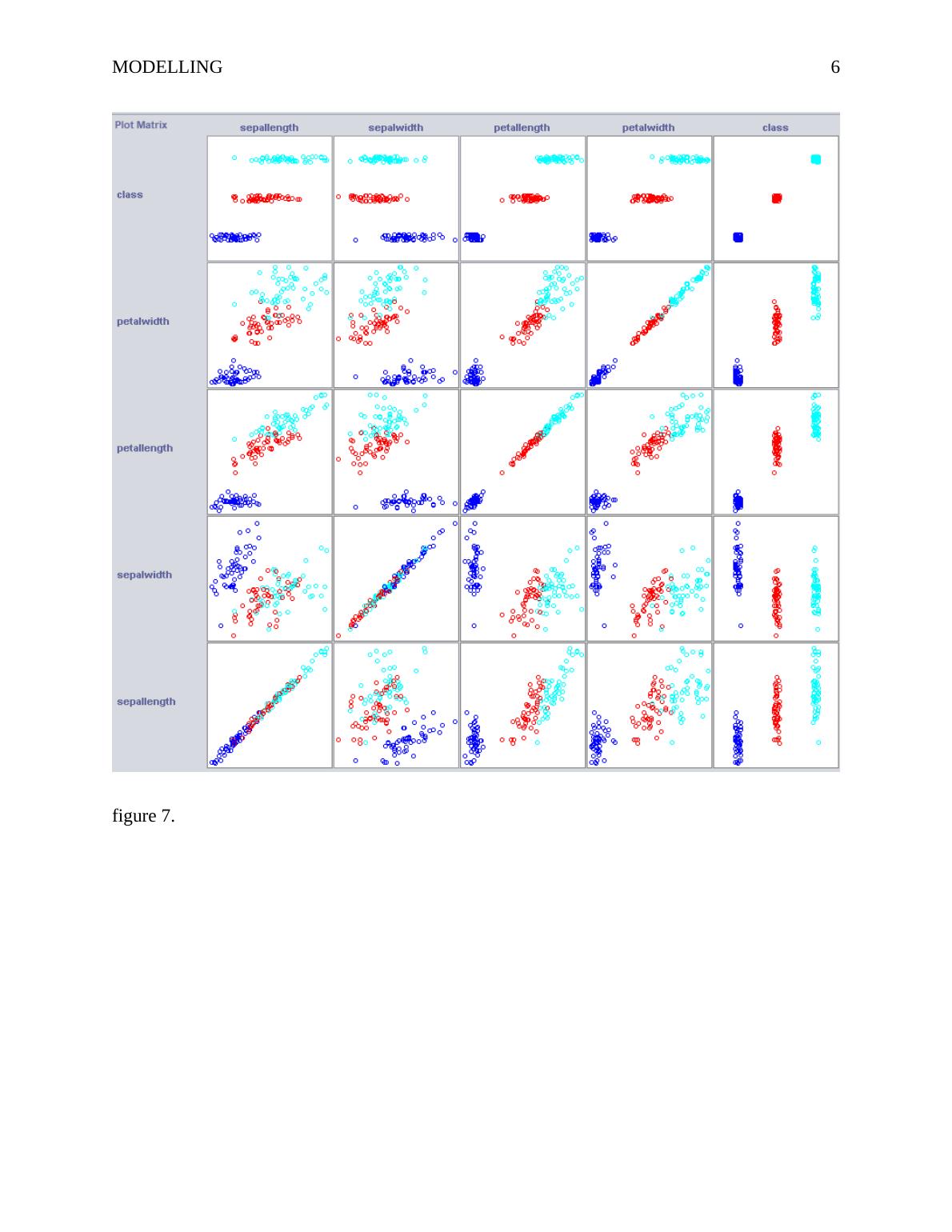
As of figure 7, there is a clear illustration of the actual scatter plot that gives the scatter
relationship of the actual variables that are to be used in for analysis. The most important thing to
note is, the blue, red and green represent Iris setosa, Iris versicolor and Iris virginica respectively.
In the scatter plots, it is very clear to see that there are different clusters even as the variables
intersect.
figure 6.
The above gives the graphical alignment of the entire distributions that are needed.
As of figure 7, there is a clear illustration of the actual scatter plot that gives the scatter
relationship of the actual variables that are to be used in for analysis. The most important thing to
note is, the blue, red and green represent Iris setosa, Iris versicolor and Iris virginica respectively.
In the scatter plots, it is very clear to see that there are different clusters even as the variables
intersect.

MODELLING 6
figure 7.
figure 7.
End of preview
Want to access all the pages? Upload your documents or become a member.
Related Documents
Data Mining Case Study 2022lg...
|25
|1821
|23
Visual Analysis of Diabetes Dataset Assignmentlg...
|11
|517
|35
Weka: Data Mining and Machine Learning Topic 2022lg...
|13
|1214
|16
(PDF) SVM Classification with Linear and RBF kernelslg...
|5
|1826
|79