Data Analysis for Train Station Usage
VerifiedAdded on 2020/10/22
|10
|1433
|339
AI Summary
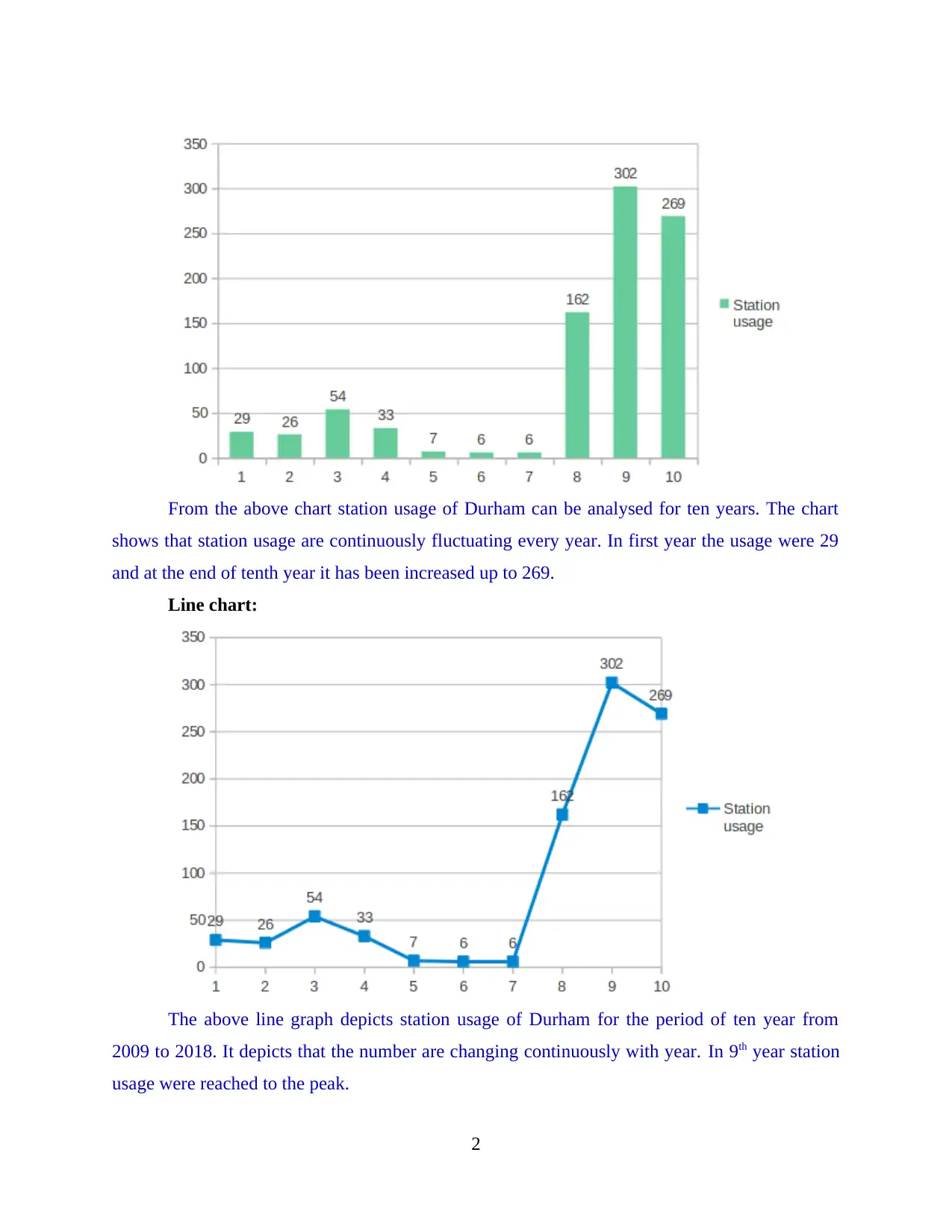
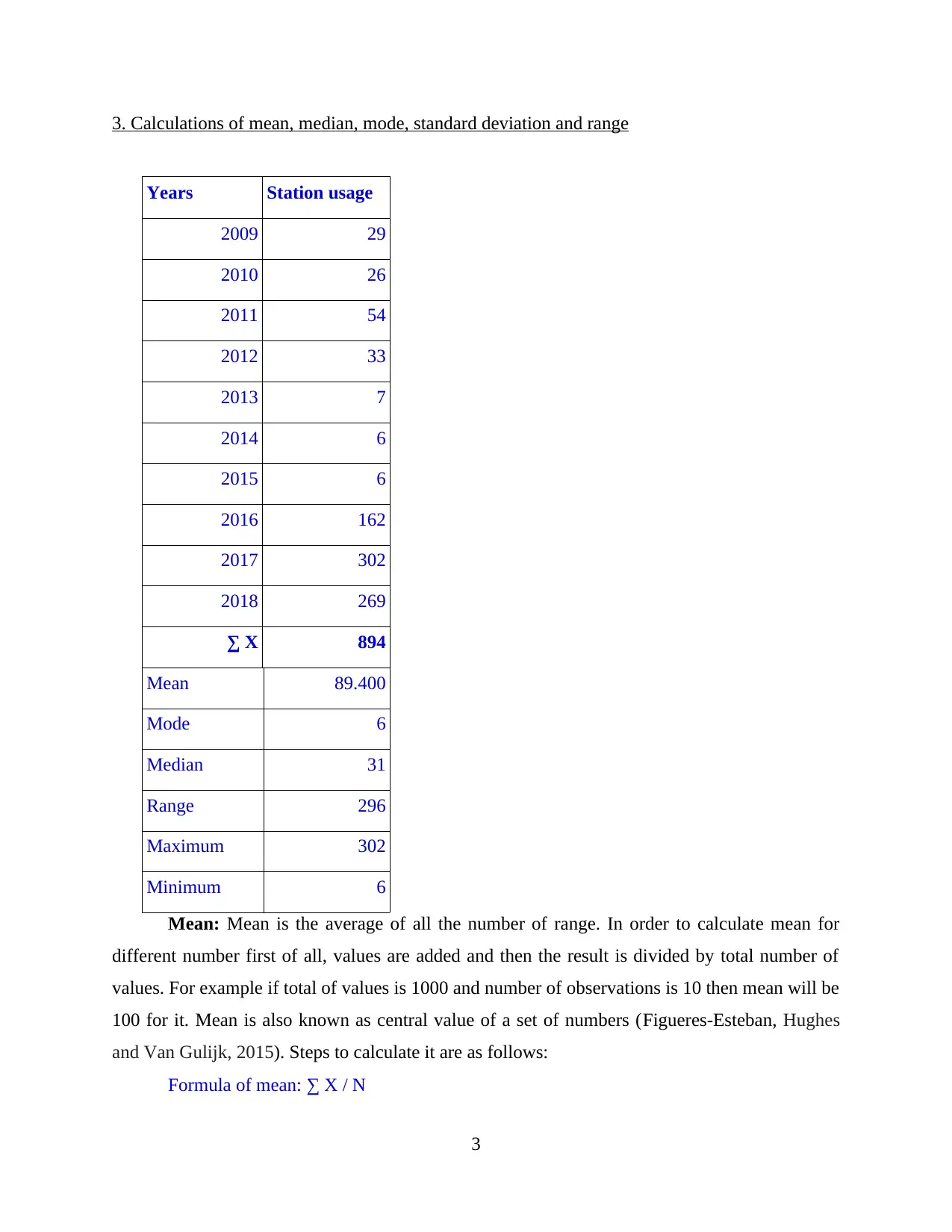
The provided project report is a comprehensive analysis of train station usage data. The report involves calculating mean values, standard deviations, and other statistical measures to understand the trends in station usage. It also includes a detailed calculation of the value of 'm' in the equation y = mx + c using the given data points. Further, it predicts the station usage for years 12 and 15 based on the calculated values. The report concludes that data analysis is essential in resolving issues related to numeracy and provides insights into various statistical measures.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.








1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
© 2024 | Zucol Services PVT LTD | All rights reserved.