Counting, Probability Distributions and Statistical Data Analysis
VerifiedAdded on 2023/06/11
|25
|2735
|494
Homework Assignment
AI Summary
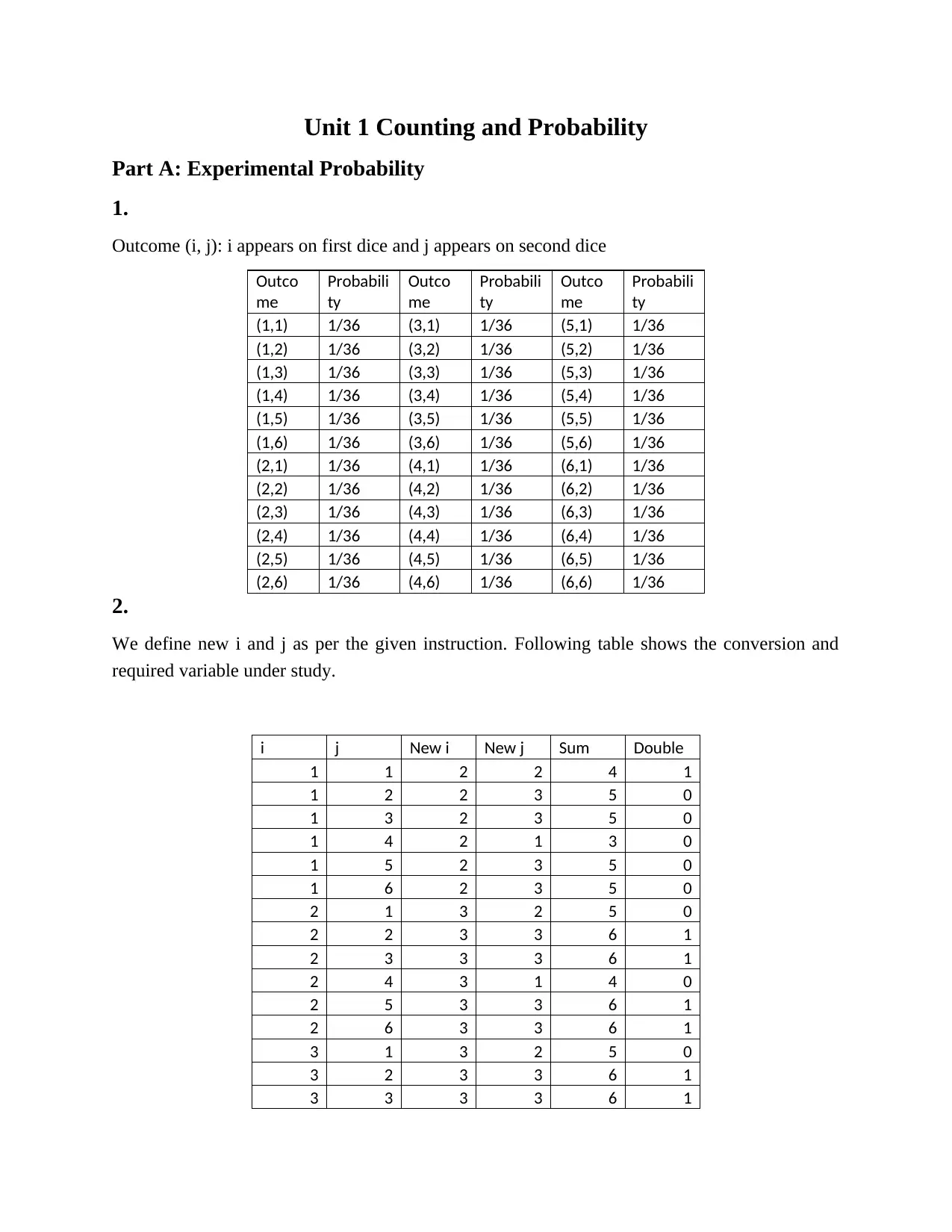
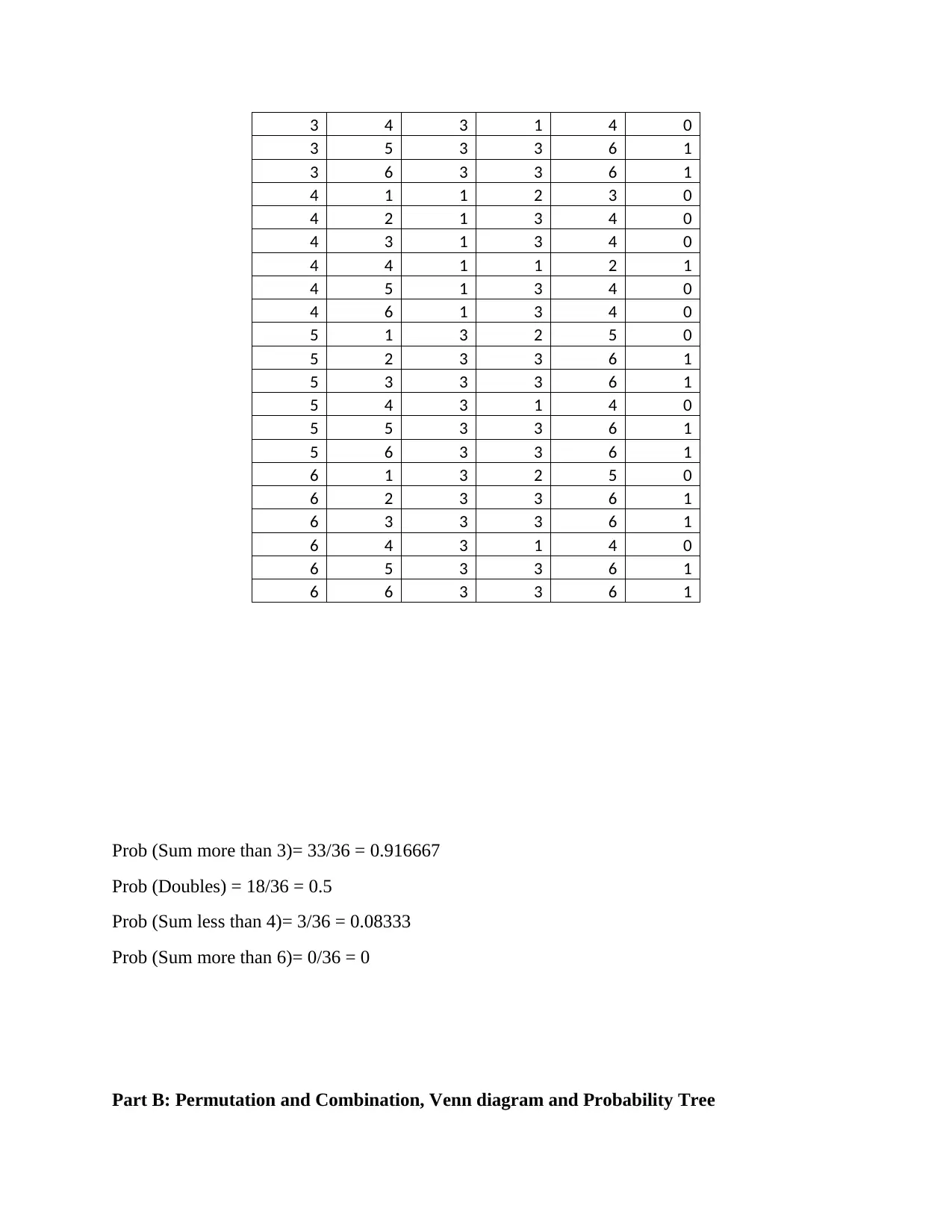
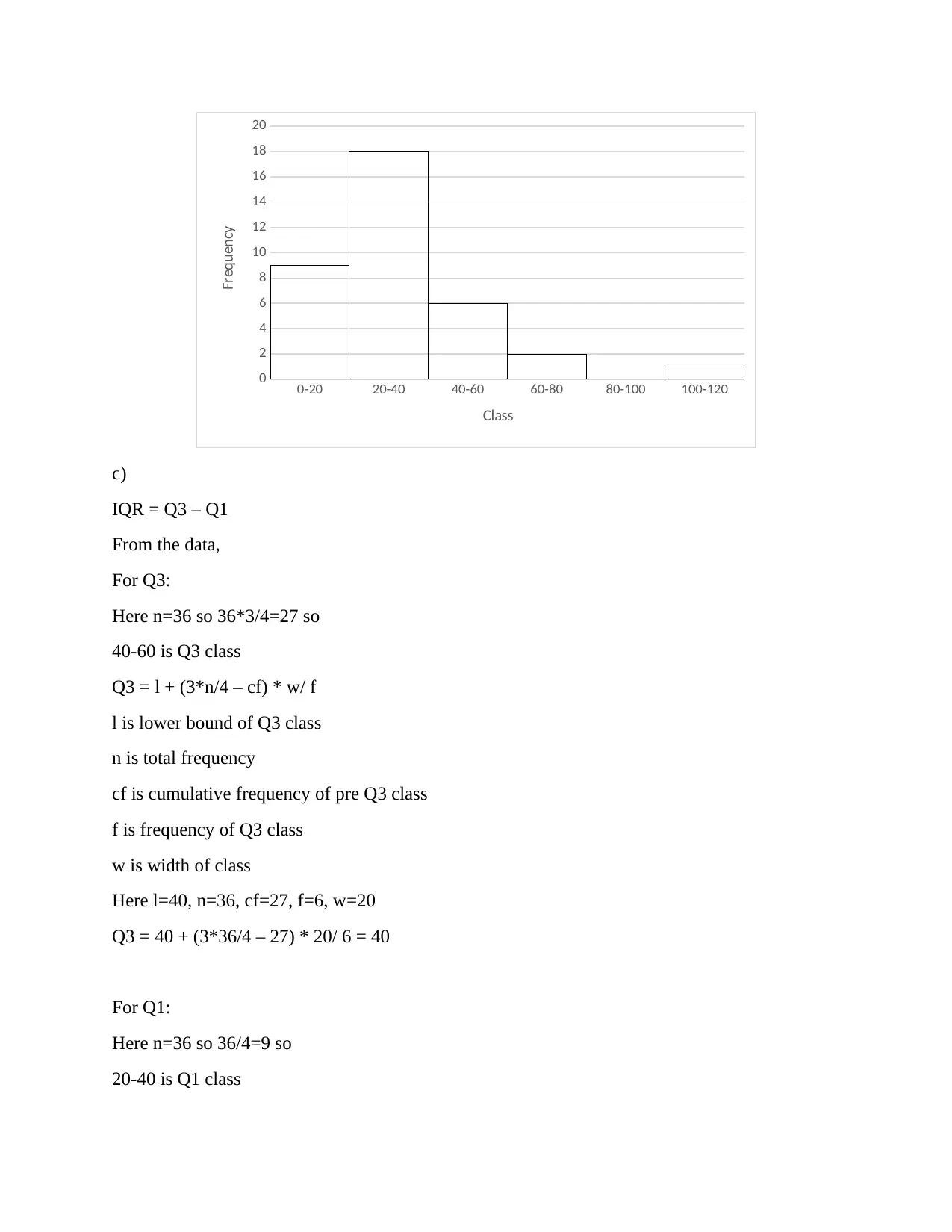
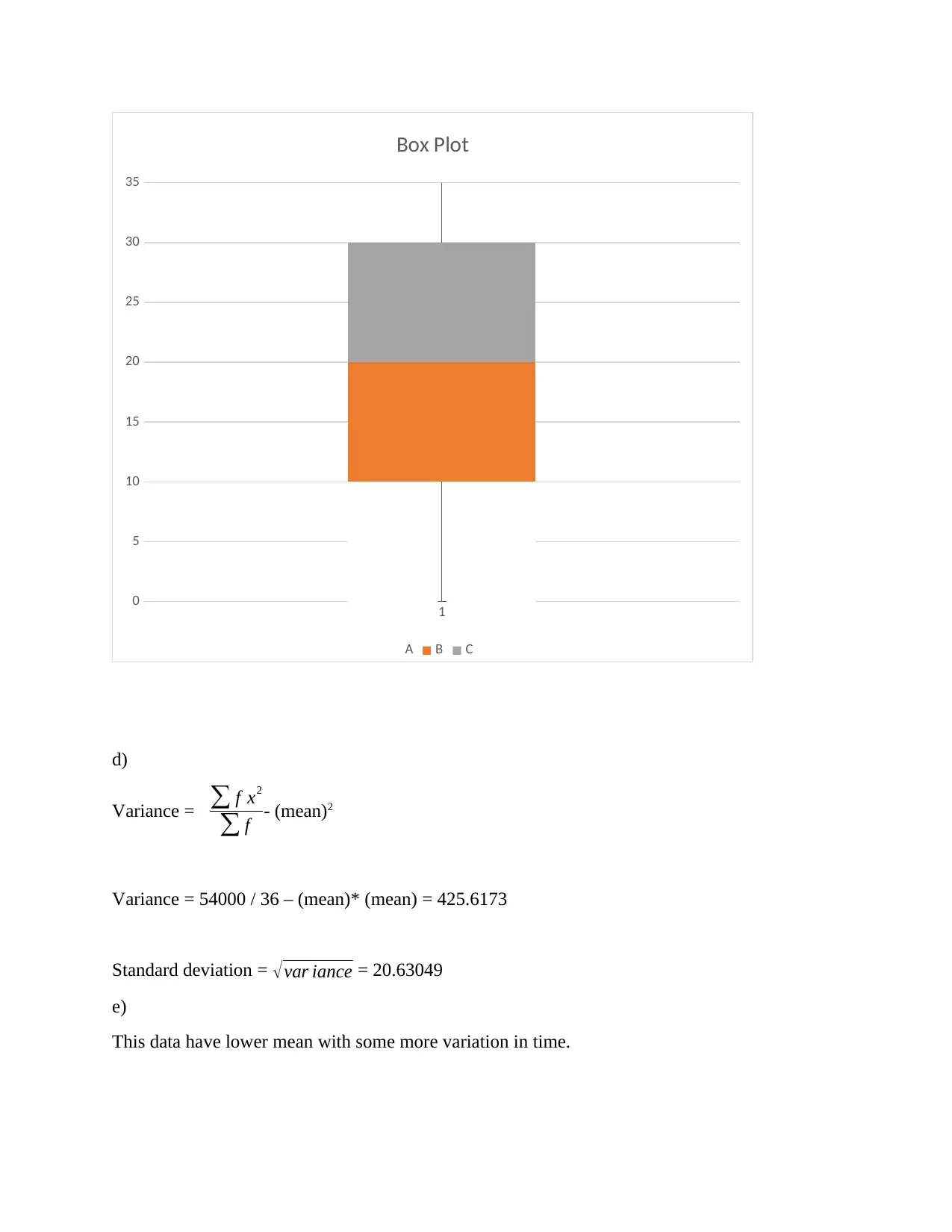
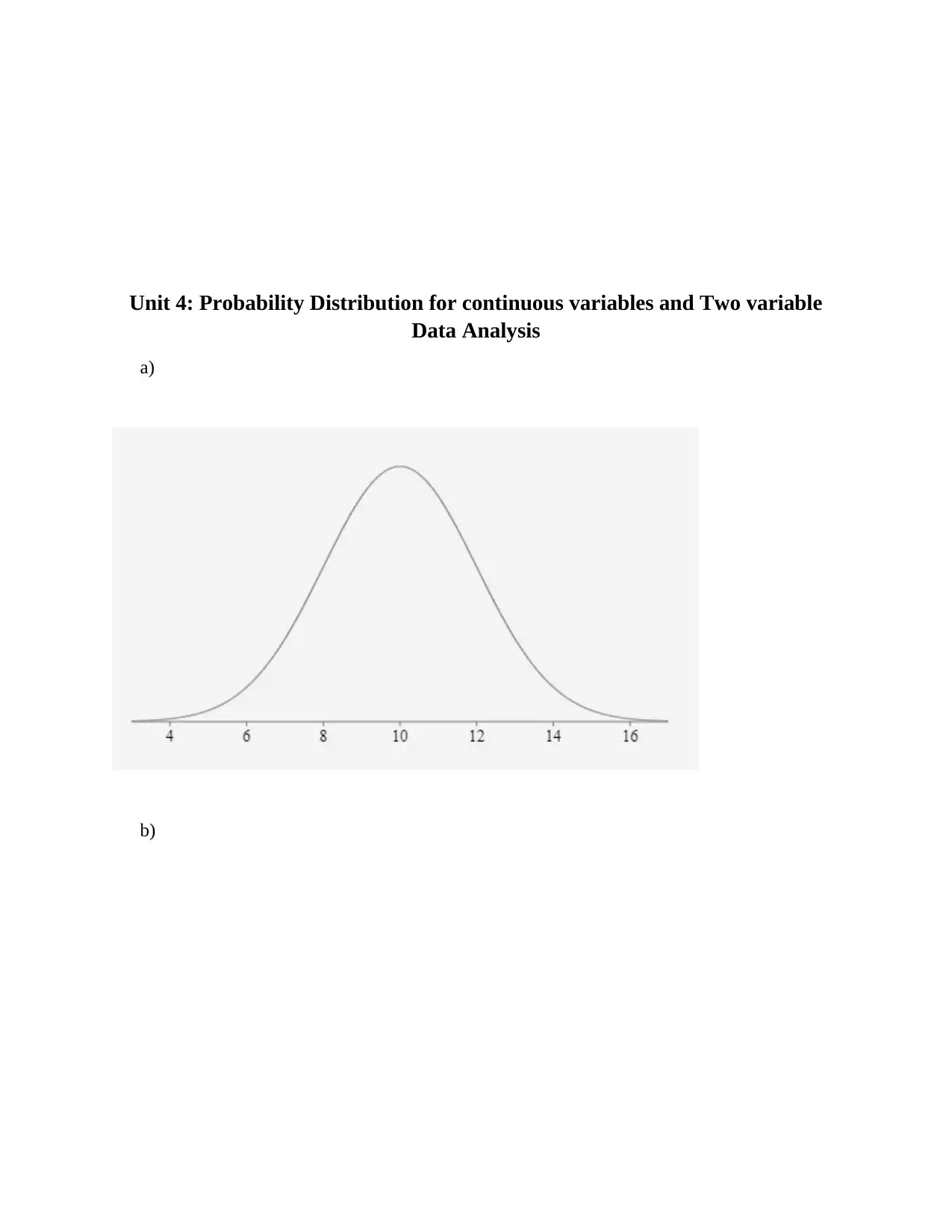
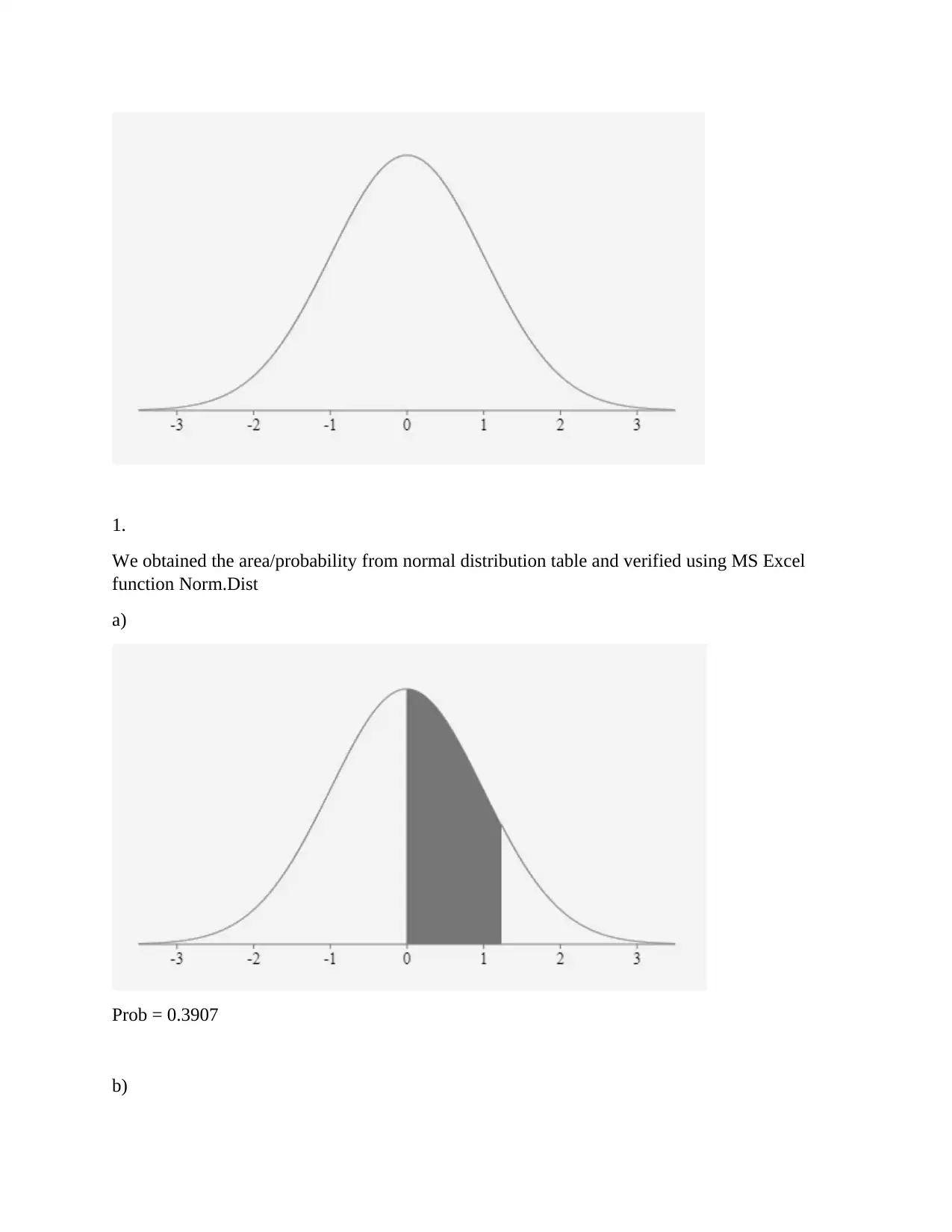
This assignment provides solutions to problems related to counting and probability, including experimental probability, permutations, combinations, and Venn diagrams. It also covers probability distributions for discrete and continuous variables, including calculations of mean, median, mode, interquartile range (IQR), variance, and standard deviation. The assignment includes data analysis using MS Excel, normal distribution calculations, and regression analysis to determine the relationship between instructional hours and student scores. The analysis includes identifying and removing outliers to improve the accuracy of the regression model. The assignment concludes with a discussion on the reliability of data and potential biases in data collection.






1 out of 25
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.