ISYS3374 Business Analytics: Data Analysis and Classification Methods
VerifiedAdded on 2023/03/31
|10
|1387
|220
Homework Assignment
AI Summary
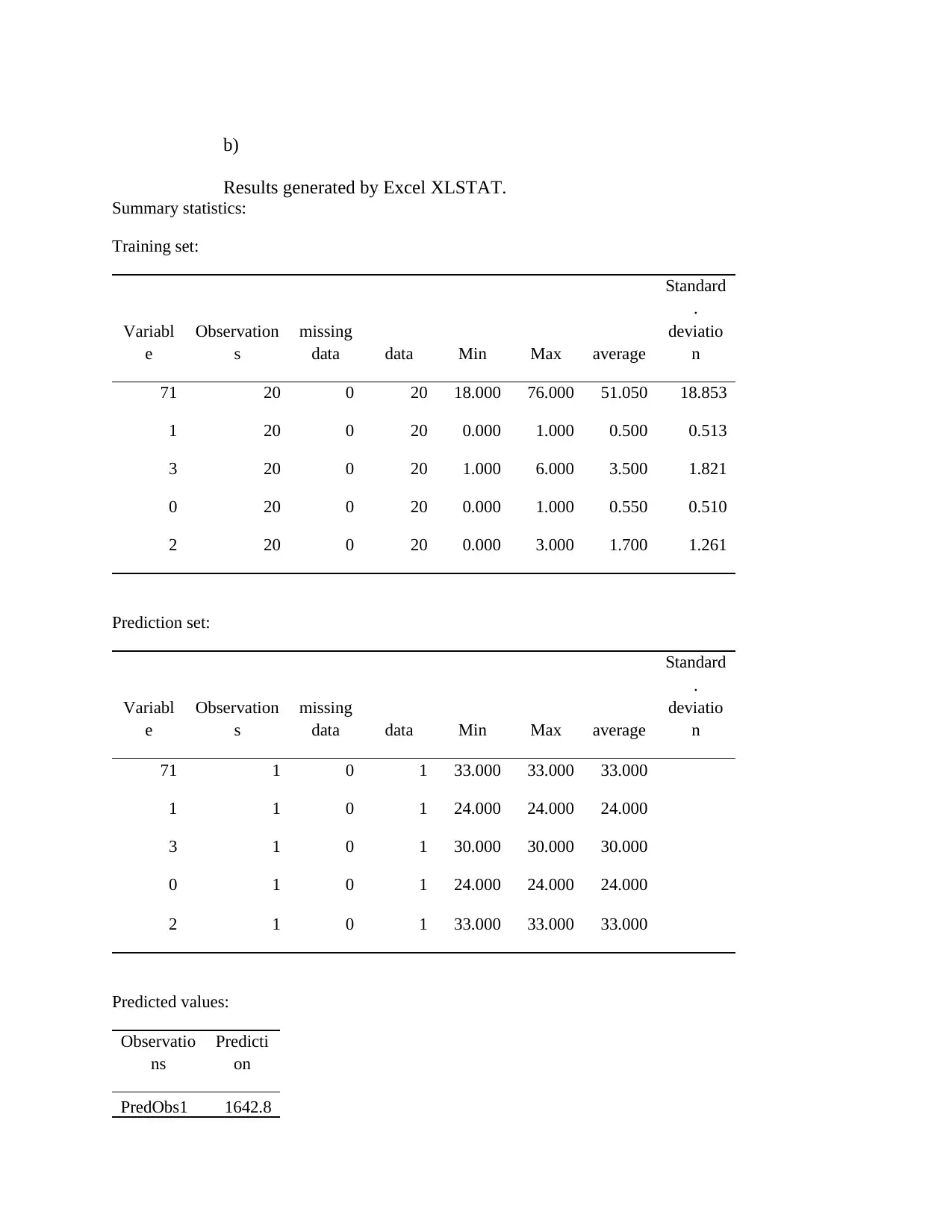
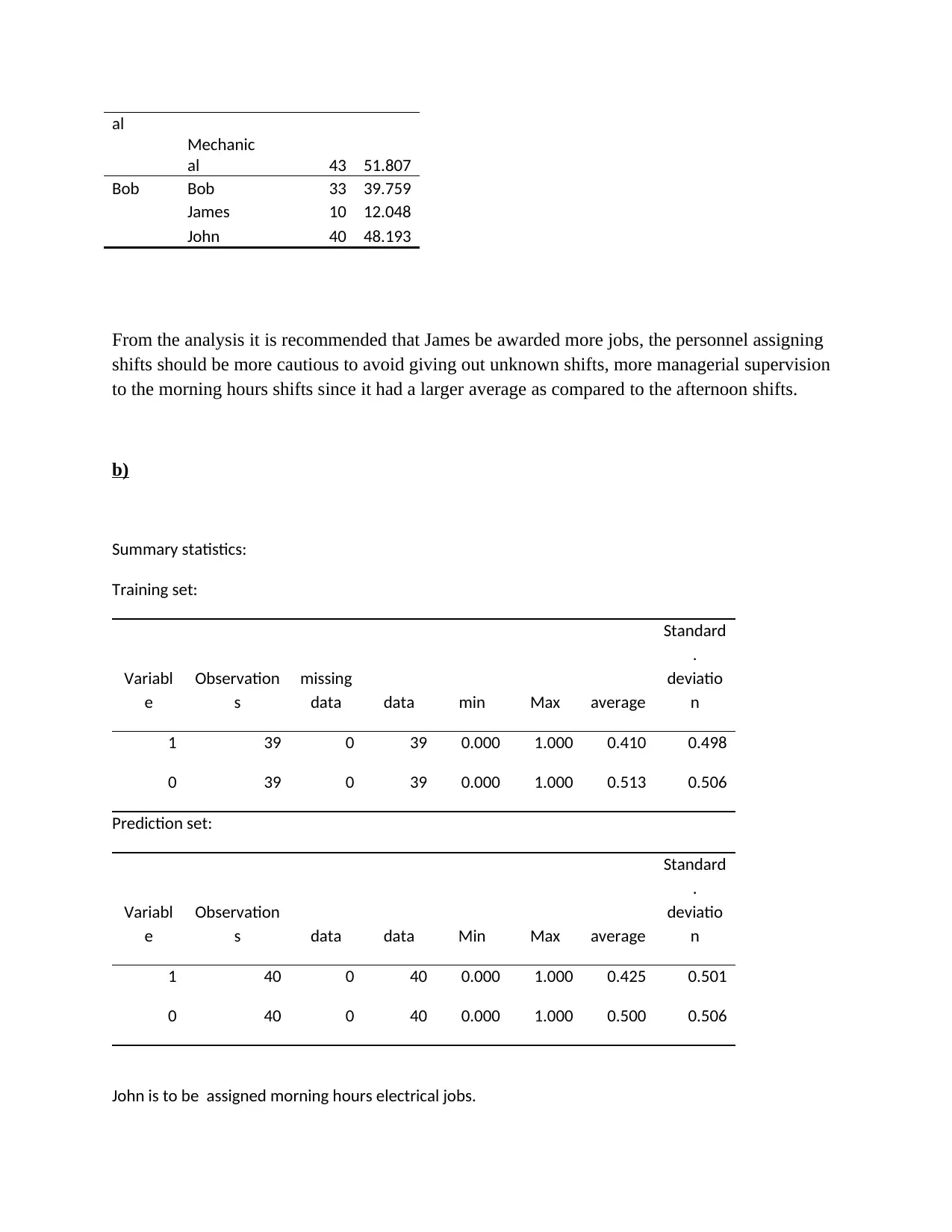
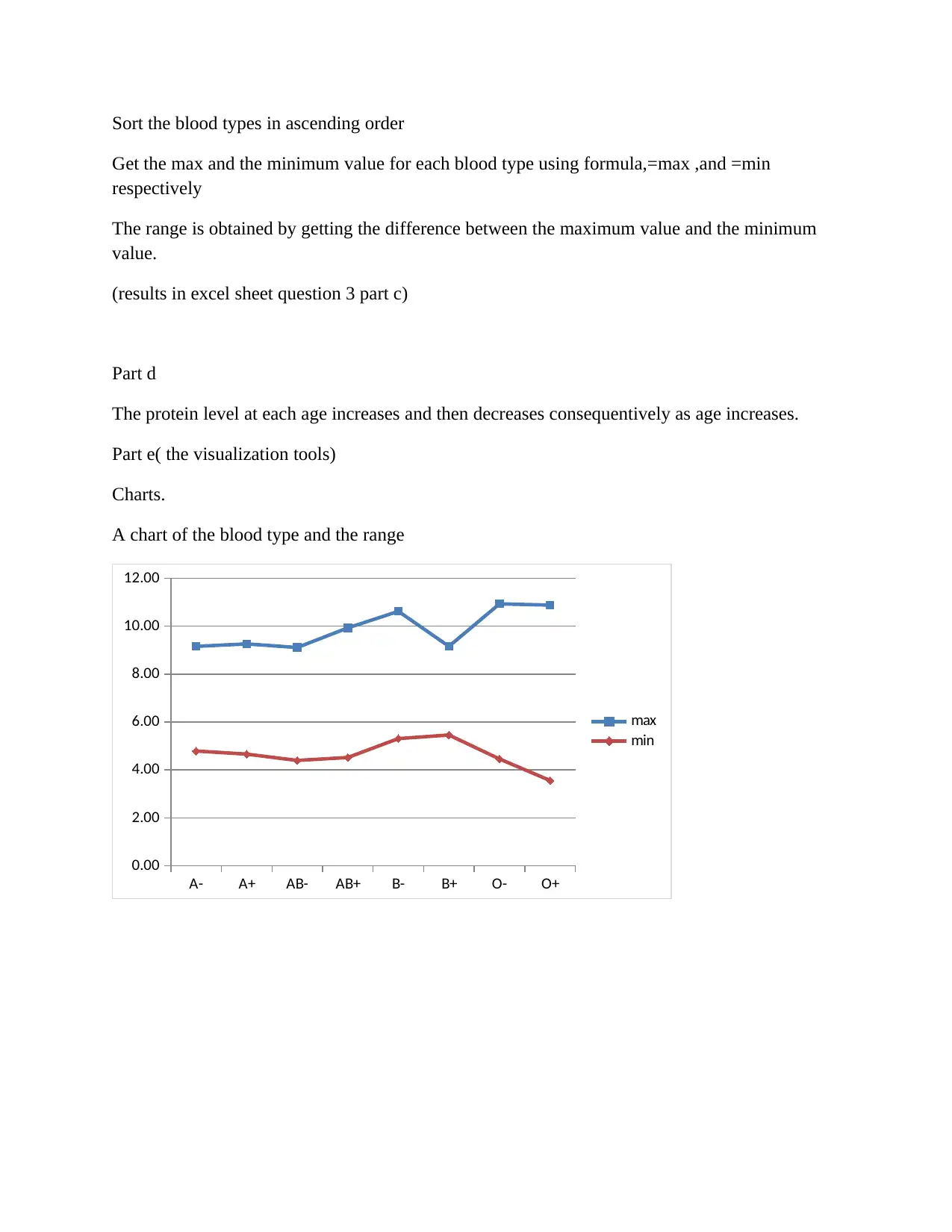
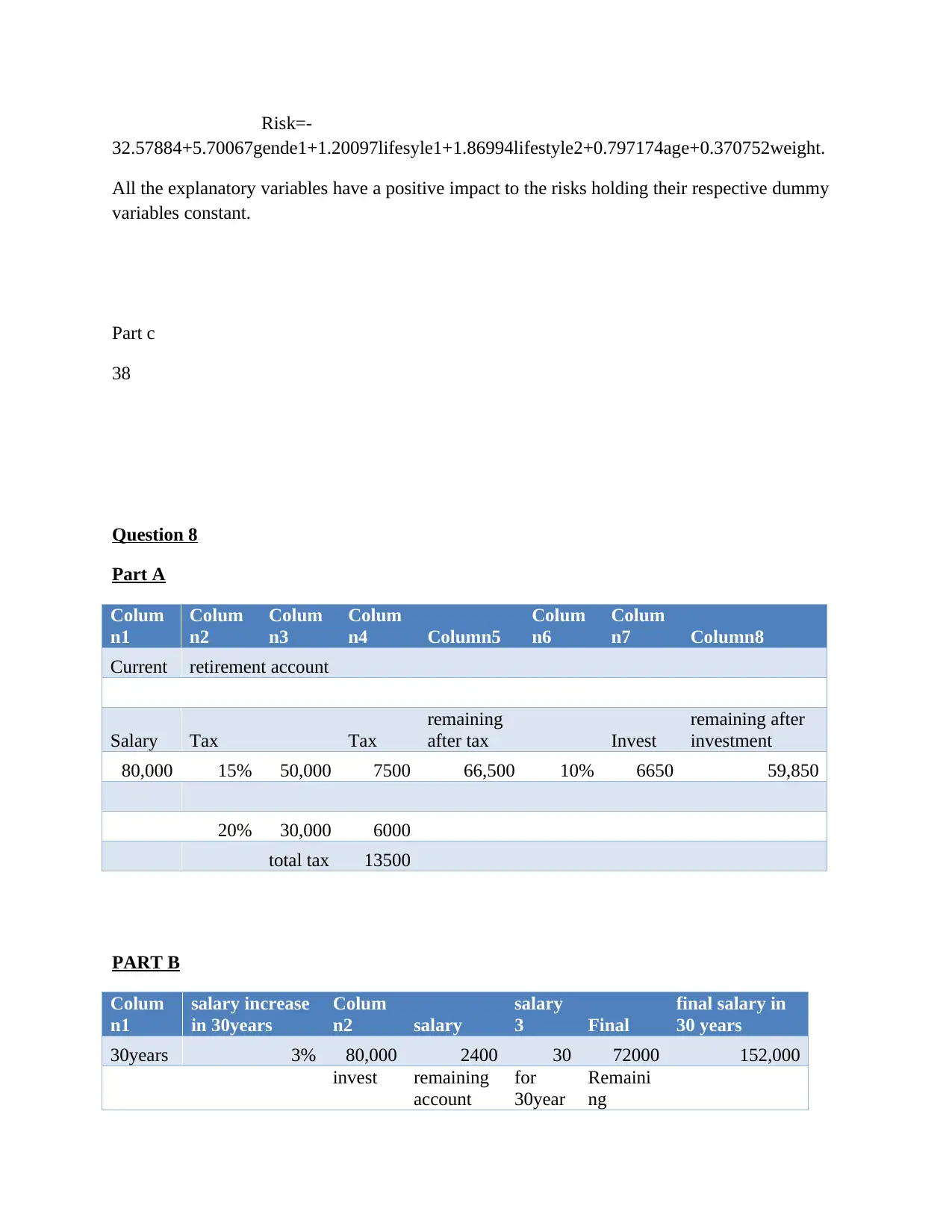
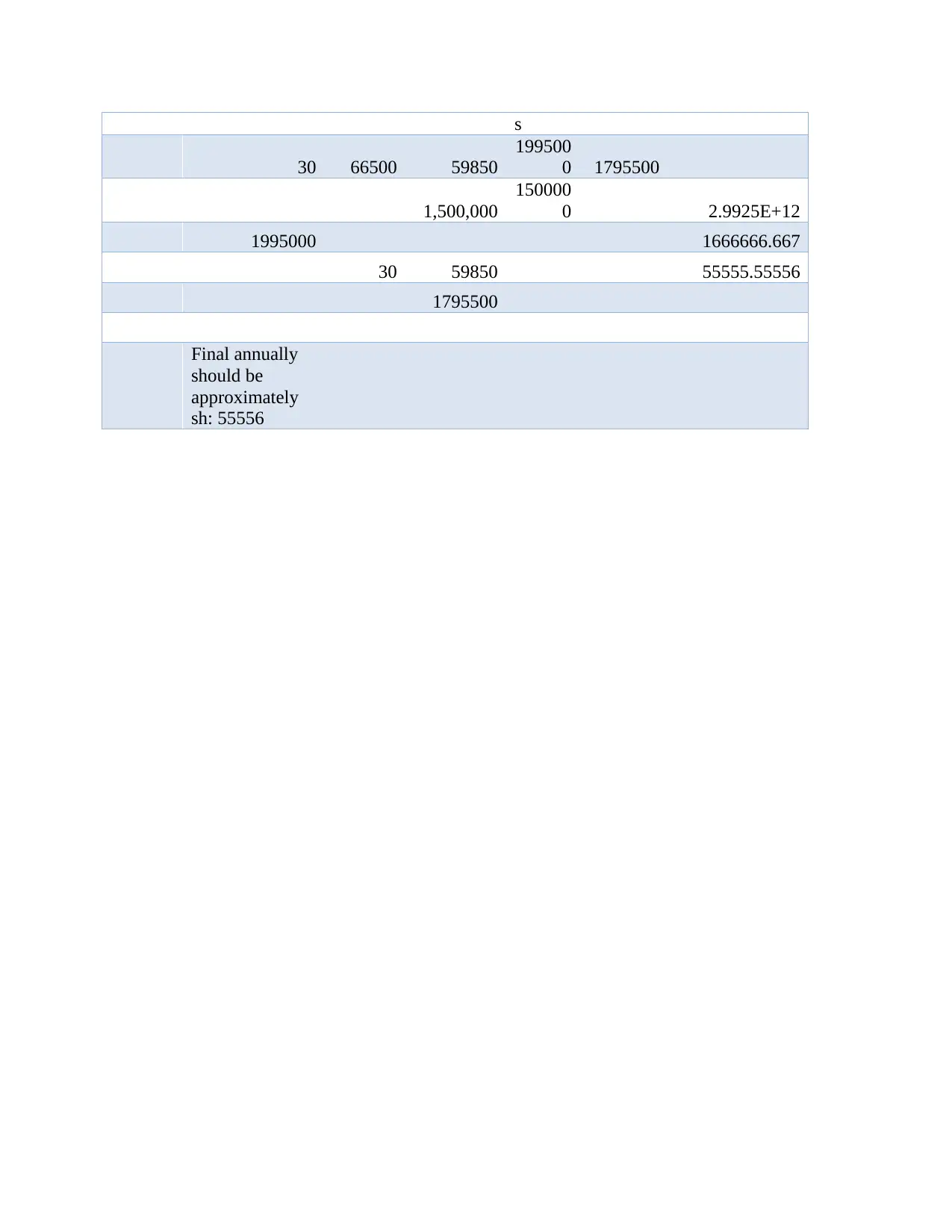
This assignment delves into various data analysis and classification methods, encompassing both theoretical understanding and practical application. The solution begins with an explanation of the confusion matrix in classification, providing an example of its interpretation. It then explores the applications of classification methods within a specific discipline, emphasizing their importance. The assignment further examines techniques like environment-driven and application-driven approaches, along with the application of logistic regression. Quantitative questions involve the k-nearest neighbors (KNN) algorithm, statistical analysis using Excel XLSTAT, and discriminant analysis. The solution includes step-by-step processes, interpretations of statistical outputs, and recommendations based on the data analysis. The assignment also covers data manipulation in Excel, including sorting, calculating averages, finding maximum and minimum values, and creating charts. Finally, the solution addresses a multiple linear regression model, including variable creation, model development, and interpretation of results, alongside a retirement account analysis and financial projections.





1 out of 10


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.