Statistics Assignment: Frequency, Regression Analysis & Solutions
VerifiedAdded on 2023/06/12
|8
|1563
|394
Homework Assignment
AI Summary
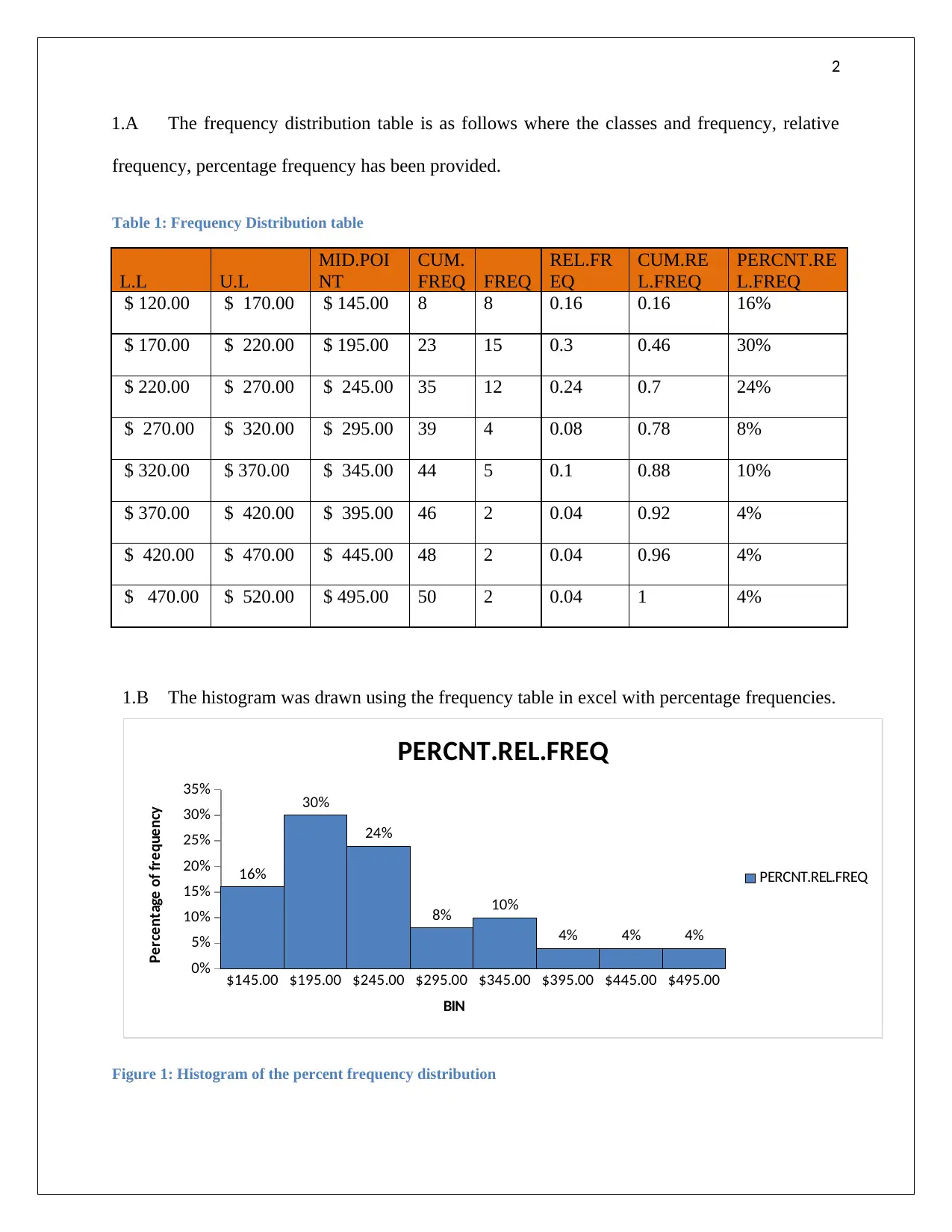
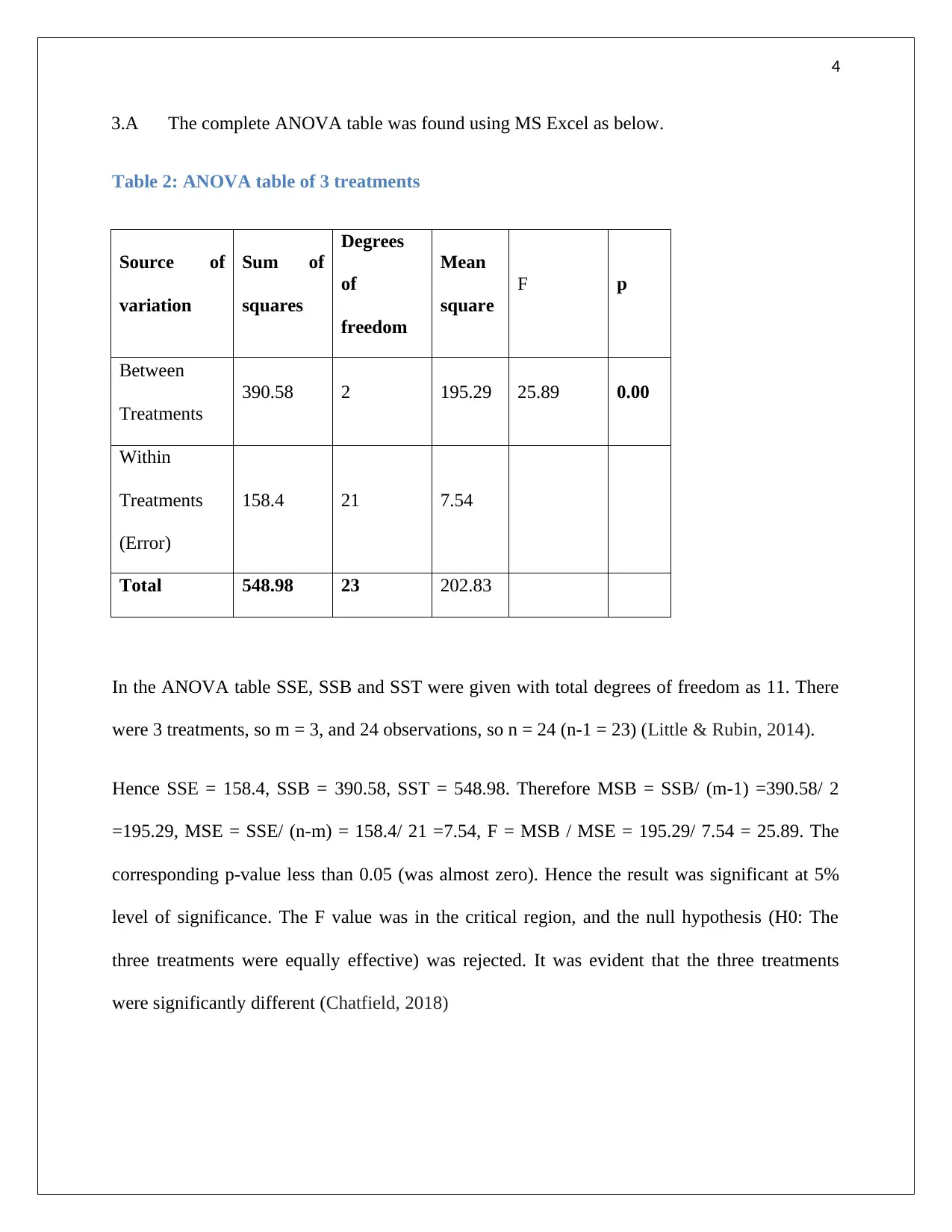
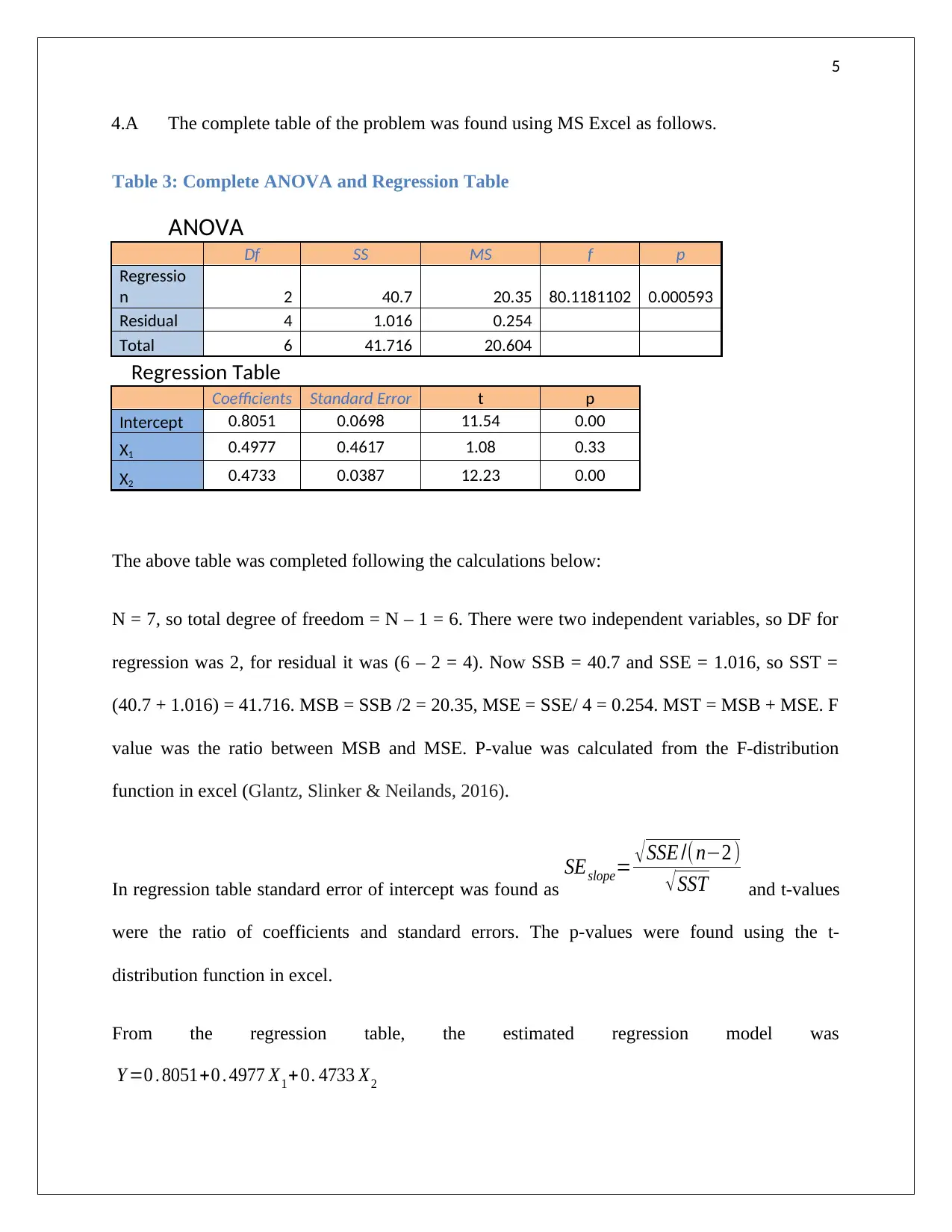
This assignment provides detailed solutions to selected statistical problems. It covers frequency distribution, including the creation of frequency, relative frequency, and percentage frequency tables, along with histogram construction and interpretation of skewness. The assignment also delves into regression analysis, presenting a regression equation to predict demand based on unit price, calculating the coefficient of determination, and interpreting the correlation coefficient. Furthermore, it includes a complete ANOVA table analysis for three treatments, hypothesis testing, and regression coefficient analysis. The document concludes with the application of the regression equation to predict phone sales based on given independent variables. Desklib offers a wealth of similar solved assignments and past papers to aid students in their studies.





1 out of 8

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.