Statistics for Business (STA101): Assessment 1 Assignment Solution
VerifiedAdded on 2023/06/04
|7
|1370
|145
Homework Assignment
AI Summary
This document presents a comprehensive solution to a statistics assessment (STA101) designed for business students. The solution includes detailed calculations and interpretations for each question. Question 1 addresses the calculation and interpretation of covariance and correlation between two variables (experience and salary), including a scatter plot and analysis of the relationship. Question 2 explores the application of the exponential distribution, calculating probabilities related to waiting times. Question 3 involves hypothesis testing, including null and alternative hypotheses, Z-tests, confidence intervals, and the power of a statistical test. Finally, Question 4 provides a hypothesis test example with a Z-test and confidence interval analysis, determining whether there is enough statistical support to reject the null hypothesis. All answers are supported by relevant formulas and explanations.

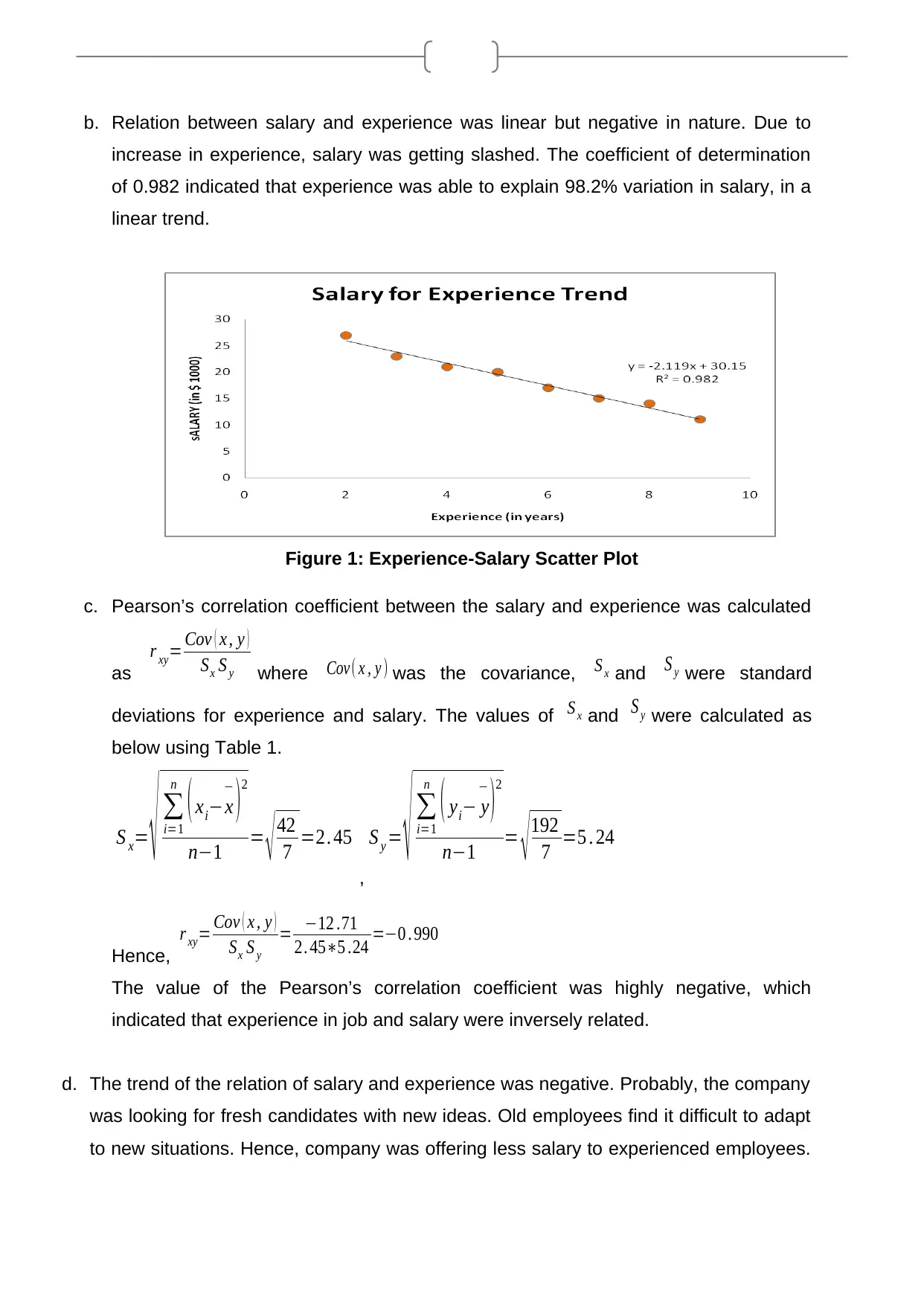




1 out of 7
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.