Statistics Assignment: Analyzing Household Data and Statistics
VerifiedAdded on 2023/06/07
|11
|2091
|354
Homework Assignment
AI Summary
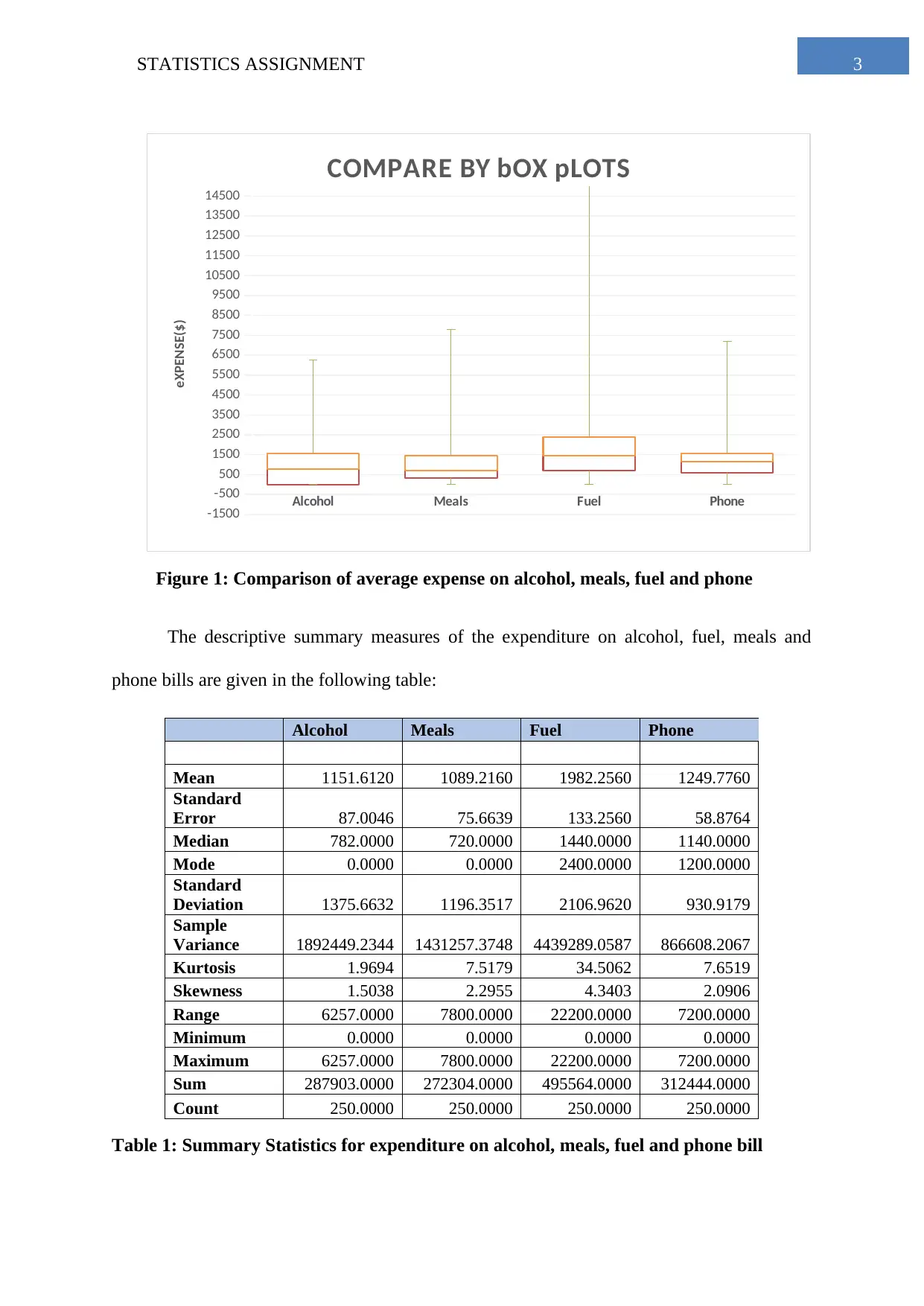
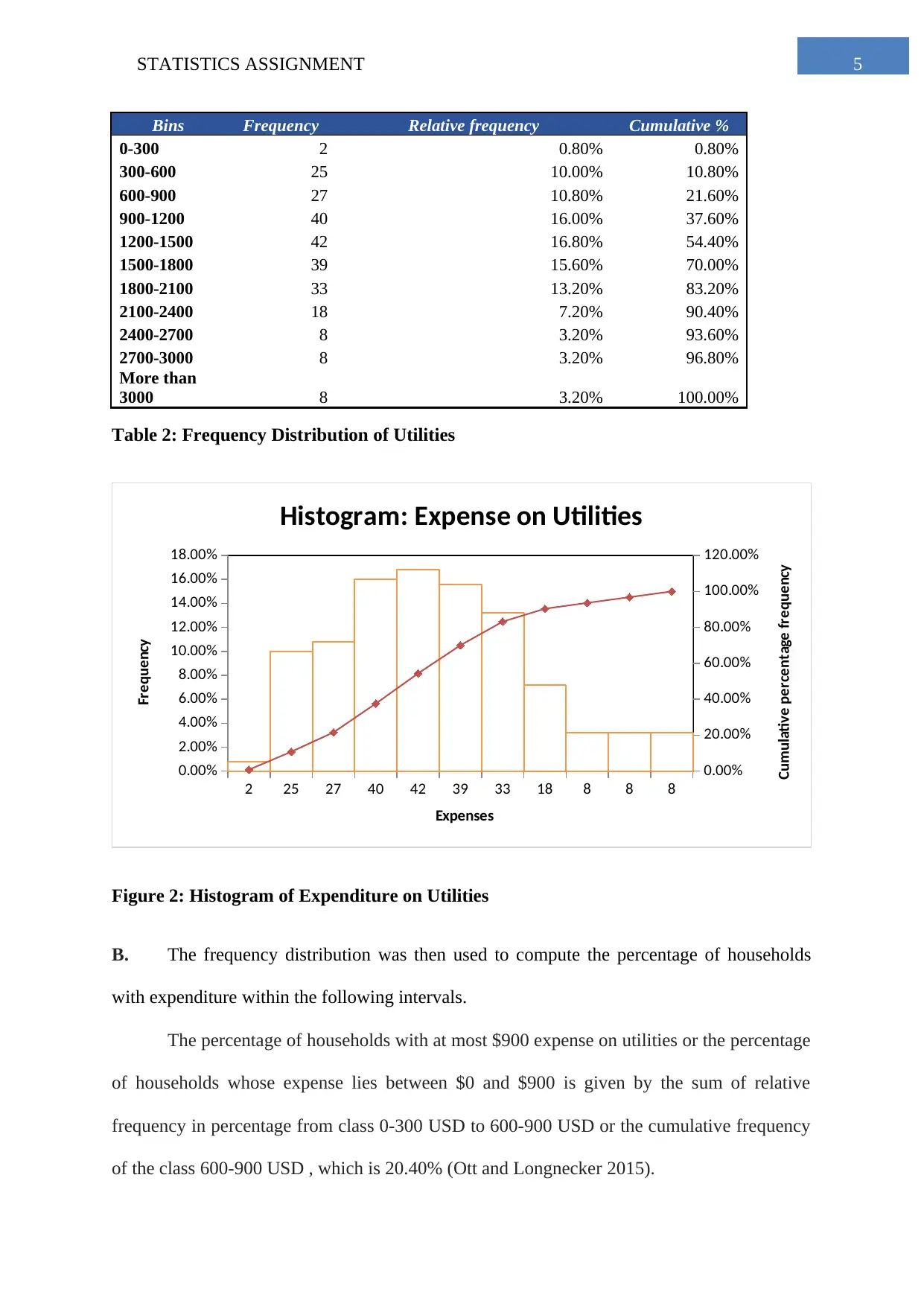
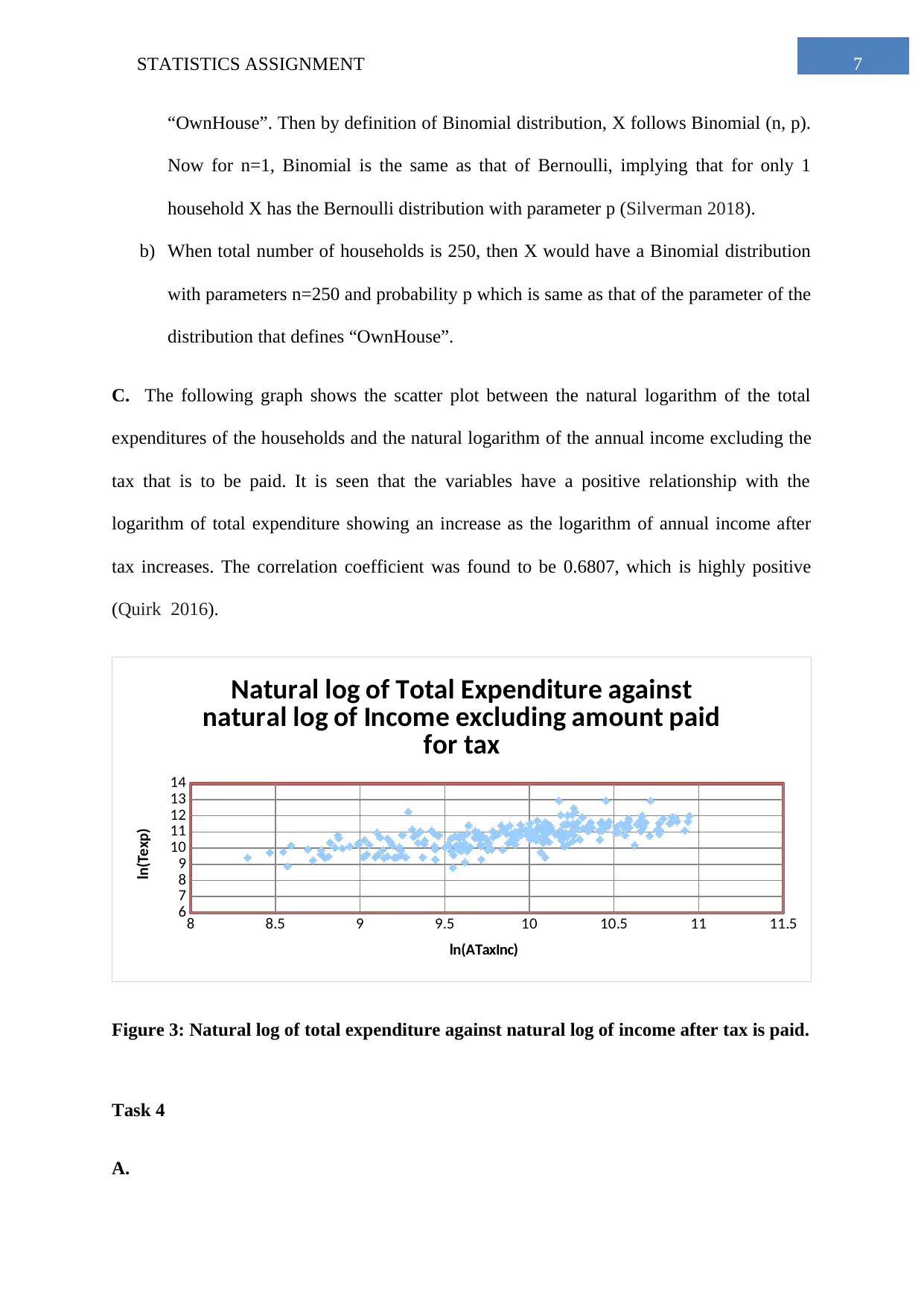
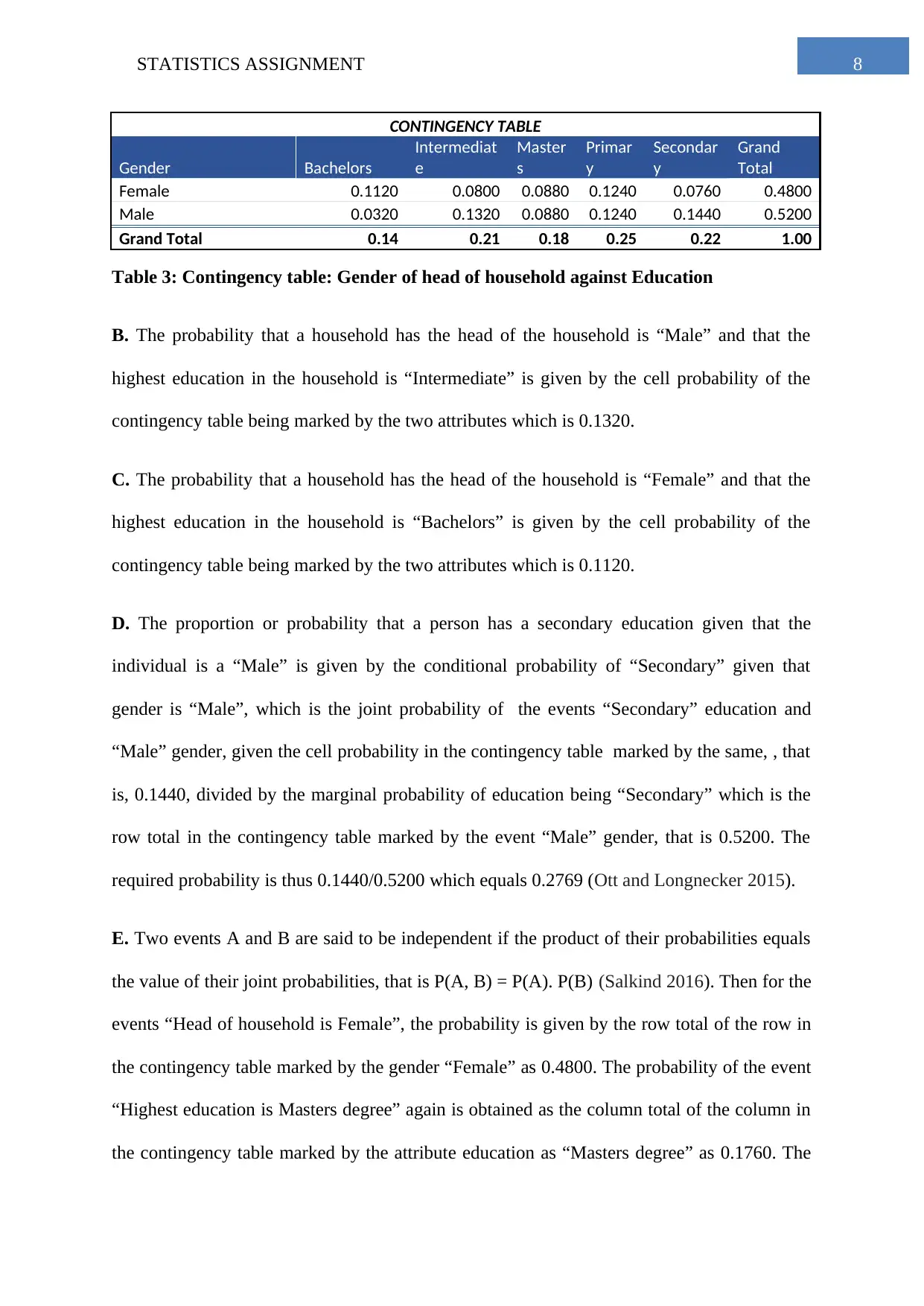
This statistics assignment analyzes household data, starting with a simple random sample of 250 households from a dataset of 2000. Task 1 explores descriptive statistics of household expenditures on various items like fuel, alcohol, and phone bills, using box plots and summary tables to compare spending patterns. Task 2 focuses on frequency distributions of utility expenses, including histograms and relative frequency calculations. Task 3 delves into percentiles of annual income and explores the binomial distribution related to homeownership. It also examines the relationship between total expenditure and income using a scatter plot and correlation analysis. Task 4 uses a contingency table to analyze the relationship between the gender of the household head and the highest level of education, calculating probabilities and assessing independence between events.







1 out of 11
Related Documents



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.