MBALN 603 Statistics Examination 2: Confidence Intervals & Testing
VerifiedAdded on 2023/06/10
|9
|1532
|122
Homework Assignment
AI Summary
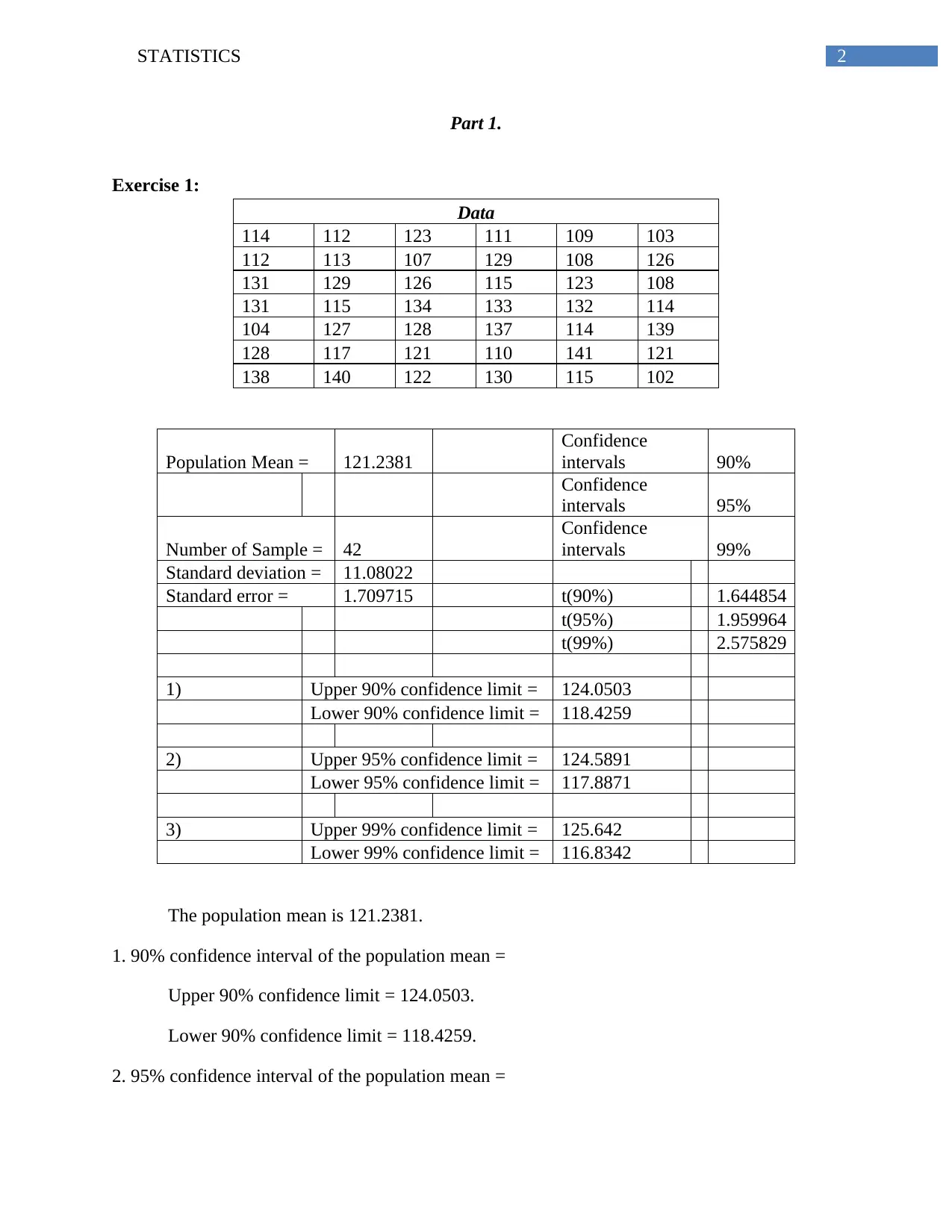
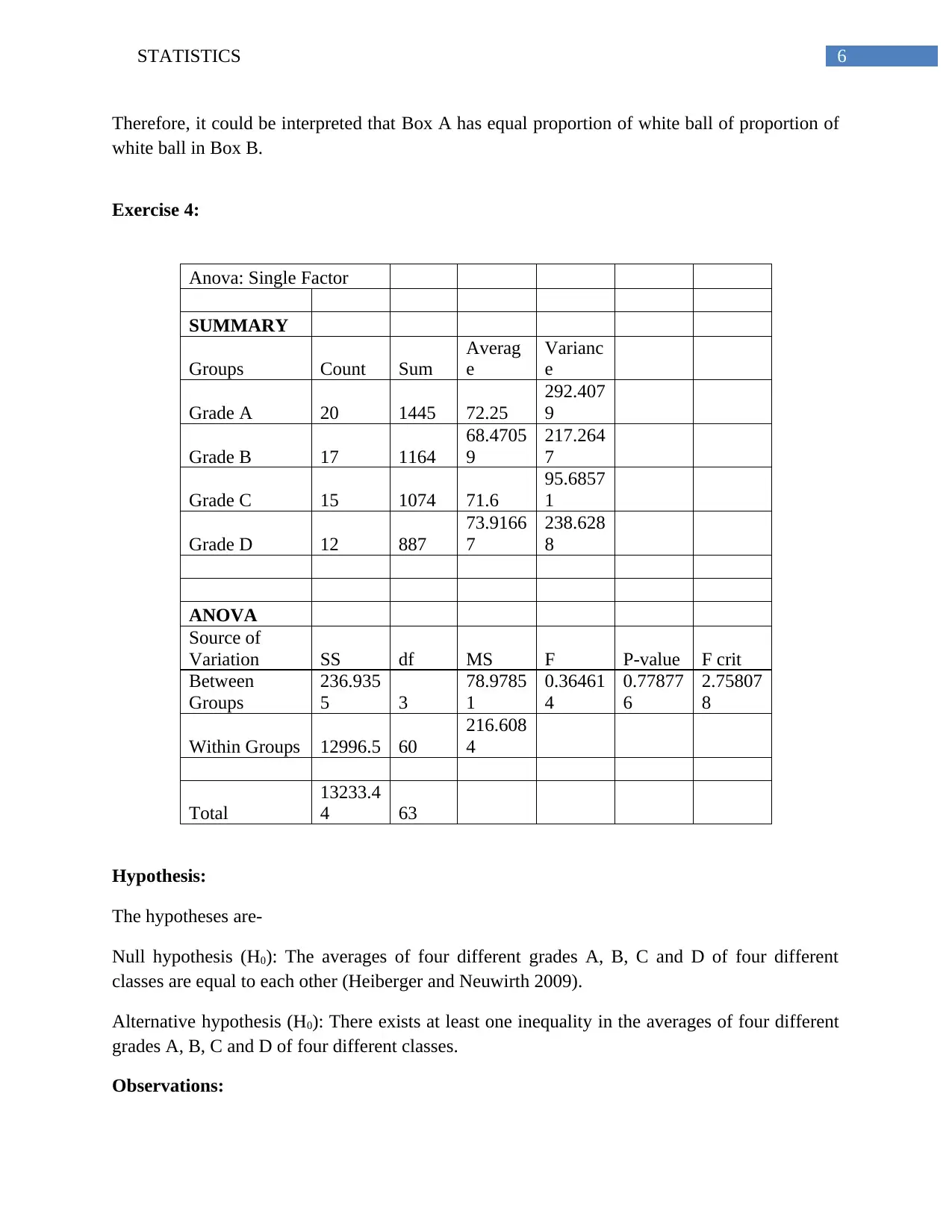
This assignment focuses on statistical analysis, including the construction and interpretation of confidence intervals for population means and hypothesis testing. Exercise 1 involves calculating 90%, 95%, and 99% confidence intervals for a given dataset, emphasizing the assumptions required for their construction, such as independence, normality, and the absence of significant outliers. Exercise 2 repeats this process with a different dataset. Exercise 3 tests the hypothesis concerning the proportions of white balls in two boxes using a two-sample proportional Z-test, determining whether the proportion in Box A is significantly greater than in Box B. Finally, Exercise 4 uses a one-way ANOVA to determine if the averages of grades from four different classes are equal, interpreting the F-statistic and p-value relative to a 5% significance level, ultimately concluding whether the null hypothesis can be rejected. The assignment includes relevant statistical references.







1 out of 9
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.