HI6007 Statistics for Business Decisions Final Assessment, T1 2021
VerifiedAdded on 2022/11/24
|19
|3413
|199
Homework Assignment
AI Summary
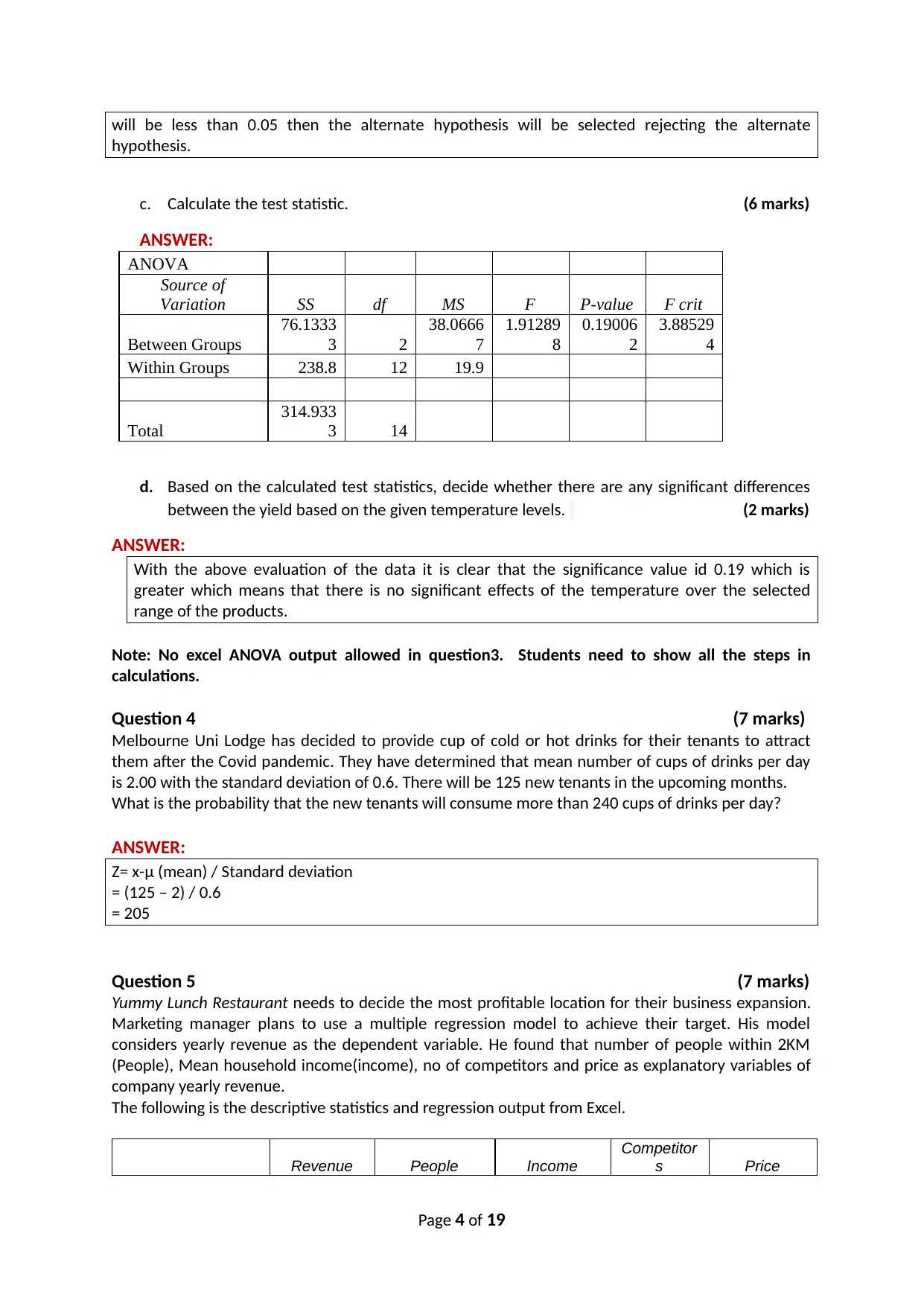
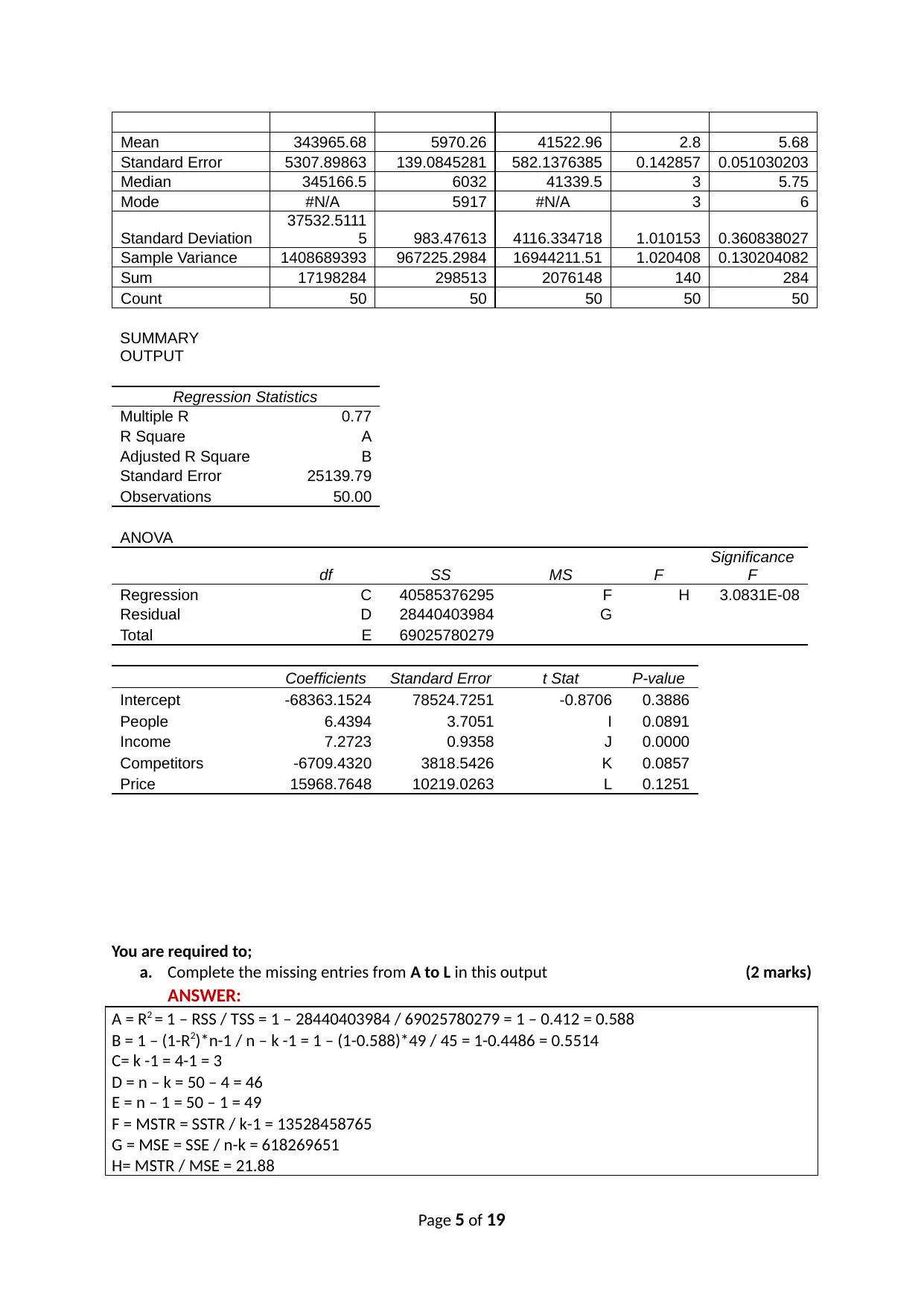
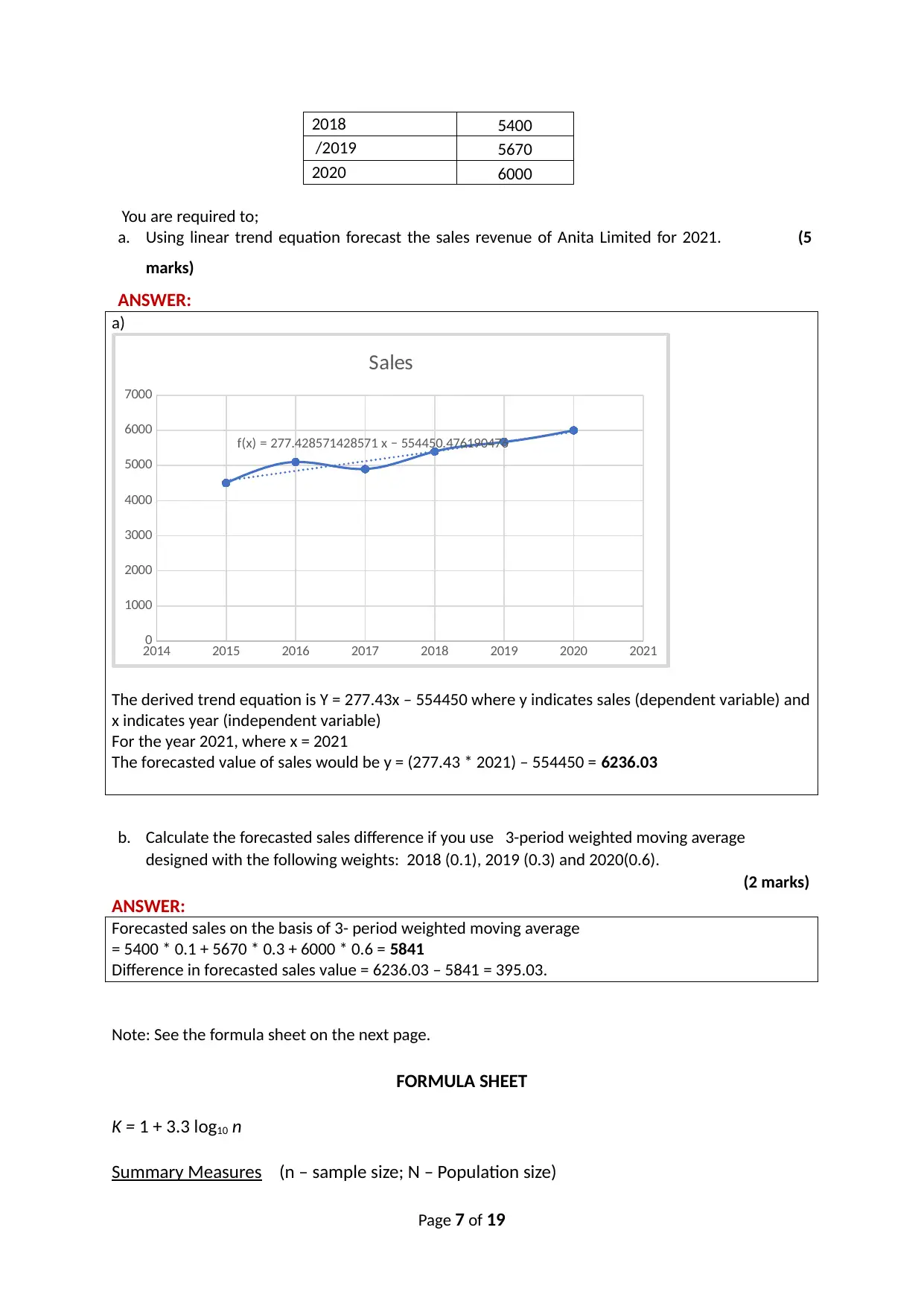
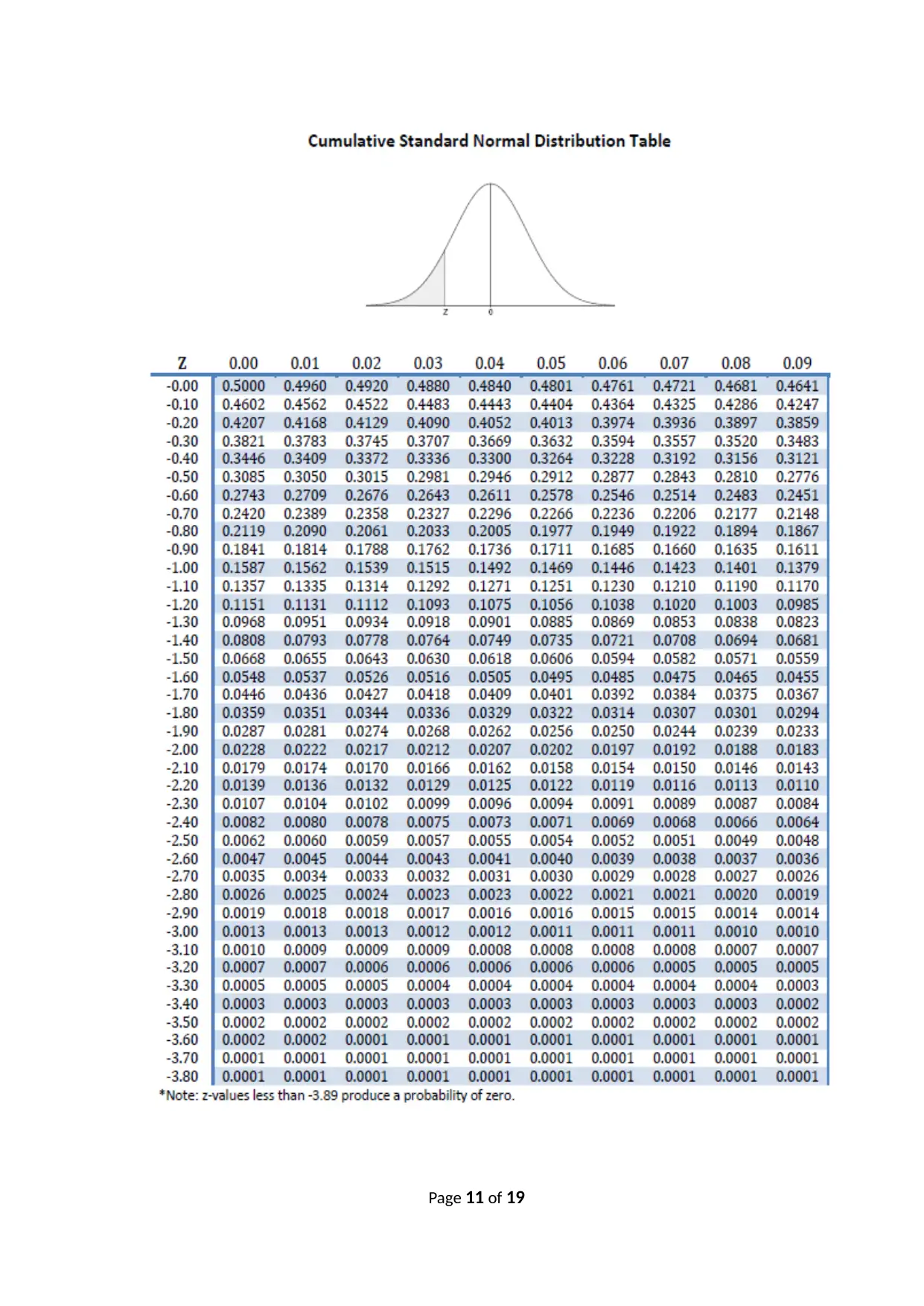
This document presents a comprehensive solution to the HI6007 Statistics for Business Decisions final assignment. The assignment covers a range of statistical concepts, including data types and measurement scales, calculation of mean, variance, standard deviation, and geometric return, hypothesis testing, ANOVA, probability calculations, multiple regression analysis, and time series analysis. The solution provides detailed answers, calculations, and interpretations for each question, demonstrating a strong understanding of statistical principles and their application in business decision-making. The assignment includes step-by-step solutions, formulas, and explanations to aid in understanding the concepts. The solution addresses real-world scenarios, such as evaluating course feedback, analyzing investment returns, assessing the feasibility of a recycling plant, examining the effect of temperature on agricultural products, determining drink consumption probability, deciding on the most profitable business location, and forecasting sales revenue.







1 out of 19
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.