Comprehensive Statistics Assignment: Data Analysis and Regression
VerifiedAdded on 2023/04/20
|11
|1566
|448
Homework Assignment
AI Summary
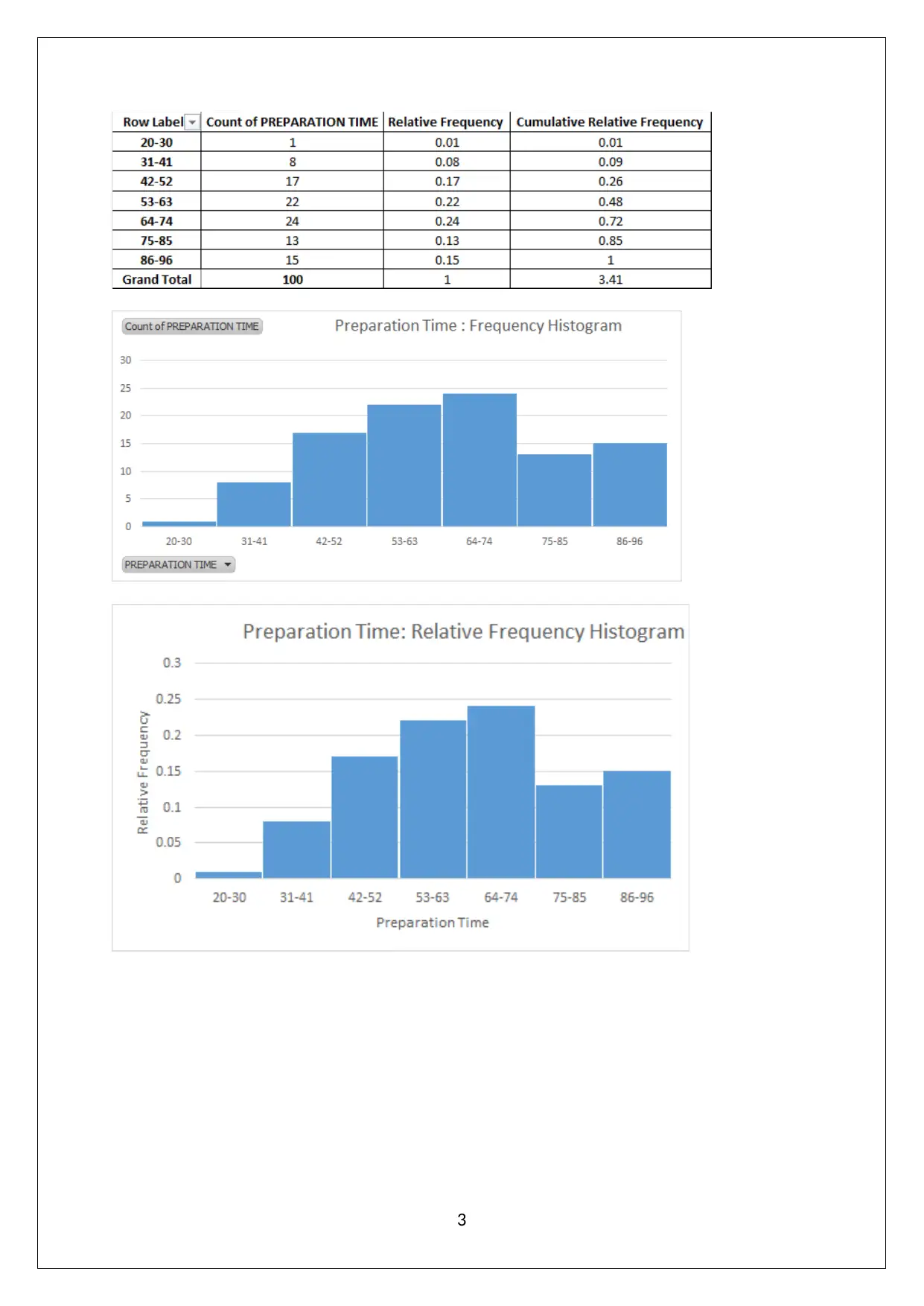
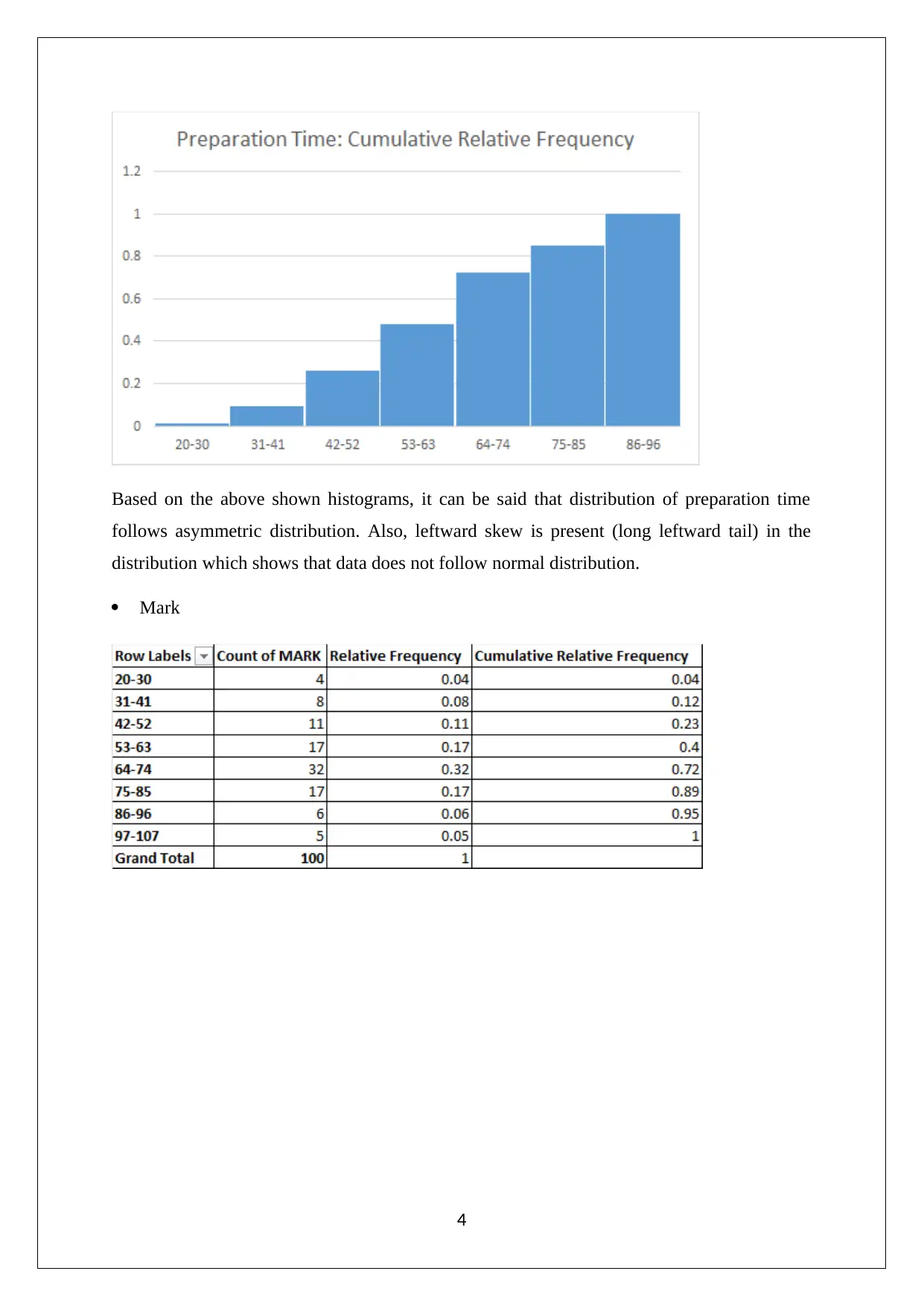
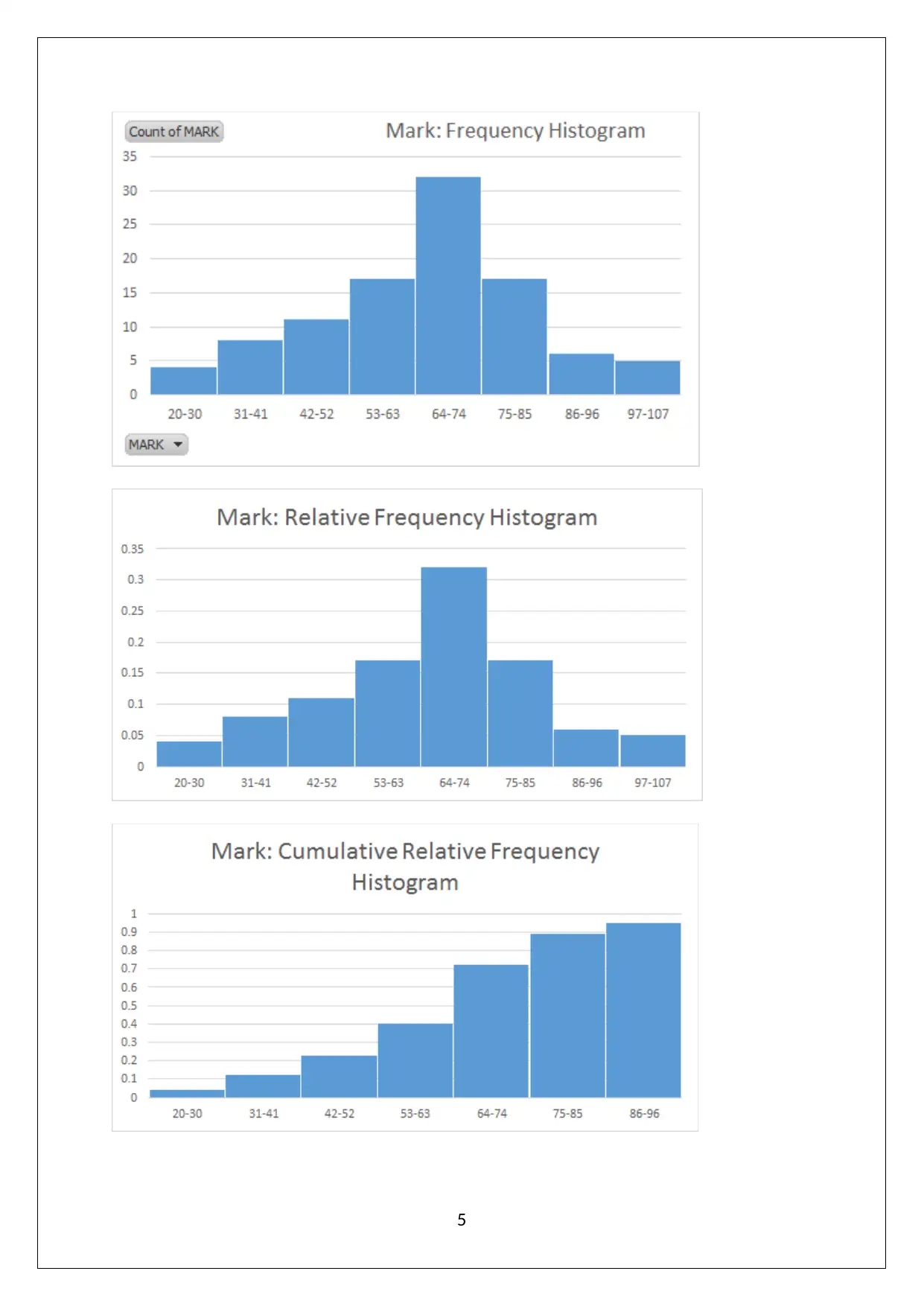
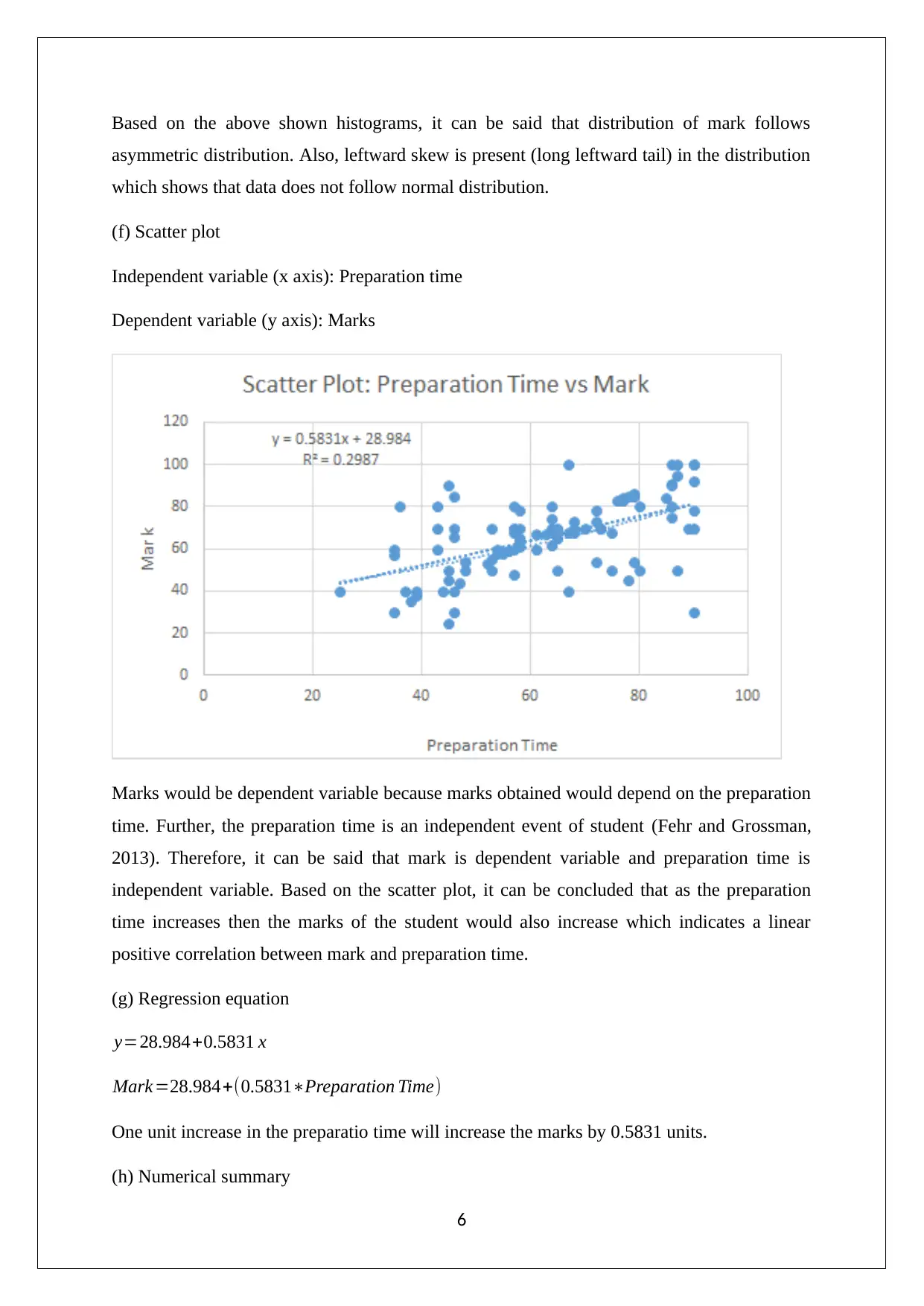
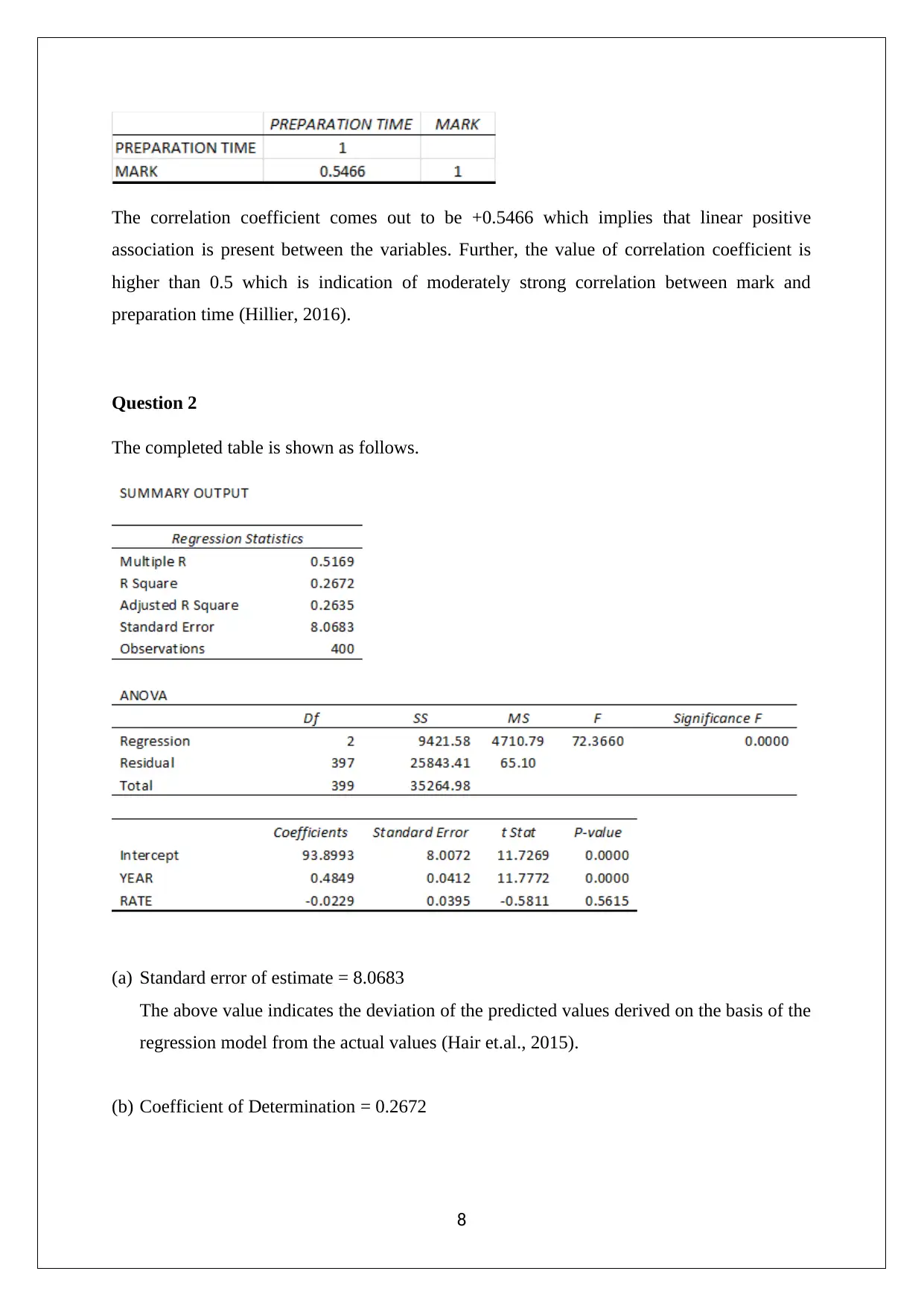
This statistics assignment solution provides a detailed analysis of data collection methods, focusing on the suitability of online surveys and stratified random sampling. It explores the relationship between preparation time and exam scores, identifying independent and dependent variables and discussing potential data collection issues. The solution includes frequency distributions and histograms to visualize data, scatter plots to assess correlations, and regression equations to model the relationship between variables. Furthermore, it covers hypothesis testing, standard error of estimate, and coefficient of determination in the context of multiple regression analysis, interpreting slope coefficients and determining statistical significance. This assignment, available on Desklib, offers valuable insights into statistical methods and their application in analyzing real-world data.






1 out of 11
Related Documents



Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.