University of Southern Queensland STA2300 Assignment 2: Data Analysis
VerifiedAdded on 2023/06/04
|11
|1688
|443
Homework Assignment
AI Summary
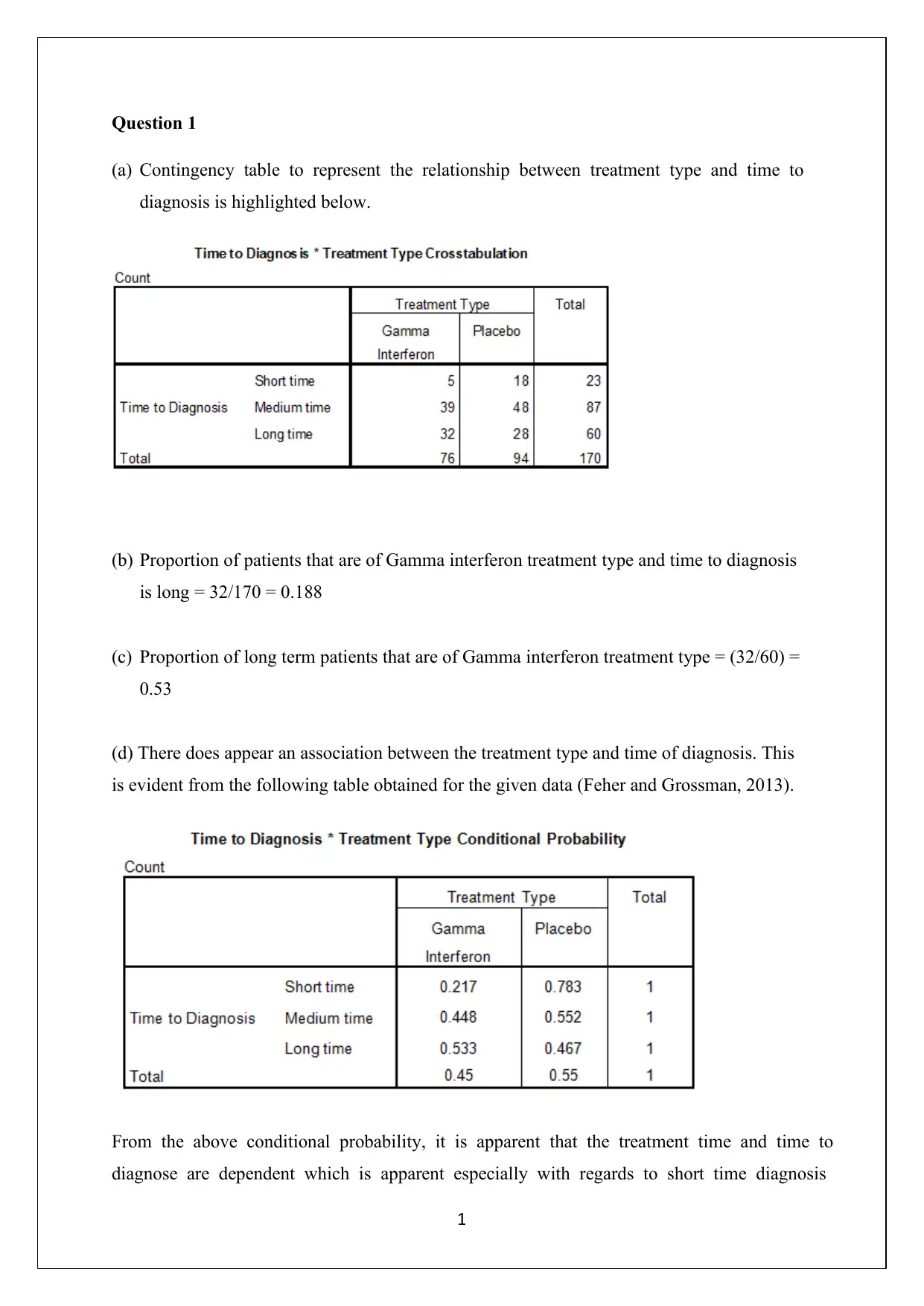
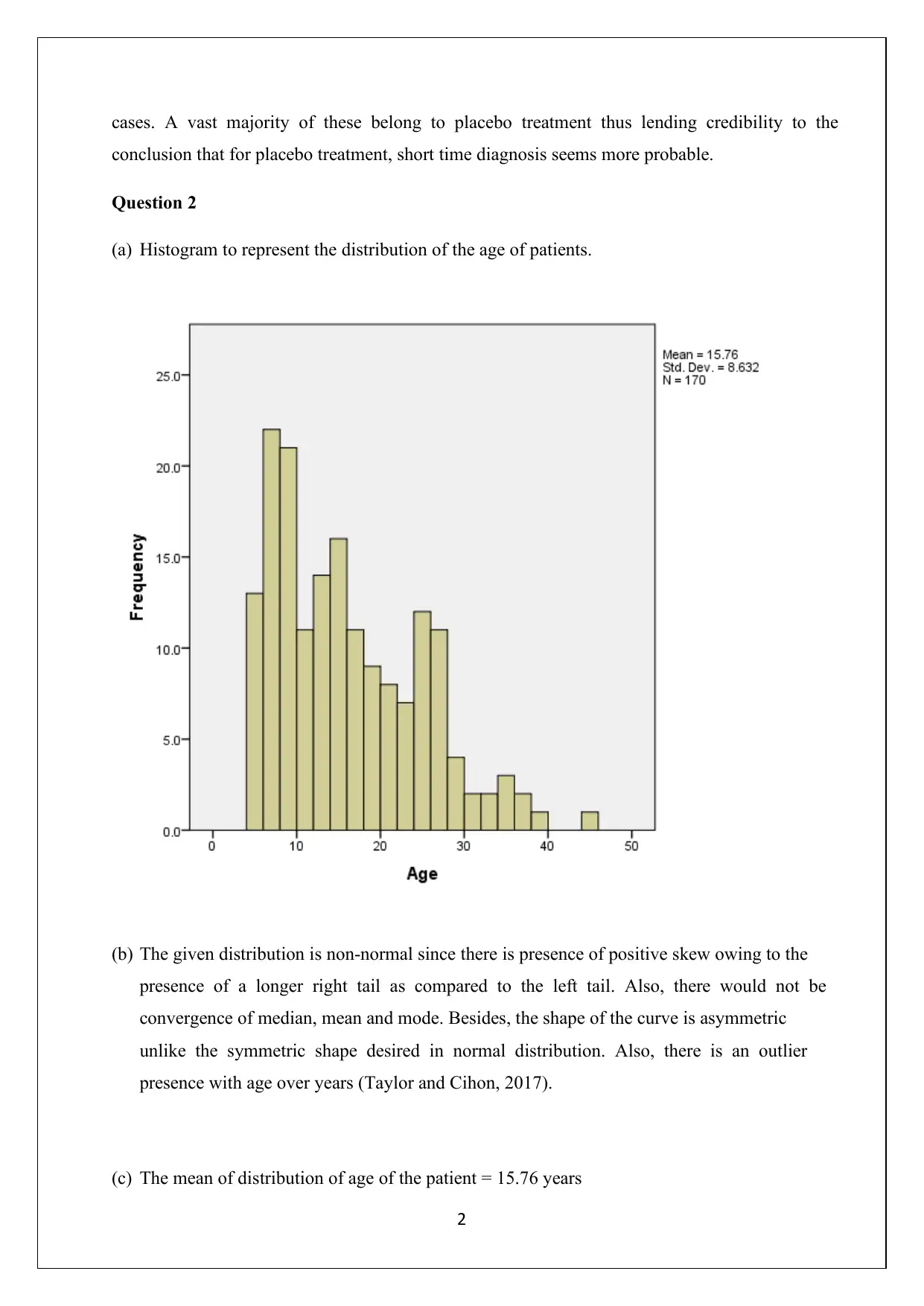
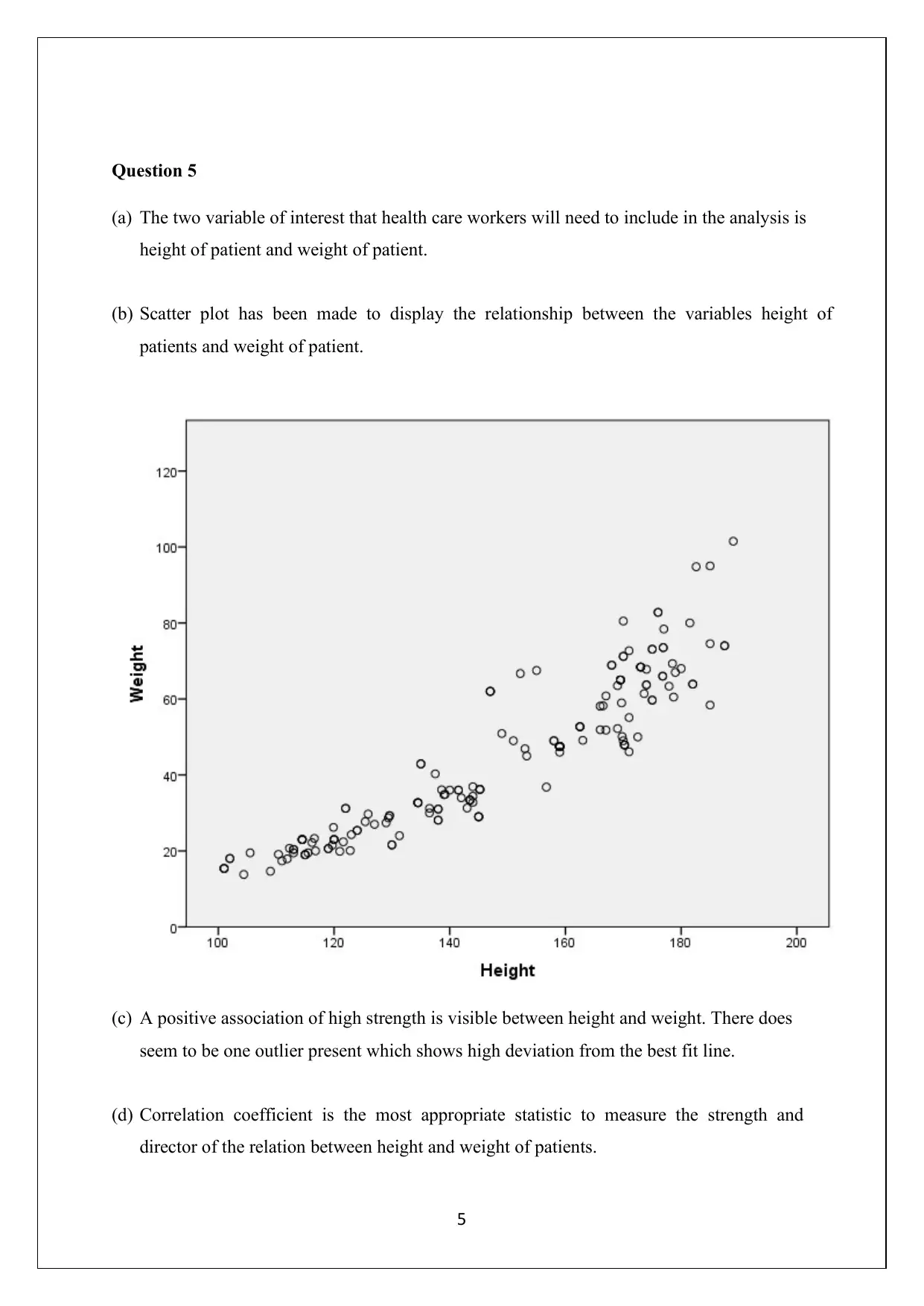
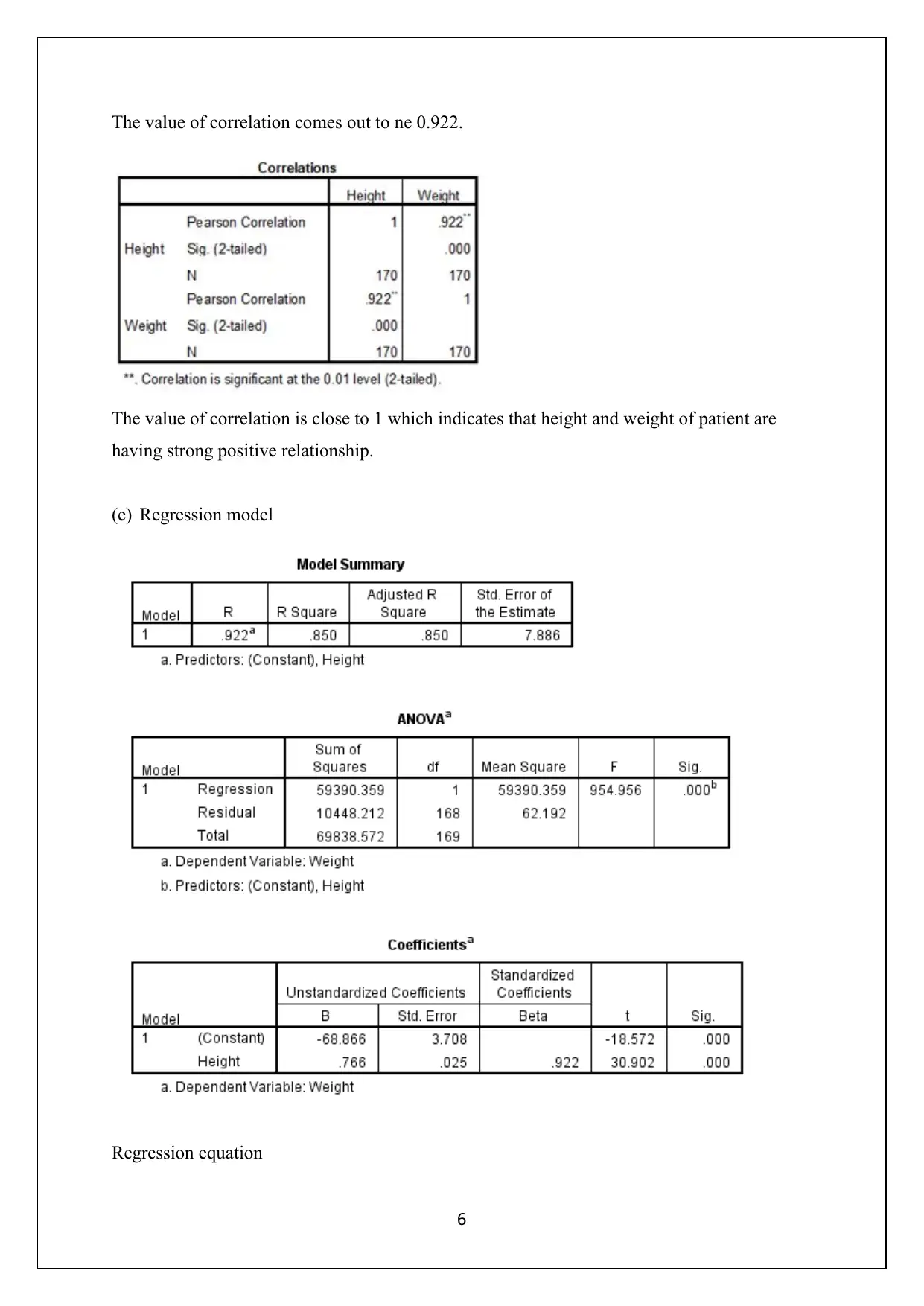
This document presents the complete solutions to STA2300 Assignment 2, a data analysis assignment from the University of Southern Queensland. The solutions cover a range of statistical concepts, including contingency tables, proportions, histograms, and measures of central tendency and dispersion. It delves into experimental study design, identifying variables, and applying statistical principles. Furthermore, the assignment explores probability calculations, Z-scores, and the application of binomial distributions, along with their approximation to normal distributions. The analysis includes correlation and regression analysis, calculating correlation coefficients, and interpreting regression equations and R-squared values. The document provides detailed explanations, calculations, and interpretations for each question, demonstrating a strong understanding of statistical methods and their practical application. The assignment also includes references to relevant statistical texts.







1 out of 11
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.