STAT100: Exploring Bike Sharing Trends Through Statistical Analysis
VerifiedAdded on 2023/04/24
|7
|970
|418
Homework Assignment
AI Summary
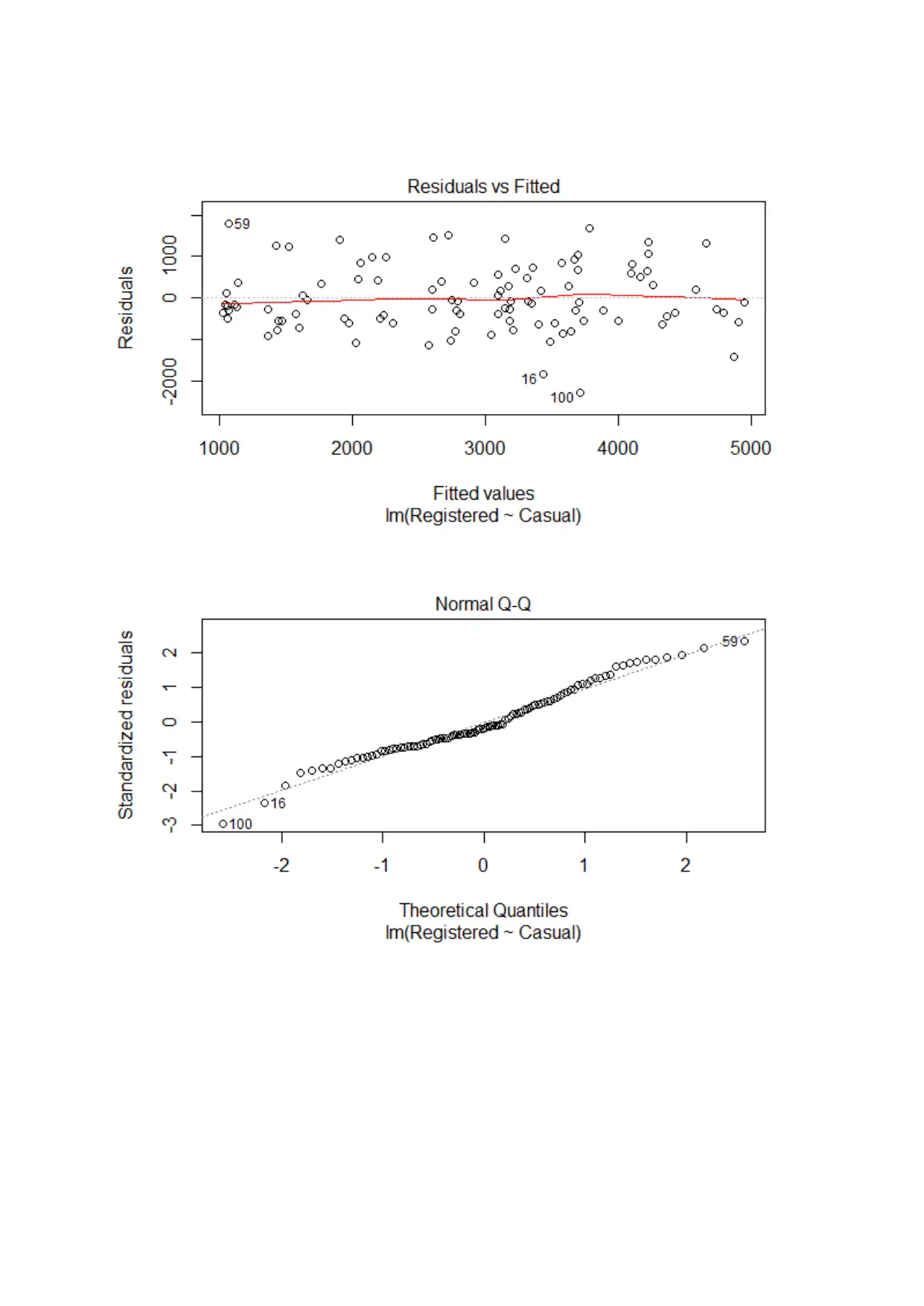
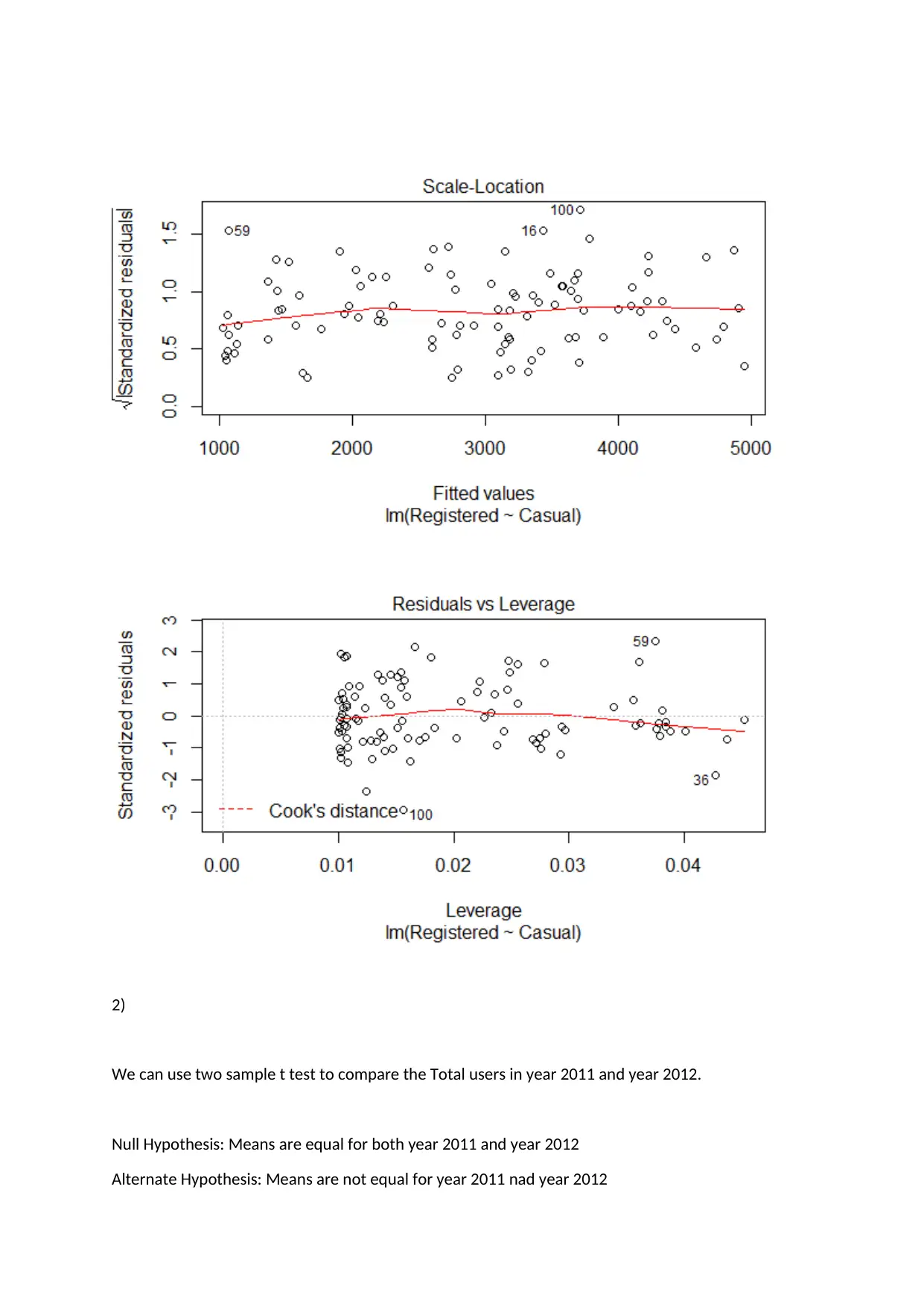
This assignment solution focuses on analyzing bike sharing data using various statistical methods. It includes a simple linear regression analysis examining the relationship between registered and casual users, a two-sample t-test comparing total users in 2011 and 2012, and a one-way ANOVA to assess differences in total users across different seasons. The regression analysis reveals a significant dependence of registered users on casual users. The t-test demonstrates a significant difference in total users between the two years. The ANOVA test indicates that total users vary significantly across different seasons, particularly in winter. The solution provides detailed interpretations of the statistical outputs and includes the R code used for the analysis. Desklib offers a platform where students can find similar solved assignments and past papers for their academic needs.





1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.