Iris Dataset Classification
VerifiedAdded on 2020/05/28
|20
|1581
|387
AI Summary
This assignment focuses on classifying iris flower species (setosa, versicolor, virginica) using a Decision Tree algorithm. The provided output details the construction of the decision tree, including splitting criteria based on sepal length, sepal width, petal length, and petal width. Performance evaluation metrics like accuracy, Kappa statistic, Mean Absolute Error, and Root Mean Squared Error are presented. Stratified cross-validation results demonstrate the model's effectiveness with high classification rates for each species.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Running Head: WEKA IN DATA ANALYSIS
WEKA in Data Analysis
Name of the Student
Name of the University
Author Note
WEKA in Data Analysis
Name of the Student
Name of the University
Author Note
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

1WEKA IN DATA ANALYSIS
Table of Contents
Introduction......................................................................................................................................2
K-Means Clustering.........................................................................................................................2
Table of Contents
Introduction......................................................................................................................................2
K-Means Clustering.........................................................................................................................2

2WEKA IN DATA ANALYSIS
Introduction
Weka is a software that is used for machine learning. There is a collection of tools
contained in weka which are used for the purpose of data visualization, analysis of the data and
predictive modelling. These functions can be easily accessed using weka graphical interfaces.
Four main techniques of data analysis tools are present in WEKA (Bouckaert et al., 2016).
WEKA is a freely available software and can be accessed easily.
The data analysis in this assignment will be done using the software WEKA. The Iris
dataset has been used for the purpose of data analysis.
K-Means Clustering
At first, k-means clustering analysis has been done using weka. K-means clustering
categorizes the data points into different groups. There is a specific algorithm according to which
k-means clusteing is conducted (Jain, Aalam and Doja 2014). The algorithm is described as
follows:
The k points are initialized randomly, which is known as the mean.
Each of the items are grouped according to their closest means and the means are thus
updated based on the data points included in that category.
This process is repeated for a given number of times and the end of all the adjustments,
the clusters will be formed.
The clusters for the dataset IRIS involving sepal length in the x axis and petal length is y axis are
shown with the help of the following diagram. 7 Iterations were required for this clustering
problem. The results are attached in the appendices.
Introduction
Weka is a software that is used for machine learning. There is a collection of tools
contained in weka which are used for the purpose of data visualization, analysis of the data and
predictive modelling. These functions can be easily accessed using weka graphical interfaces.
Four main techniques of data analysis tools are present in WEKA (Bouckaert et al., 2016).
WEKA is a freely available software and can be accessed easily.
The data analysis in this assignment will be done using the software WEKA. The Iris
dataset has been used for the purpose of data analysis.
K-Means Clustering
At first, k-means clustering analysis has been done using weka. K-means clustering
categorizes the data points into different groups. There is a specific algorithm according to which
k-means clusteing is conducted (Jain, Aalam and Doja 2014). The algorithm is described as
follows:
The k points are initialized randomly, which is known as the mean.
Each of the items are grouped according to their closest means and the means are thus
updated based on the data points included in that category.
This process is repeated for a given number of times and the end of all the adjustments,
the clusters will be formed.
The clusters for the dataset IRIS involving sepal length in the x axis and petal length is y axis are
shown with the help of the following diagram. 7 Iterations were required for this clustering
problem. The results are attached in the appendices.
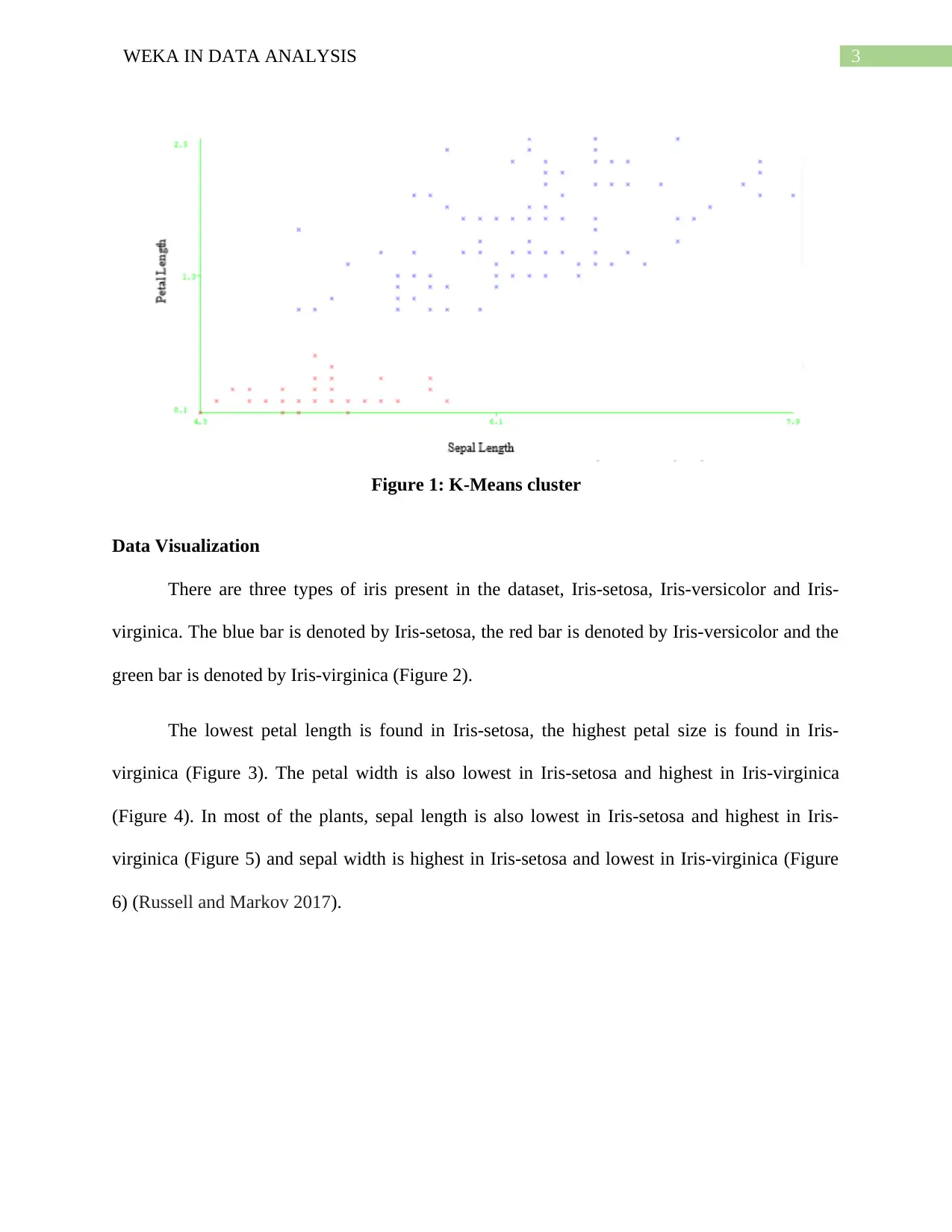
3WEKA IN DATA ANALYSIS
Figure 1: K-Means cluster
Data Visualization
There are three types of iris present in the dataset, Iris-setosa, Iris-versicolor and Iris-
virginica. The blue bar is denoted by Iris-setosa, the red bar is denoted by Iris-versicolor and the
green bar is denoted by Iris-virginica (Figure 2).
The lowest petal length is found in Iris-setosa, the highest petal size is found in Iris-
virginica (Figure 3). The petal width is also lowest in Iris-setosa and highest in Iris-virginica
(Figure 4). In most of the plants, sepal length is also lowest in Iris-setosa and highest in Iris-
virginica (Figure 5) and sepal width is highest in Iris-setosa and lowest in Iris-virginica (Figure
6) (Russell and Markov 2017).
Figure 1: K-Means cluster
Data Visualization
There are three types of iris present in the dataset, Iris-setosa, Iris-versicolor and Iris-
virginica. The blue bar is denoted by Iris-setosa, the red bar is denoted by Iris-versicolor and the
green bar is denoted by Iris-virginica (Figure 2).
The lowest petal length is found in Iris-setosa, the highest petal size is found in Iris-
virginica (Figure 3). The petal width is also lowest in Iris-setosa and highest in Iris-virginica
(Figure 4). In most of the plants, sepal length is also lowest in Iris-setosa and highest in Iris-
virginica (Figure 5) and sepal width is highest in Iris-setosa and lowest in Iris-virginica (Figure
6) (Russell and Markov 2017).
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
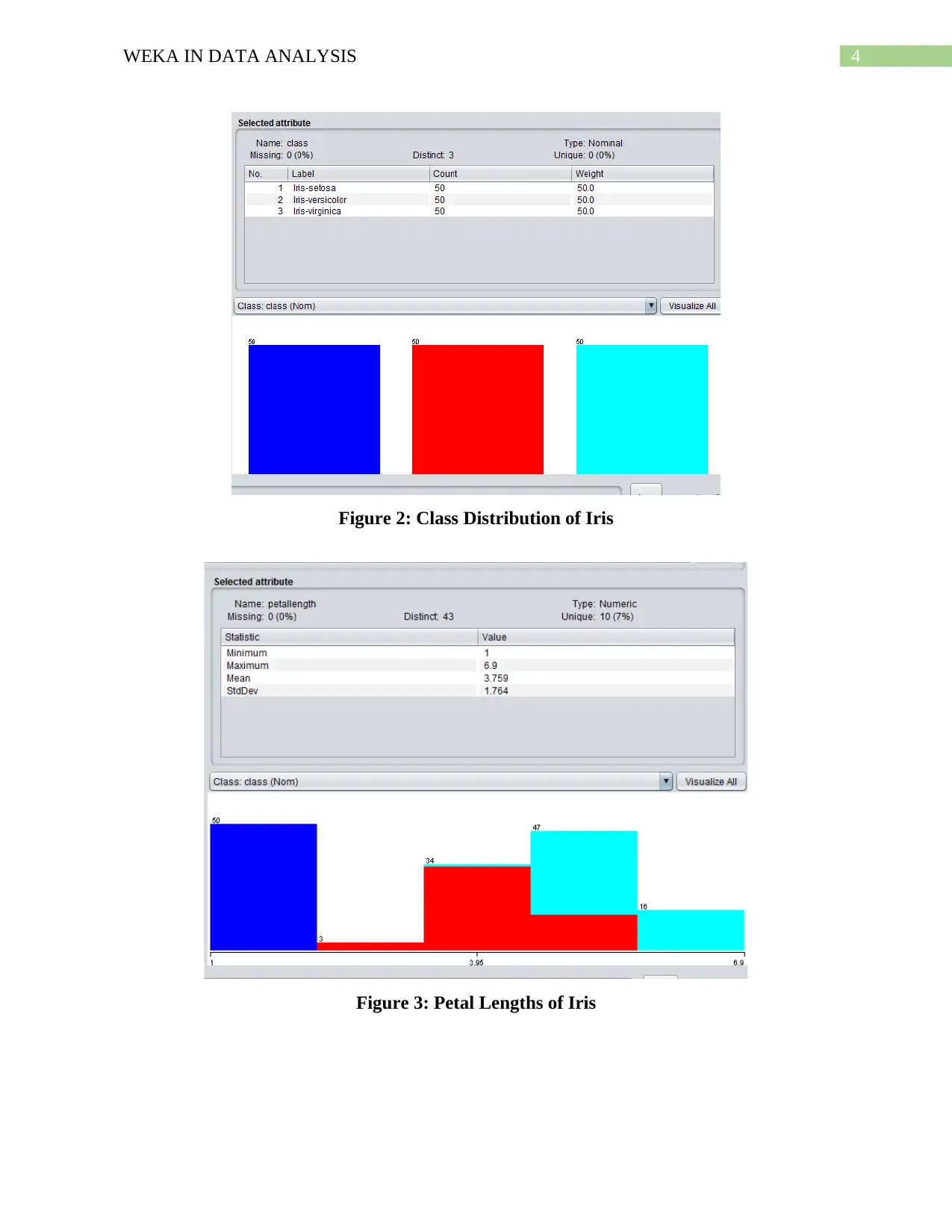
4WEKA IN DATA ANALYSIS
Figure 2: Class Distribution of Iris
Figure 3: Petal Lengths of Iris
Figure 2: Class Distribution of Iris
Figure 3: Petal Lengths of Iris
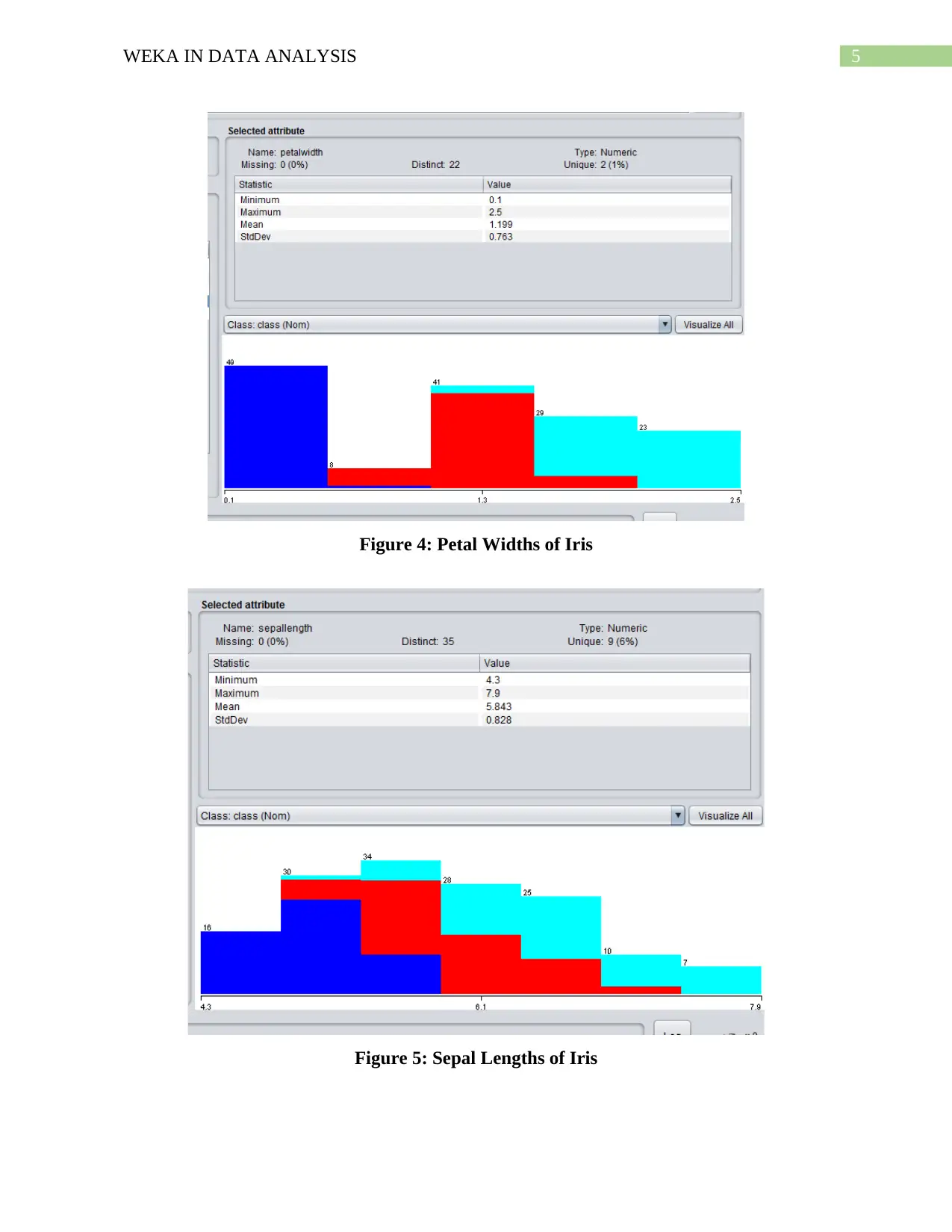
5WEKA IN DATA ANALYSIS
Figure 4: Petal Widths of Iris
Figure 5: Sepal Lengths of Iris
Figure 4: Petal Widths of Iris
Figure 5: Sepal Lengths of Iris
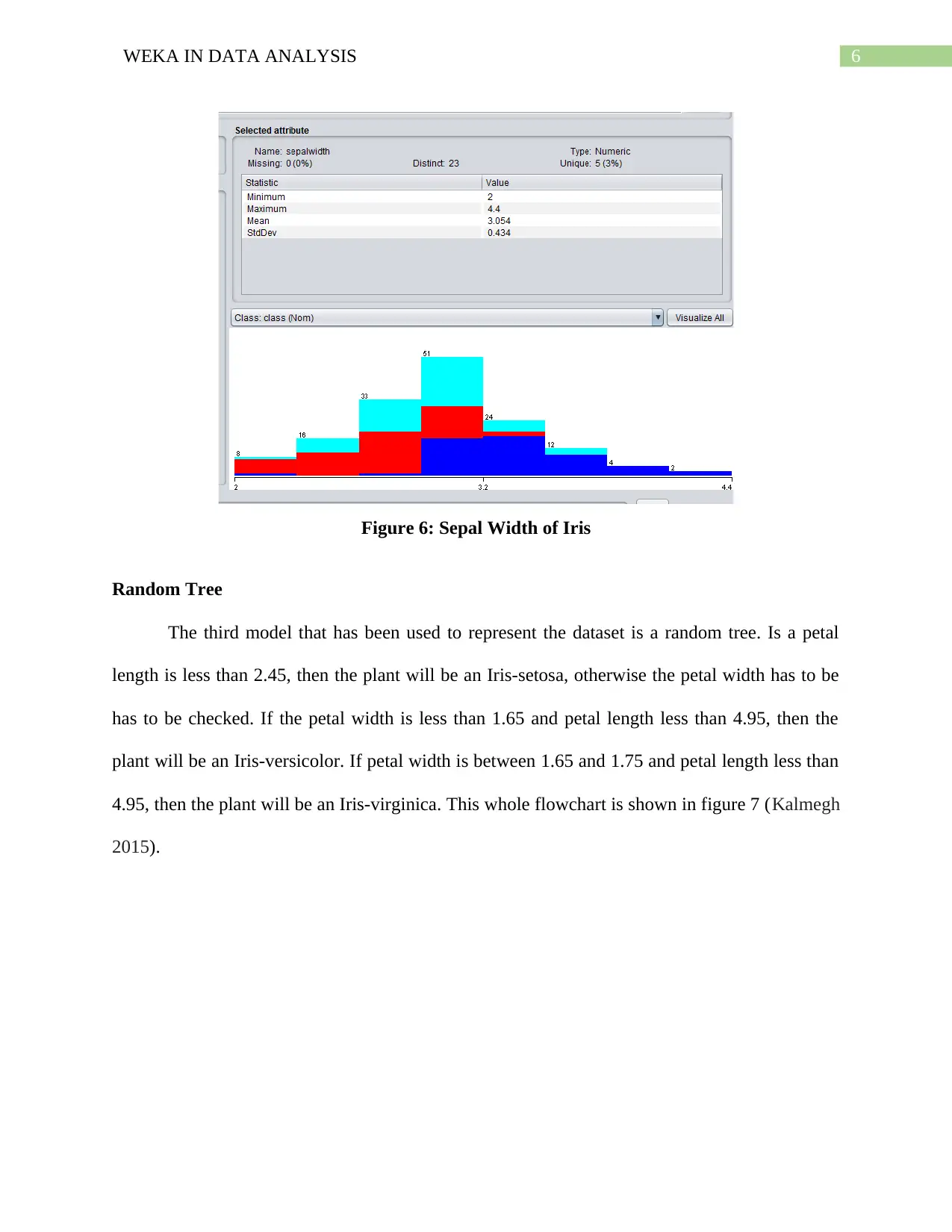
6WEKA IN DATA ANALYSIS
Figure 6: Sepal Width of Iris
Random Tree
The third model that has been used to represent the dataset is a random tree. Is a petal
length is less than 2.45, then the plant will be an Iris-setosa, otherwise the petal width has to be
has to be checked. If the petal width is less than 1.65 and petal length less than 4.95, then the
plant will be an Iris-versicolor. If petal width is between 1.65 and 1.75 and petal length less than
4.95, then the plant will be an Iris-virginica. This whole flowchart is shown in figure 7 (Kalmegh
2015).
Figure 6: Sepal Width of Iris
Random Tree
The third model that has been used to represent the dataset is a random tree. Is a petal
length is less than 2.45, then the plant will be an Iris-setosa, otherwise the petal width has to be
has to be checked. If the petal width is less than 1.65 and petal length less than 4.95, then the
plant will be an Iris-versicolor. If petal width is between 1.65 and 1.75 and petal length less than
4.95, then the plant will be an Iris-virginica. This whole flowchart is shown in figure 7 (Kalmegh
2015).
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

7WEKA IN DATA ANALYSIS
Figure 7: Random Tree
Logistic Regression
From the logistic regression, the obtained coefficients give the weights of each of the
attributes before the attributes are added to produce the value of Iris-setosa or Iris-versicolor.
These coefficients will be used to identify Iris-setosa or Iris-versicolor from the values of the
coefficients (Fatemi, Kazemi and Poole 2016).
Figure 7: Random Tree
Logistic Regression
From the logistic regression, the obtained coefficients give the weights of each of the
attributes before the attributes are added to produce the value of Iris-setosa or Iris-versicolor.
These coefficients will be used to identify Iris-setosa or Iris-versicolor from the values of the
coefficients (Fatemi, Kazemi and Poole 2016).

8WEKA IN DATA ANALYSIS
References
Jain, S., Aalam, M.A. and Doja, M.N., 2014. K-means clustering using weka interface.
In Proceedings of the 4th National Conference (pp. 25-26).
Bouckaert, R.R., Frank, E., Hall, M., Kirkby, R., Reutemann, P., Seewald, A. and Scuse, D.,
2016. WEKA Manual for Version 3-6-14.
Russell, I. and Markov, Z., 2017, March. An Introduction to the Weka Data Mining System.
In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science
Education (pp. 742-742). ACM.
Kalmegh, S., 2015. Analysis of WEKA data mining algorithm REPTree, Simple CART and
RandomTree for classification of Indian news. International Journal of Innovative Science,
Engineering and Technology, 2(2), pp.438-46.
Fatemi, B., Kazemi, S.M. and Poole, D., 2016. A Learning Algorithm for Relational Logistic
Regression: Preliminary Results. arXiv preprint arXiv:1606.08531.
References
Jain, S., Aalam, M.A. and Doja, M.N., 2014. K-means clustering using weka interface.
In Proceedings of the 4th National Conference (pp. 25-26).
Bouckaert, R.R., Frank, E., Hall, M., Kirkby, R., Reutemann, P., Seewald, A. and Scuse, D.,
2016. WEKA Manual for Version 3-6-14.
Russell, I. and Markov, Z., 2017, March. An Introduction to the Weka Data Mining System.
In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science
Education (pp. 742-742). ACM.
Kalmegh, S., 2015. Analysis of WEKA data mining algorithm REPTree, Simple CART and
RandomTree for classification of Indian news. International Journal of Innovative Science,
Engineering and Technology, 2(2), pp.438-46.
Fatemi, B., Kazemi, S.M. and Poole, D., 2016. A Learning Algorithm for Relational Logistic
Regression: Preliminary Results. arXiv preprint arXiv:1606.08531.

9WEKA IN DATA ANALYSIS
Appendices
K-means clustering
=== Run information ===
Scheme: weka.clusterers.SimpleKMeans -init 0 -max-candidates 100 -periodic-pruning
10000 -min-density 2.0 -t1 -1.25 -t2 -1.0 -N 2 -A "weka.core.EuclideanDistance -R first-last" -I
500 -num-slots 1 -S 10
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: evaluate on training data
Appendices
K-means clustering
=== Run information ===
Scheme: weka.clusterers.SimpleKMeans -init 0 -max-candidates 100 -periodic-pruning
10000 -min-density 2.0 -t1 -1.25 -t2 -1.0 -N 2 -A "weka.core.EuclideanDistance -R first-last" -I
500 -num-slots 1 -S 10
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: evaluate on training data
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

10WEKA IN DATA ANALYSIS
=== Clustering model (full training set) ===
kMeans
======
Number of iterations: 7
Within cluster sum of squared errors: 62.1436882815797
Initial starting points (random):
Cluster 0: 6.1,2.9,4.7,1.4,Iris-versicolor
Cluster 1: 6.2,2.9,4.3,1.3,Iris-versicolor
Missing values globally replaced with mean/mode
Final cluster centroids:
Cluster#
=== Clustering model (full training set) ===
kMeans
======
Number of iterations: 7
Within cluster sum of squared errors: 62.1436882815797
Initial starting points (random):
Cluster 0: 6.1,2.9,4.7,1.4,Iris-versicolor
Cluster 1: 6.2,2.9,4.3,1.3,Iris-versicolor
Missing values globally replaced with mean/mode
Final cluster centroids:
Cluster#

11WEKA IN DATA ANALYSIS
Attribute Full Data 0 1
(150.0) (100.0) (50.0)
==================================================================
sepallength 5.8433 6.262 5.006
sepalwidth 3.054 2.872 3.418
petallength 3.7587 4.906 1.464
petalwidth 1.1987 1.676 0.244
class Iris-setosa Iris-versicolor Iris-setosa
Time taken to build model (full training data) : 0.02 seconds
=== Model and evaluation on training set ===
Clustered Instances
Attribute Full Data 0 1
(150.0) (100.0) (50.0)
==================================================================
sepallength 5.8433 6.262 5.006
sepalwidth 3.054 2.872 3.418
petallength 3.7587 4.906 1.464
petalwidth 1.1987 1.676 0.244
class Iris-setosa Iris-versicolor Iris-setosa
Time taken to build model (full training data) : 0.02 seconds
=== Model and evaluation on training set ===
Clustered Instances

12WEKA IN DATA ANALYSIS
0 100 ( 67%)
1 50 ( 33%)
Logistic Regression
=== Run information ===
Scheme: weka.classifiers.functions.Logistic -R 1.0E-8 -M -1 -num-decimal-places 4
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
0 100 ( 67%)
1 50 ( 33%)
Logistic Regression
=== Run information ===
Scheme: weka.classifiers.functions.Logistic -R 1.0E-8 -M -1 -num-decimal-places 4
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

13WEKA IN DATA ANALYSIS
Logistic Regression with ridge parameter of 1.0E-8
Coefficients...
Class
Variable Iris-setosa Iris-versicolor
===============================================
sepallength 21.8065 2.4652
sepalwidth 4.5648 6.6809
petallength -26.3083 -9.4293
petalwidth -43.887 -18.2859
Intercept 8.1743 42.637
Odds Ratios...
Class
Variable Iris-setosa Iris-versicolor
===============================================
sepallength 2954196659.8892 11.7653
sepalwidth 96.0426 797.0304
Logistic Regression with ridge parameter of 1.0E-8
Coefficients...
Class
Variable Iris-setosa Iris-versicolor
===============================================
sepallength 21.8065 2.4652
sepalwidth 4.5648 6.6809
petallength -26.3083 -9.4293
petalwidth -43.887 -18.2859
Intercept 8.1743 42.637
Odds Ratios...
Class
Variable Iris-setosa Iris-versicolor
===============================================
sepallength 2954196659.8892 11.7653
sepalwidth 96.0426 797.0304

14WEKA IN DATA ANALYSIS
petallength 0 0.0001
petalwidth 0 0
Time taken to build model: 0.13 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 144 96 %
Incorrectly Classified Instances 6 4 %
Kappa statistic 0.94
Mean absolute error 0.0287
Root mean squared error 0.1424
Relative absolute error 6.456 %
Root relative squared error 30.2139 %
Total Number of Instances 150
petallength 0 0.0001
petalwidth 0 0
Time taken to build model: 0.13 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 144 96 %
Incorrectly Classified Instances 6 4 %
Kappa statistic 0.94
Mean absolute error 0.0287
Root mean squared error 0.1424
Relative absolute error 6.456 %
Root relative squared error 30.2139 %
Total Number of Instances 150

15WEKA IN DATA ANALYSIS
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area
Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.920 0.020 0.958 0.920 0.939 0.910 0.970 0.933 Iris-versicolor
0.960 0.040 0.923 0.960 0.941 0.911 0.975 0.933 Iris-virginica
Weighted Avg. 0.960 0.020 0.960 0.960 0.960 0.940 0.982 0.955
=== Confusion Matrix ===
a b c <-- classified as
50 0 0 | a = Iris-setosa
0 46 4 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area
Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.920 0.020 0.958 0.920 0.939 0.910 0.970 0.933 Iris-versicolor
0.960 0.040 0.923 0.960 0.941 0.911 0.975 0.933 Iris-virginica
Weighted Avg. 0.960 0.020 0.960 0.960 0.960 0.940 0.982 0.955
=== Confusion Matrix ===
a b c <-- classified as
50 0 0 | a = Iris-setosa
0 46 4 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

16WEKA IN DATA ANALYSIS
RandomTree
=== Run information ===
Scheme: weka.classifiers.trees.RandomTree -K 0 -M 1.0 -V 0.001 -S 1
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
==========
petallength < 2.45 : Iris-setosa (50/0)
RandomTree
=== Run information ===
Scheme: weka.classifiers.trees.RandomTree -K 0 -M 1.0 -V 0.001 -S 1
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
==========
petallength < 2.45 : Iris-setosa (50/0)

17WEKA IN DATA ANALYSIS
petallength >= 2.45
| petalwidth < 1.75
| | petallength < 4.95
| | | petalwidth < 1.65 : Iris-versicolor (47/0)
| | | petalwidth >= 1.65 : Iris-virginica (1/0)
| | petallength >= 4.95
| | | petalwidth < 1.55 : Iris-virginica (3/0)
| | | petalwidth >= 1.55
| | | | sepallength < 6.95 : Iris-versicolor (2/0)
| | | | sepallength >= 6.95 : Iris-virginica (1/0)
| petalwidth >= 1.75
| | petallength < 4.85
| | | sepallength < 5.95 : Iris-versicolor (1/0)
| | | sepallength >= 5.95 : Iris-virginica (2/0)
| | petallength >= 4.85 : Iris-virginica (43/0)
Size of the tree : 17
petallength >= 2.45
| petalwidth < 1.75
| | petallength < 4.95
| | | petalwidth < 1.65 : Iris-versicolor (47/0)
| | | petalwidth >= 1.65 : Iris-virginica (1/0)
| | petallength >= 4.95
| | | petalwidth < 1.55 : Iris-virginica (3/0)
| | | petalwidth >= 1.55
| | | | sepallength < 6.95 : Iris-versicolor (2/0)
| | | | sepallength >= 6.95 : Iris-virginica (1/0)
| petalwidth >= 1.75
| | petallength < 4.85
| | | sepallength < 5.95 : Iris-versicolor (1/0)
| | | sepallength >= 5.95 : Iris-virginica (2/0)
| | petallength >= 4.85 : Iris-virginica (43/0)
Size of the tree : 17

18WEKA IN DATA ANALYSIS
Time taken to build model: 0 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 138 92 %
Incorrectly Classified Instances 12 8 %
Kappa statistic 0.88
Mean absolute error 0.0533
Root mean squared error 0.2309
Relative absolute error 12 %
Root relative squared error 48.9898 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area
Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
Time taken to build model: 0 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 138 92 %
Incorrectly Classified Instances 12 8 %
Kappa statistic 0.88
Mean absolute error 0.0533
Root mean squared error 0.2309
Relative absolute error 12 %
Root relative squared error 48.9898 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area
Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

19WEKA IN DATA ANALYSIS
0.860 0.050 0.896 0.860 0.878 0.819 0.905 0.817 Iris-versicolor
0.900 0.070 0.865 0.900 0.882 0.822 0.915 0.812 Iris-virginica
Weighted Avg. 0.920 0.040 0.920 0.920 0.920 0.880 0.940 0.876
=== Confusion Matrix ===
a b c <-- classified as
50 0 0 | a = Iris-setosa
0 43 7 | b = Iris-versicolor
0 5 45 | c = Iris-virginica
0.860 0.050 0.896 0.860 0.878 0.819 0.905 0.817 Iris-versicolor
0.900 0.070 0.865 0.900 0.882 0.822 0.915 0.812 Iris-virginica
Weighted Avg. 0.920 0.040 0.920 0.920 0.920 0.880 0.940 0.876
=== Confusion Matrix ===
a b c <-- classified as
50 0 0 | a = Iris-setosa
0 43 7 | b = Iris-versicolor
0 5 45 | c = Iris-virginica
1 out of 20
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.