ICT110 Introduction to Data Science: Health & Population Analysis
VerifiedAdded on 2023/06/12
|11
|2363
|271
Report
AI Summary
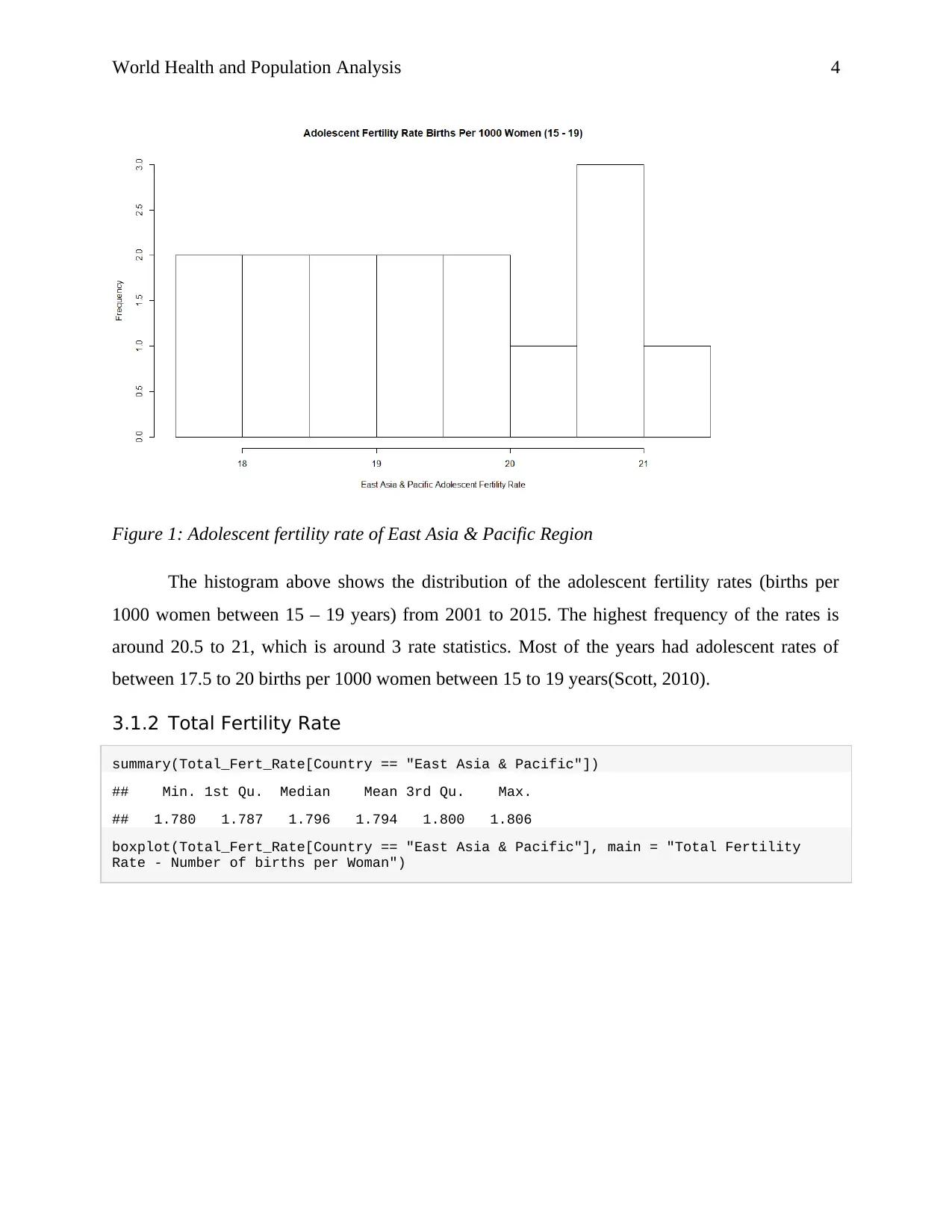
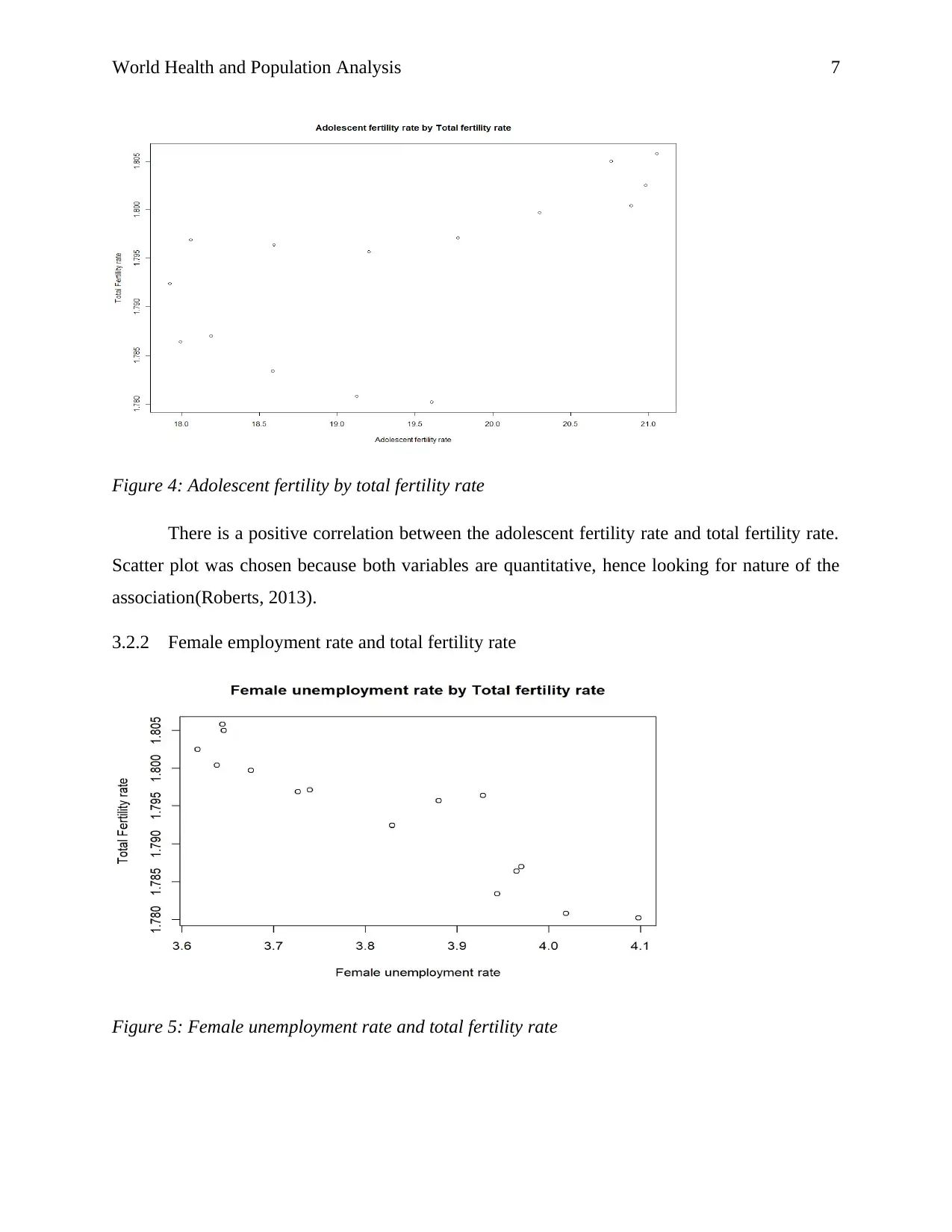
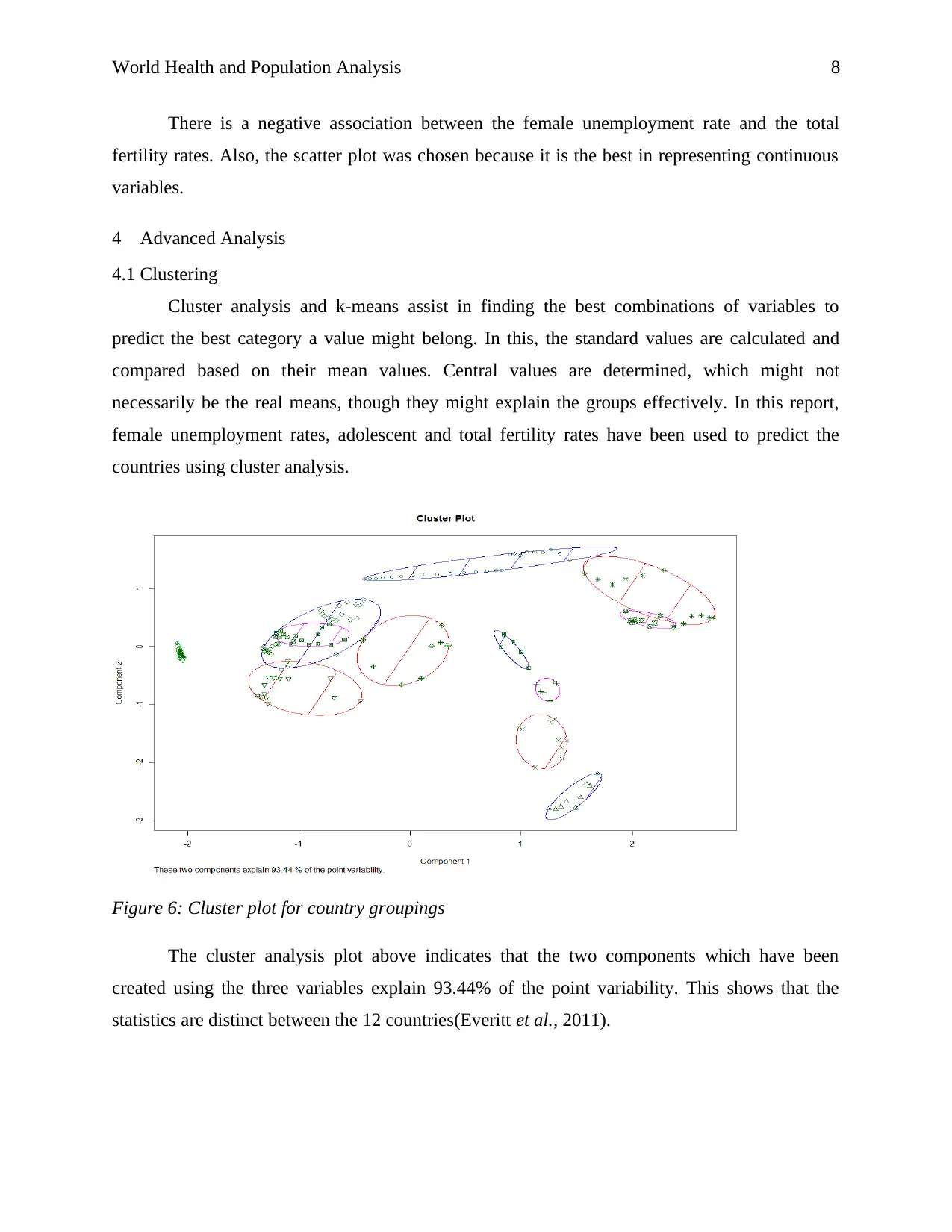
This report presents a data analysis of health and population statistics for East Asian and Pacific countries, focusing on health issues and factors affecting total fertility rates from 2001 to 2015. The analysis uses data from the World Bank development indicators database, processed with MS Excel and R software. Exploratory data analysis includes one-variable analysis of adolescent fertility rate, total fertility rate, and female unemployment rate, as well as two-variable analysis exploring correlations between these factors. Advanced analysis incorporates cluster analysis to group countries based on these variables and linear regression to model the relationships between adolescent fertility rate, female unemployment rate, and total fertility rate. The report concludes that adolescent fertility rates and female unemployment rates are significant predictors of total fertility rates, suggesting that governments should focus on increasing female employment and reducing adolescent fertility to decrease overall fertility rates.








1 out of 11
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.