Business Statistics Assignment - Sold Price Analysis Report
VerifiedAdded on 2019/11/19
|12
|1130
|436
Homework Assignment
AI Summary
This Business Statistics assignment analyzes a dataset related to sold house prices. It includes tasks involving data cleaning, frequency distributions, and descriptive statistics, such as calculating percentiles, quartiles, and interquartile ranges. The assignment explores measures of central tendency and dispersion, determines the suitability of mean versus median, and assesses the normality of the data. It also calculates confidence intervals for both the mean sold price and the proportion of brick veneer properties. The analysis considers skewness, kurtosis, and the impact of outliers on the data distribution. The student also makes assumptions about the sold price population data and validates the findings.


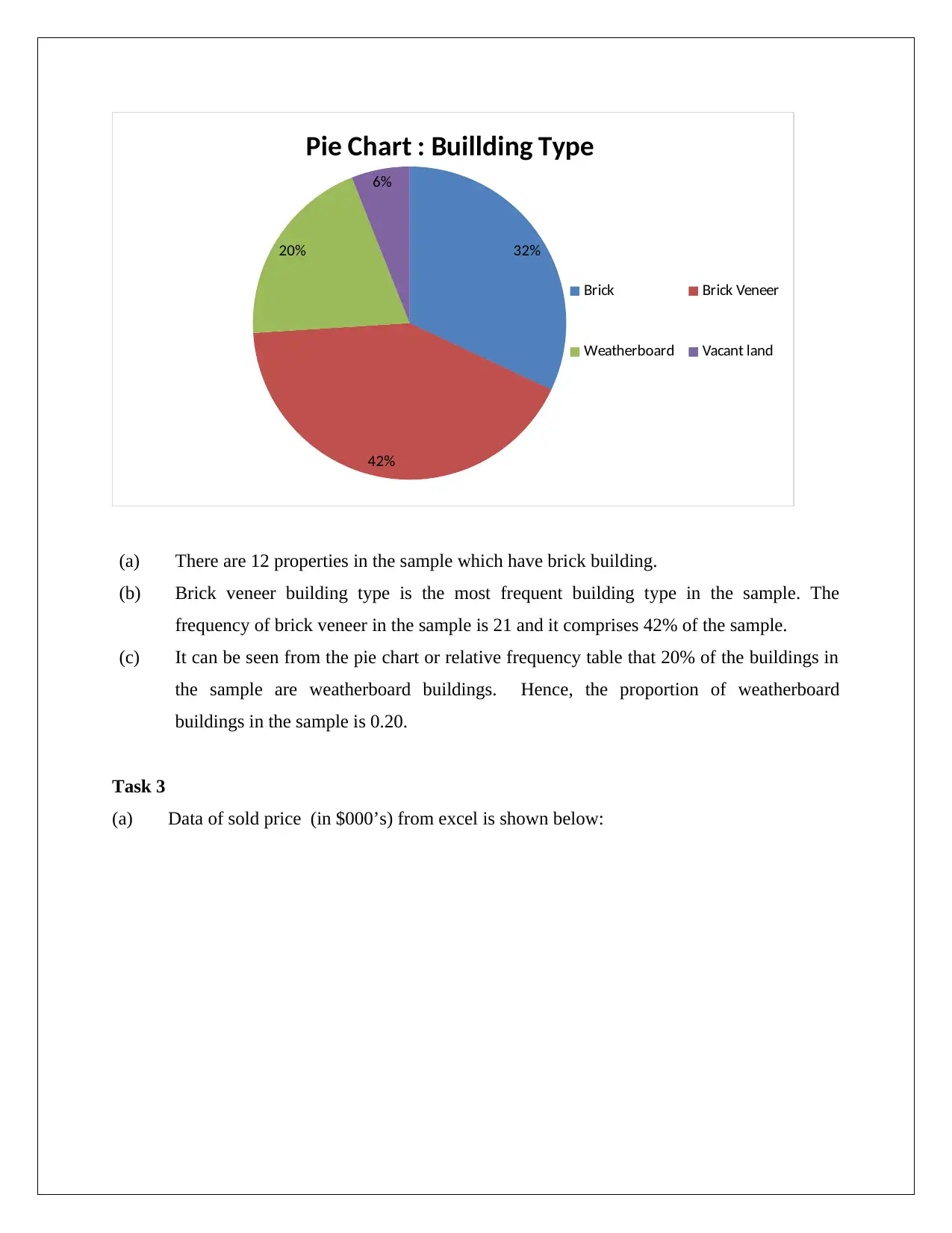









1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.