Business Statistics (MA/GA 508) Assignment - Part I & II Analysis
VerifiedAdded on 2020/04/01
|12
|1226
|916
Homework Assignment
AI Summary
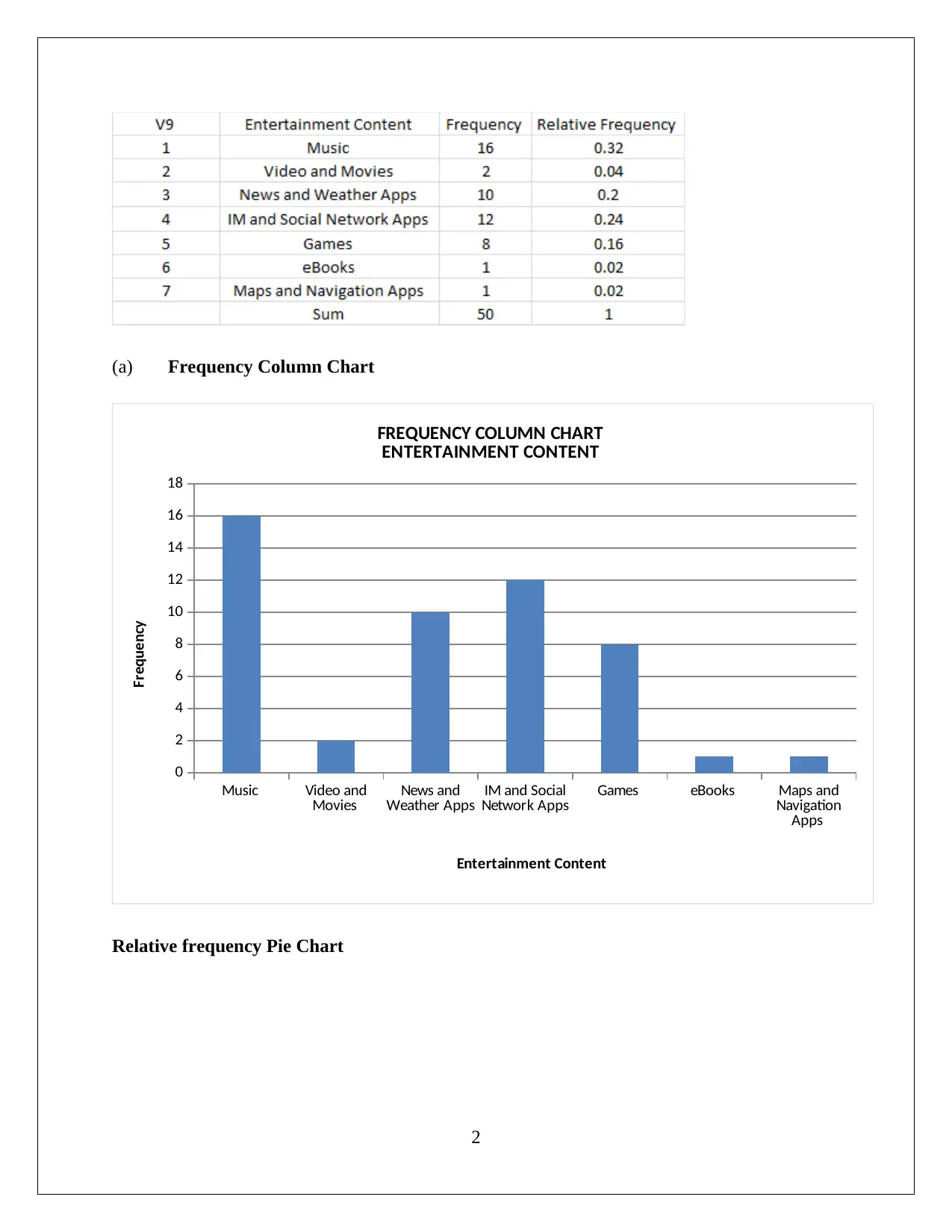
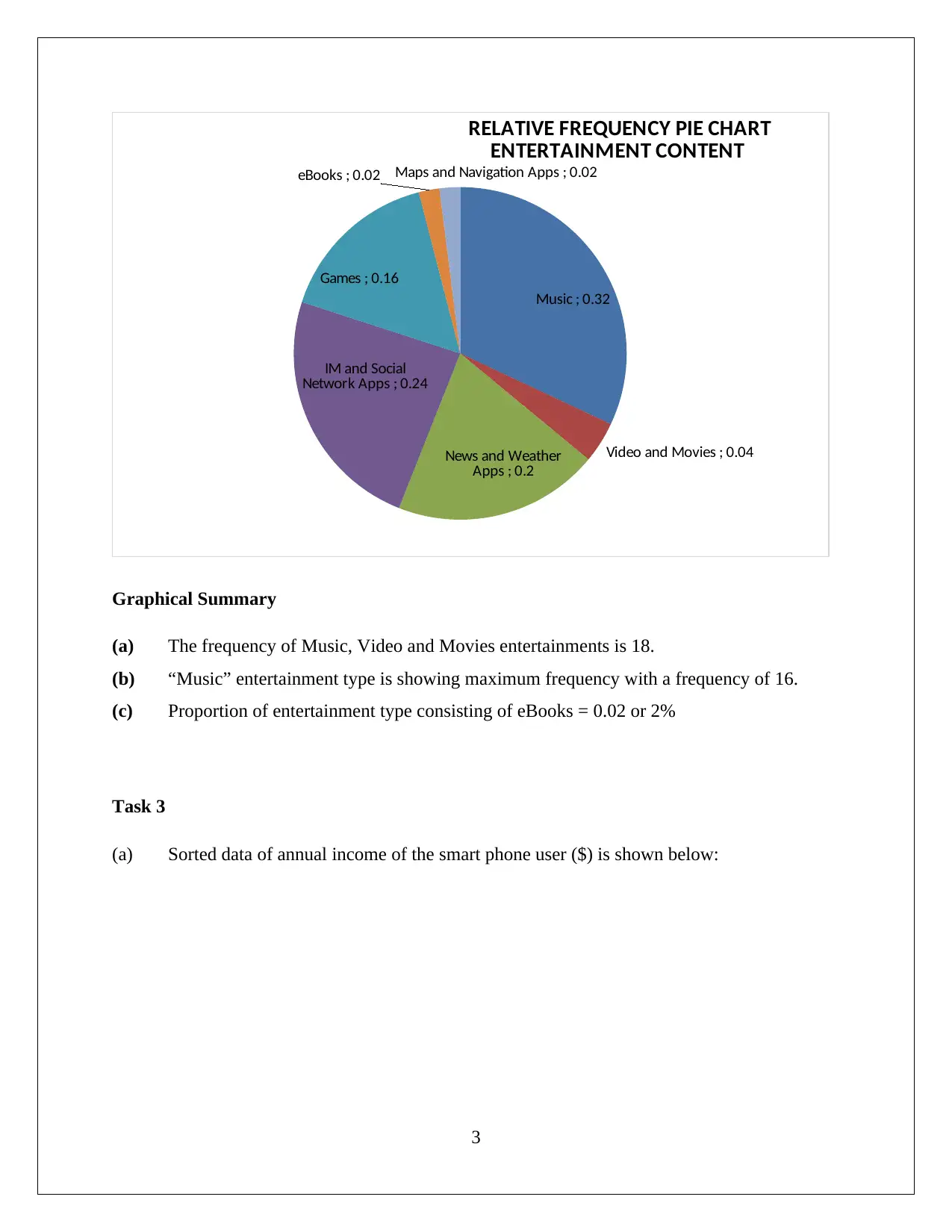
This document presents a comprehensive solution to a business statistics assignment, encompassing various statistical techniques and their applications. It begins with data selection and analysis, including frequency distributions and graphical summaries of entertainment content. The solution then delves into descriptive statistics, calculating percentiles, quartiles, and the interquartile range to analyze income data. The analysis extends to assessing the normality of income distribution and performing hypothesis testing related to the normal distribution. The assignment further explores confidence intervals and their interpretations, followed by a regression analysis to examine the relationship between age and smartphone usage for work. The solution includes detailed calculations, interpretations, and conclusions, providing a thorough understanding of statistical concepts and their practical applications in business contexts.










1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.