Data Analysis Assignment: HOME, ARREST Variable Modes & Normality
VerifiedAdded on 2020/05/11
|3
|616
|201
Homework Assignment
AI Summary
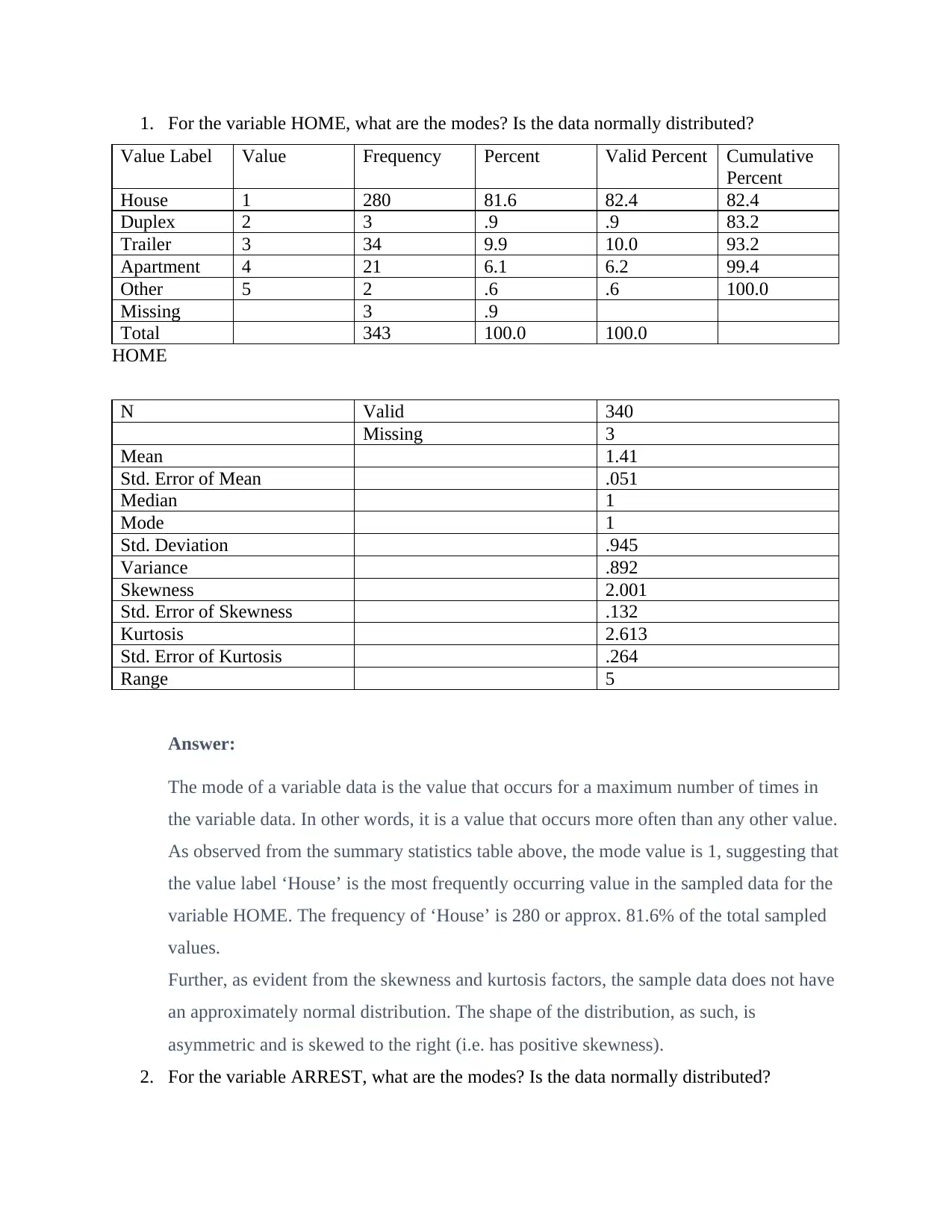
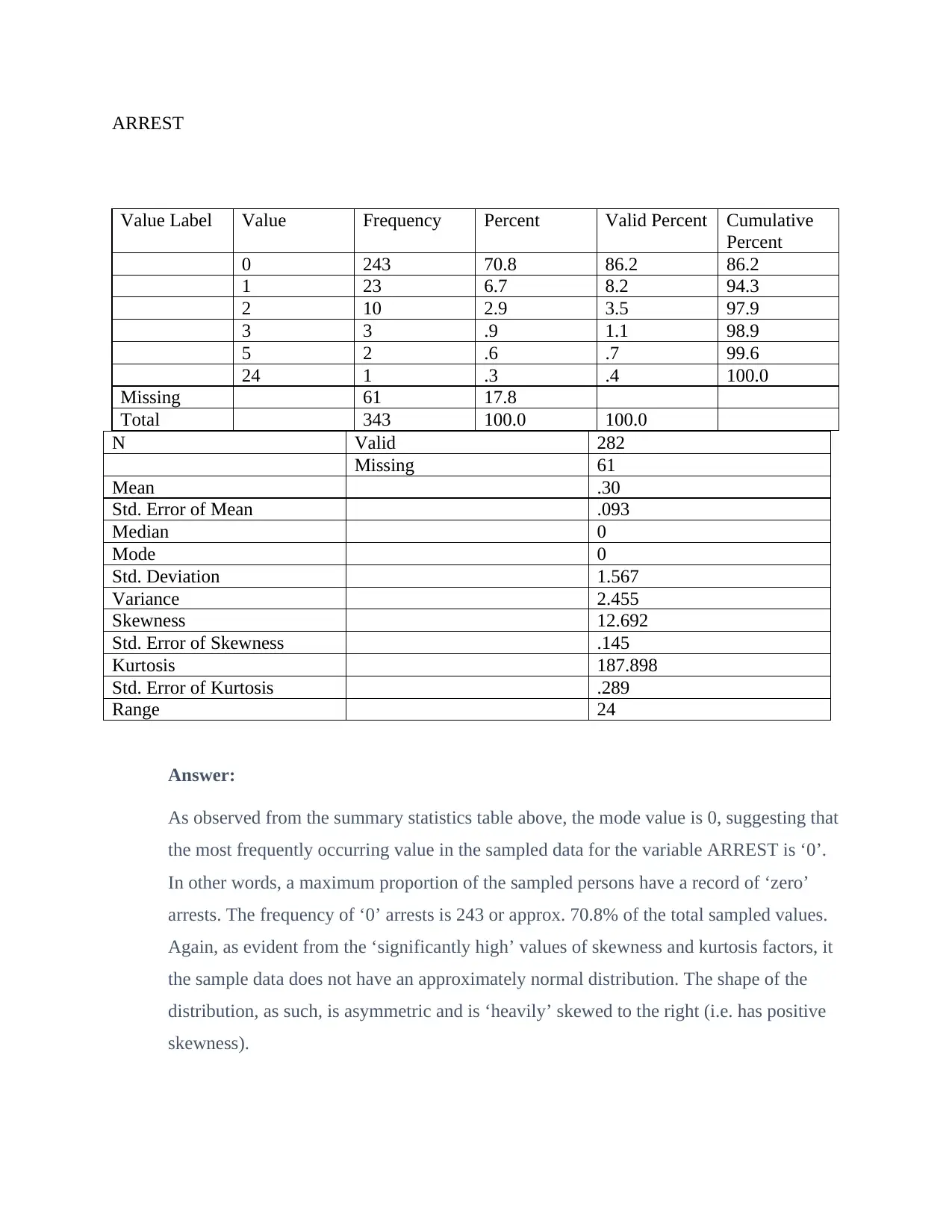
This document presents a statistical analysis of two variables, HOME and ARREST, assessing their modes and distribution characteristics. The analysis determines the mode for both variables by examining frequency distributions, revealing that 'House' is the most frequent value for HOME and '0' arrests is the most frequent value for ARREST. The document further investigates whether the data is normally distributed, using skewness and kurtosis factors to conclude that neither variable exhibits a normal distribution. The implications of non-normality are discussed, emphasizing the limitations on statistical tests and inferences that can be reliably drawn from the data. The solution provides a clear and concise explanation of these statistical concepts, supported by data from the assignment.

1 out of 3
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.