Linear Regression and Correlation Analysis in R: ADMISSION Assignment
VerifiedAdded on 2020/04/29
|13
|1372
|109
Homework Assignment
AI Summary
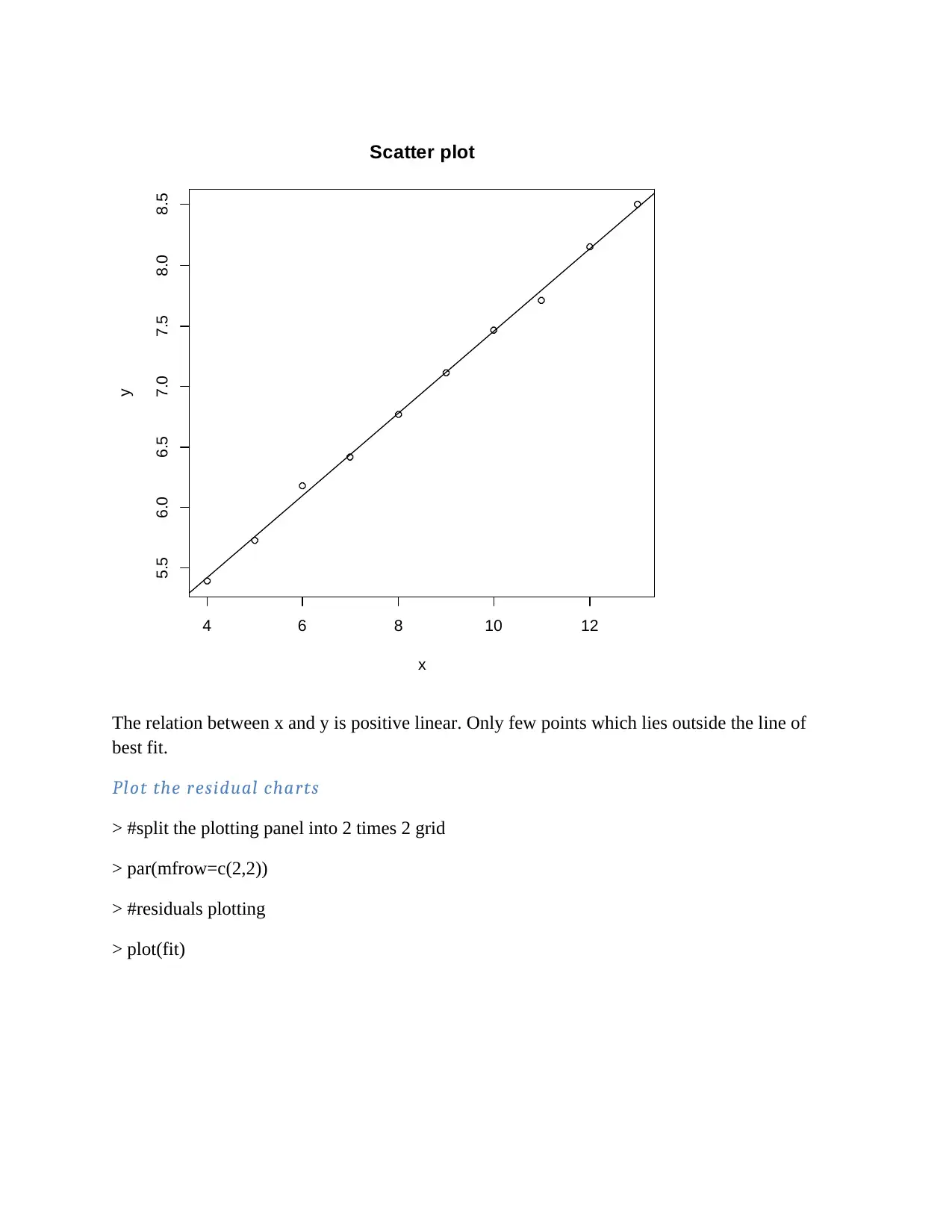
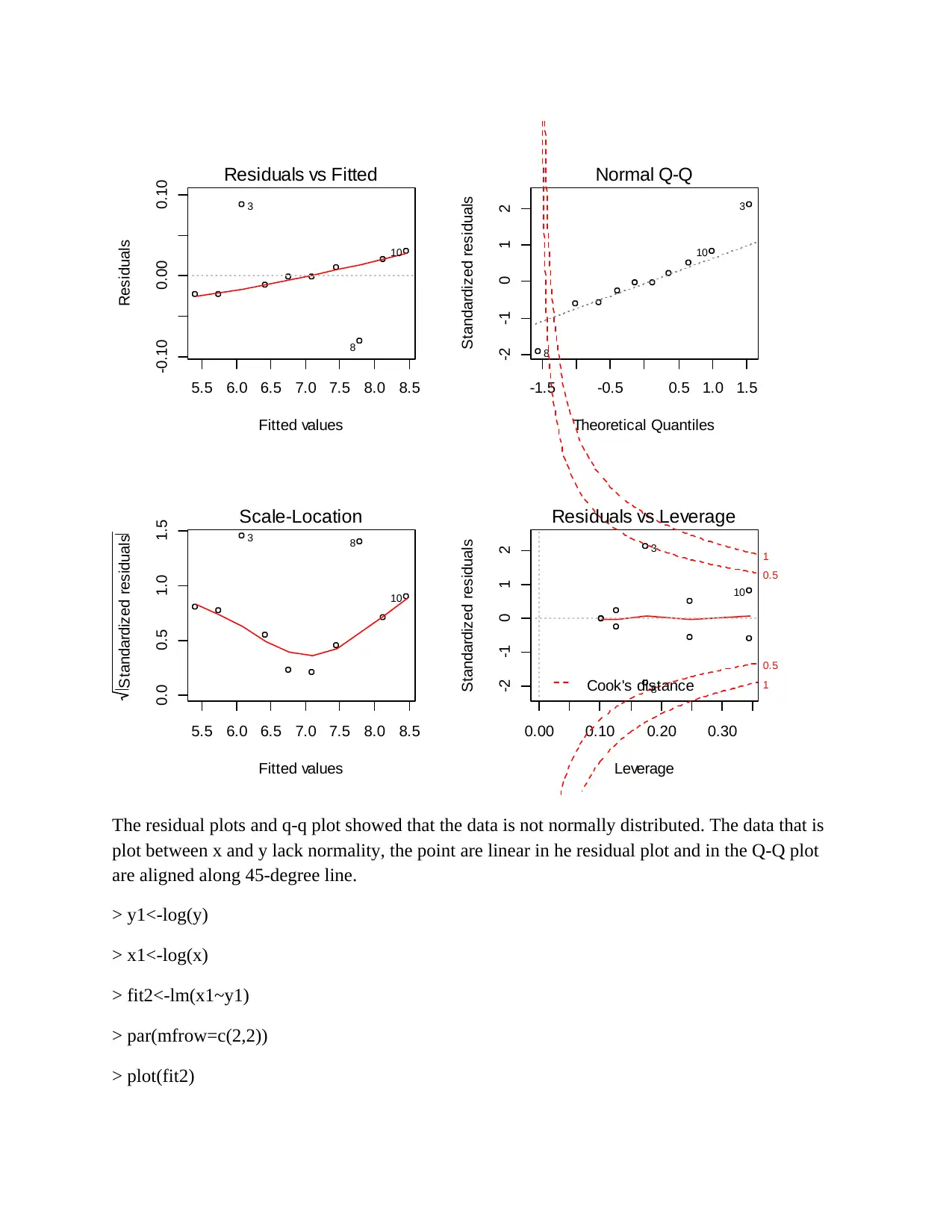
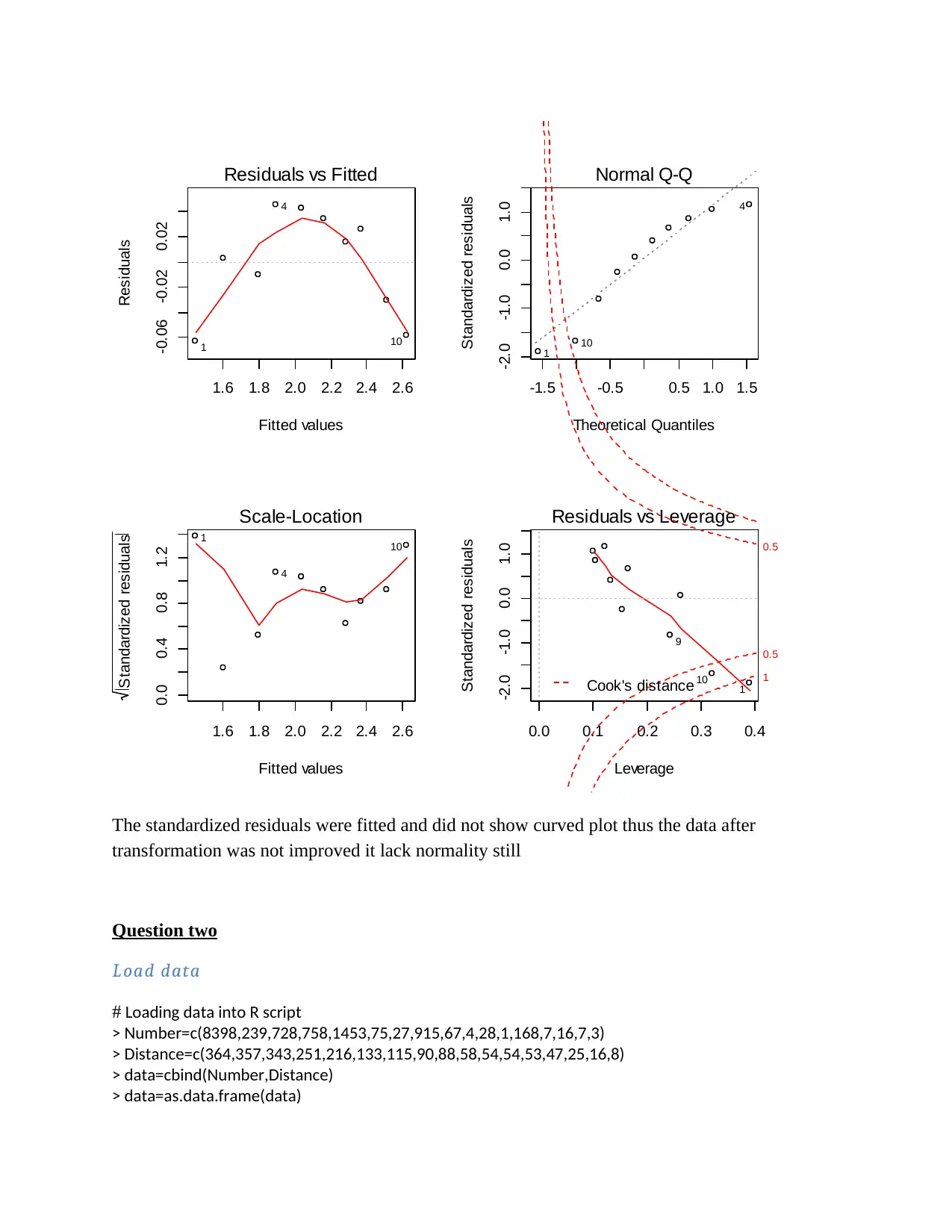
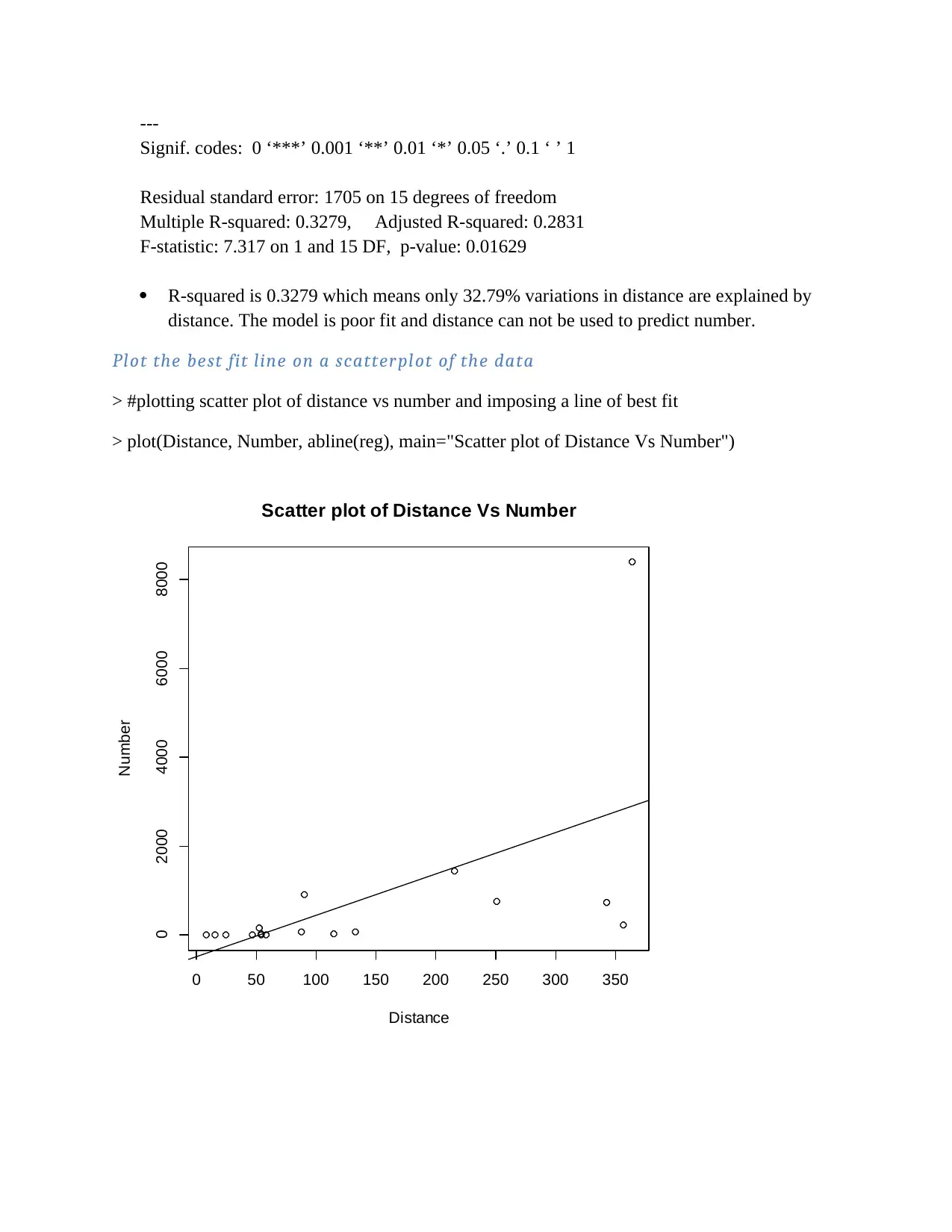
This assignment demonstrates linear regression and correlation analysis using the R programming language. The solution begins by loading data and calculating linear regression models, including interpreting coefficients, p-values, and R-squared values. The analysis involves creating scatter plots and residual plots to assess model fit and identify potential issues like non-normality and non-linearity. The assignment then explores data transformation techniques, specifically logarithmic transformations, to improve model fit and address violations of assumptions. Two distinct datasets are analyzed, with the second dataset focusing on the relationship between 'Number' and 'Distance'. The solution includes model fitting, interpretation of results, and an evaluation of the impact of data transformation on model performance. The student explores the use of scatter plots, residual plots, and Q-Q plots to diagnose the model's performance, including the normality of the data, and the linearity. The assignment concludes by analyzing the impact of data transformation on the model's fit and interpretation.






1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.