Business Statistics: Analyzing Confidence Intervals and Control Charts
VerifiedAdded on 2023/06/03
|9
|1669
|478
Homework Assignment
AI Summary
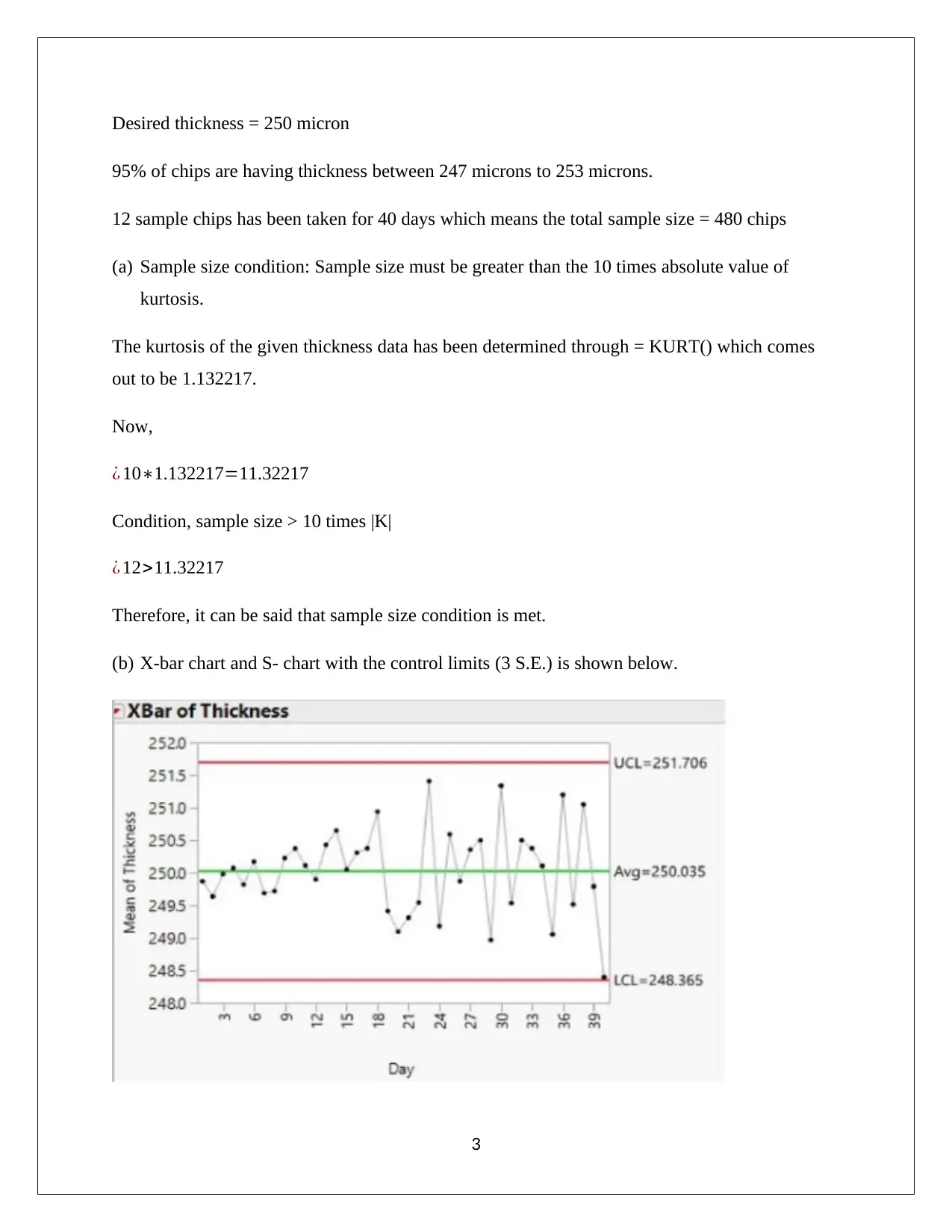
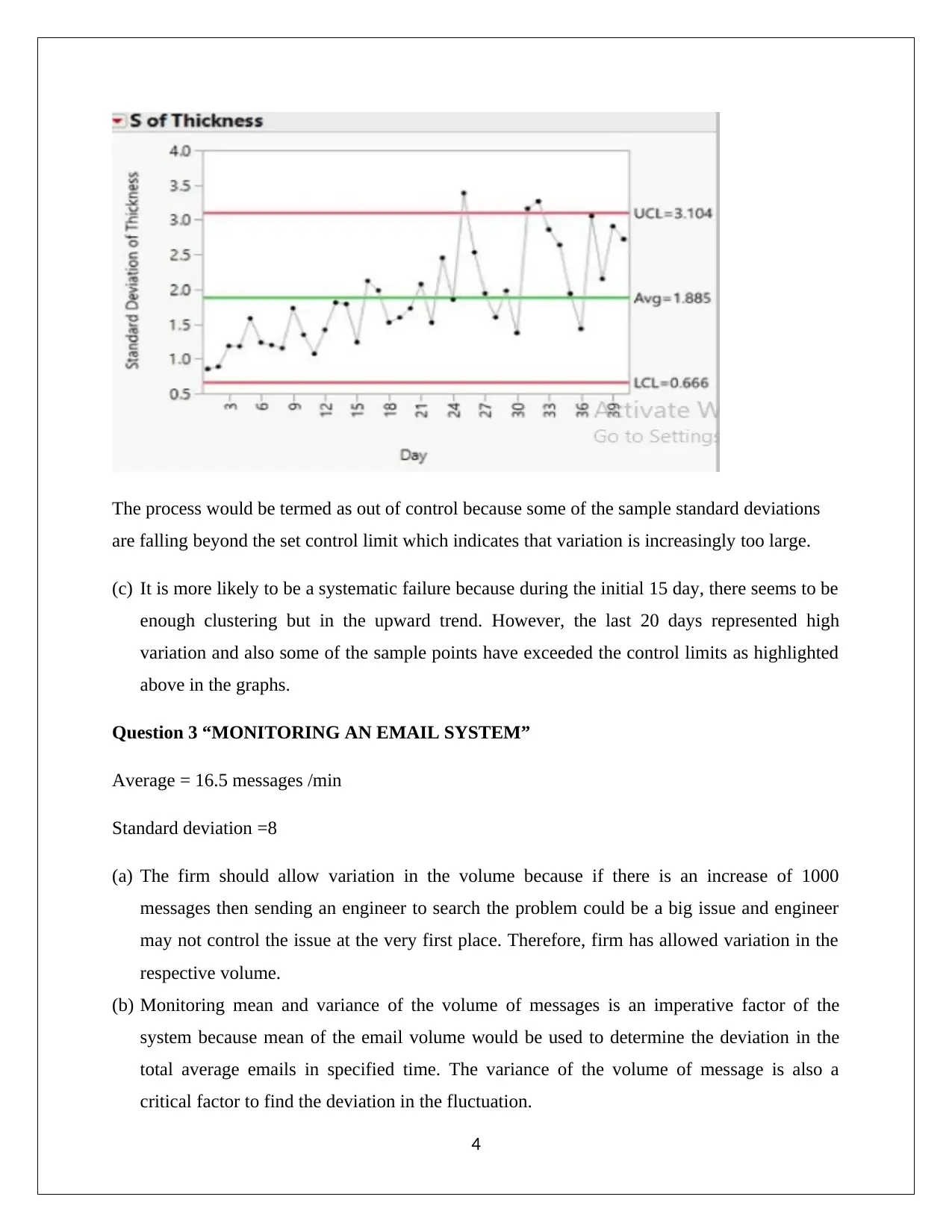
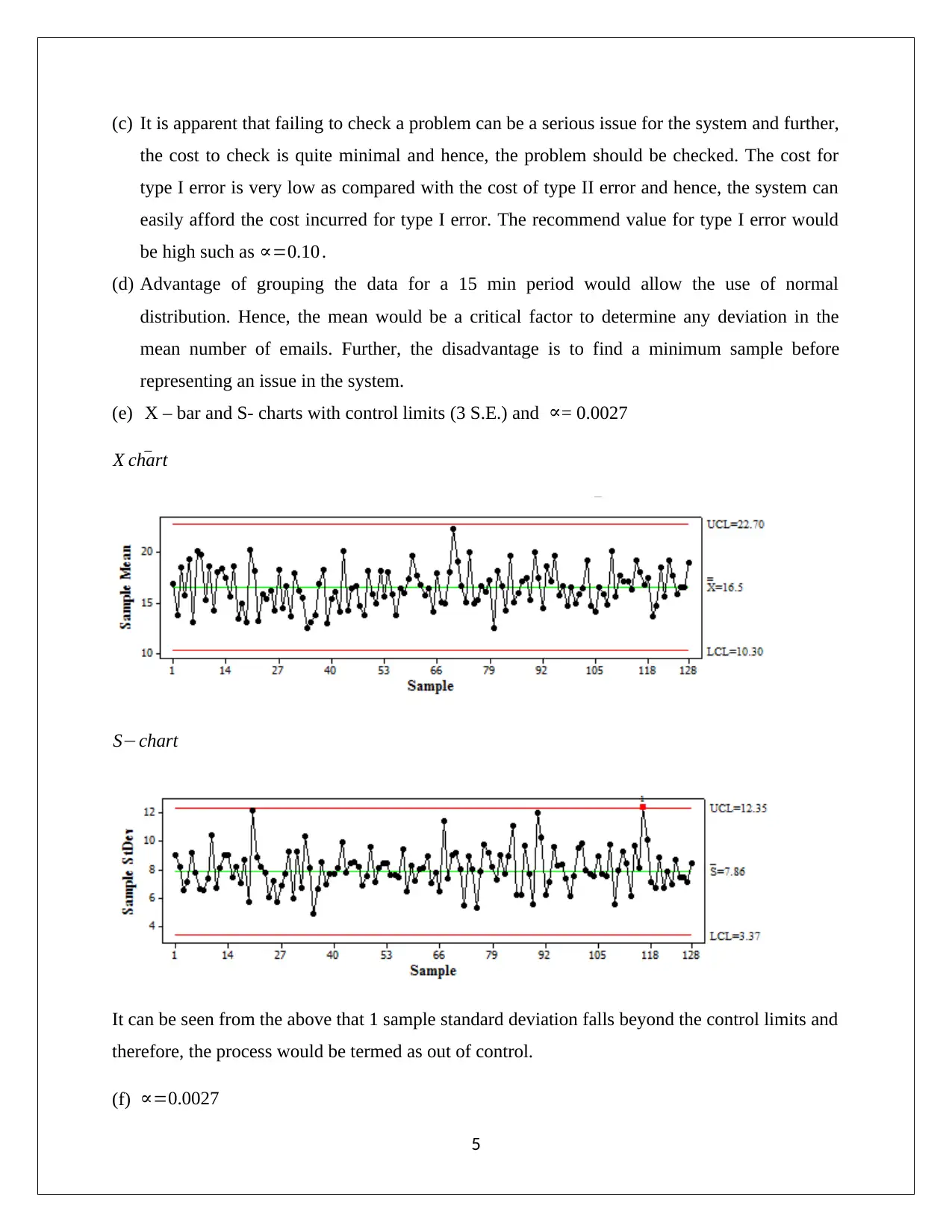
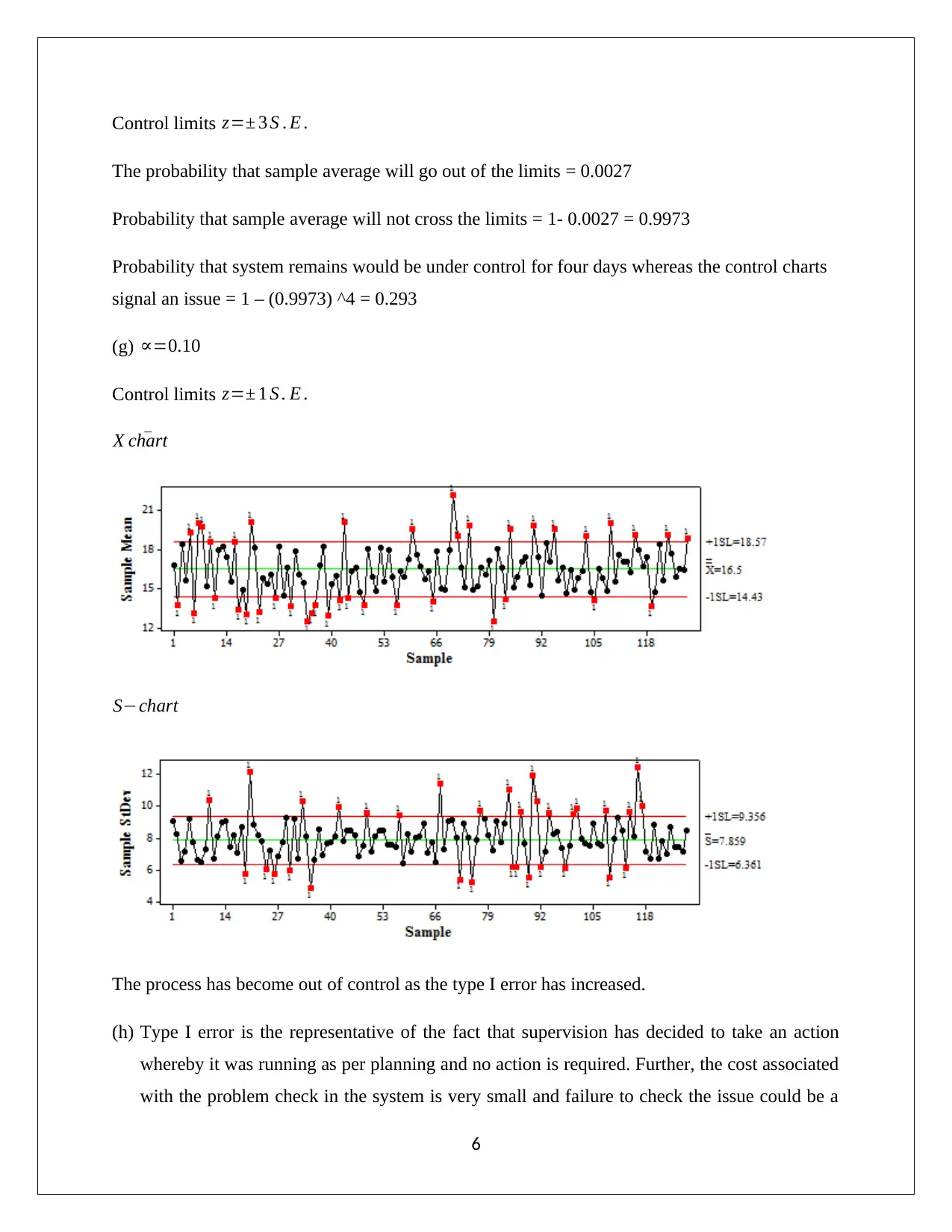
This assignment solution covers several problems in business statistics, including confidence interval estimation and hypothesis testing. The first question involves identifying populations, samples, and parameters of interest in various scenarios such as car service departments, supermarkets, and loan applications. Confidence intervals are estimated using Z-statistics and Excel. The second question analyzes insulator thickness using control charts, kurtosis, and systematic failure identification. The third question examines an email system's message volume, focusing on monitoring mean and variance, type I and type II errors, and control chart analysis. The final questions address wine ratings and sales profit margins, using confidence intervals to compare vintage ratings and assess the statistical significance of sales methods. The document concludes with an analysis of profit margins based on different sales approaches, including the use of randomized methods to minimize bias.





1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.