Business Statistics Assignment: Statistical Analysis and Reporting
VerifiedAdded on 2020/02/19
|10
|2284
|55
Homework Assignment
AI Summary
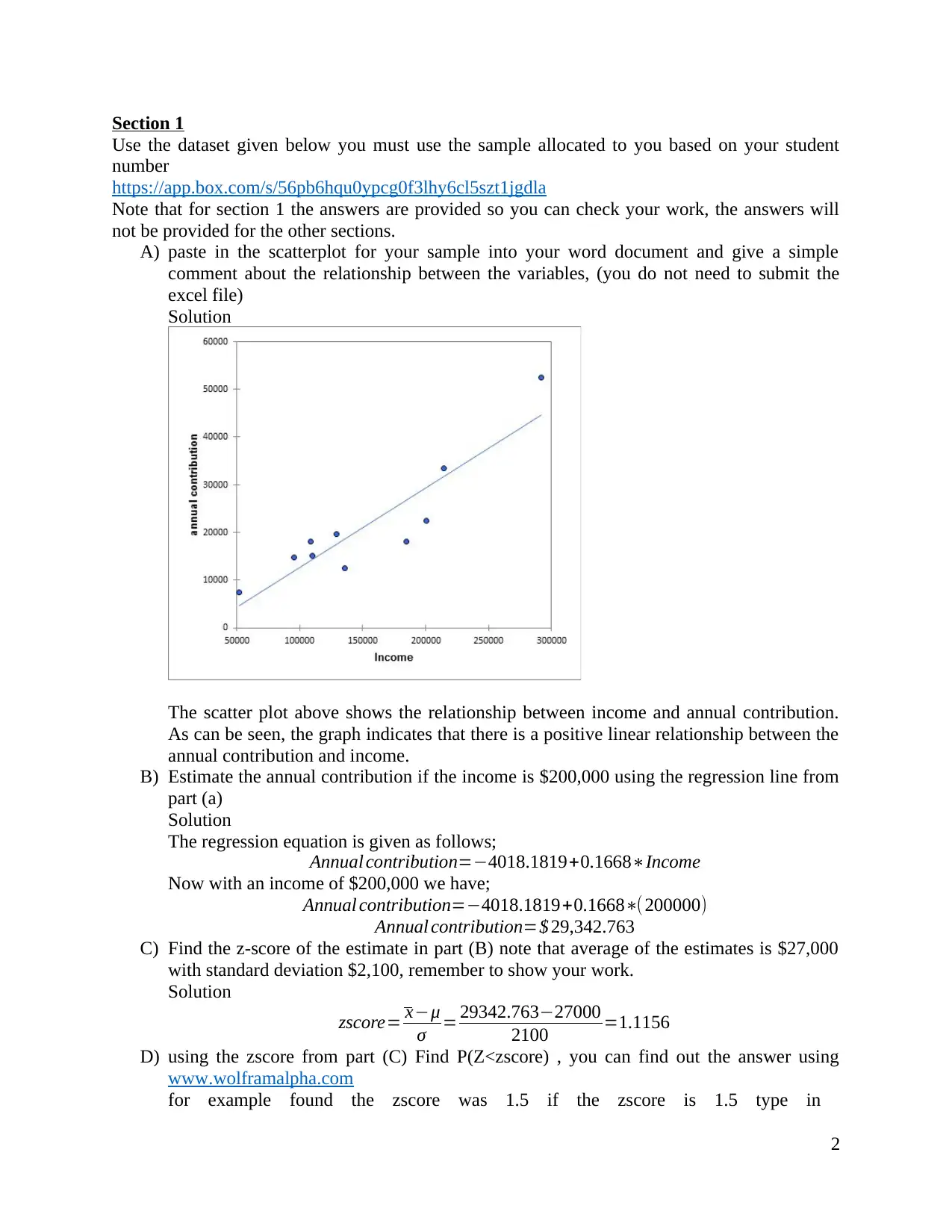
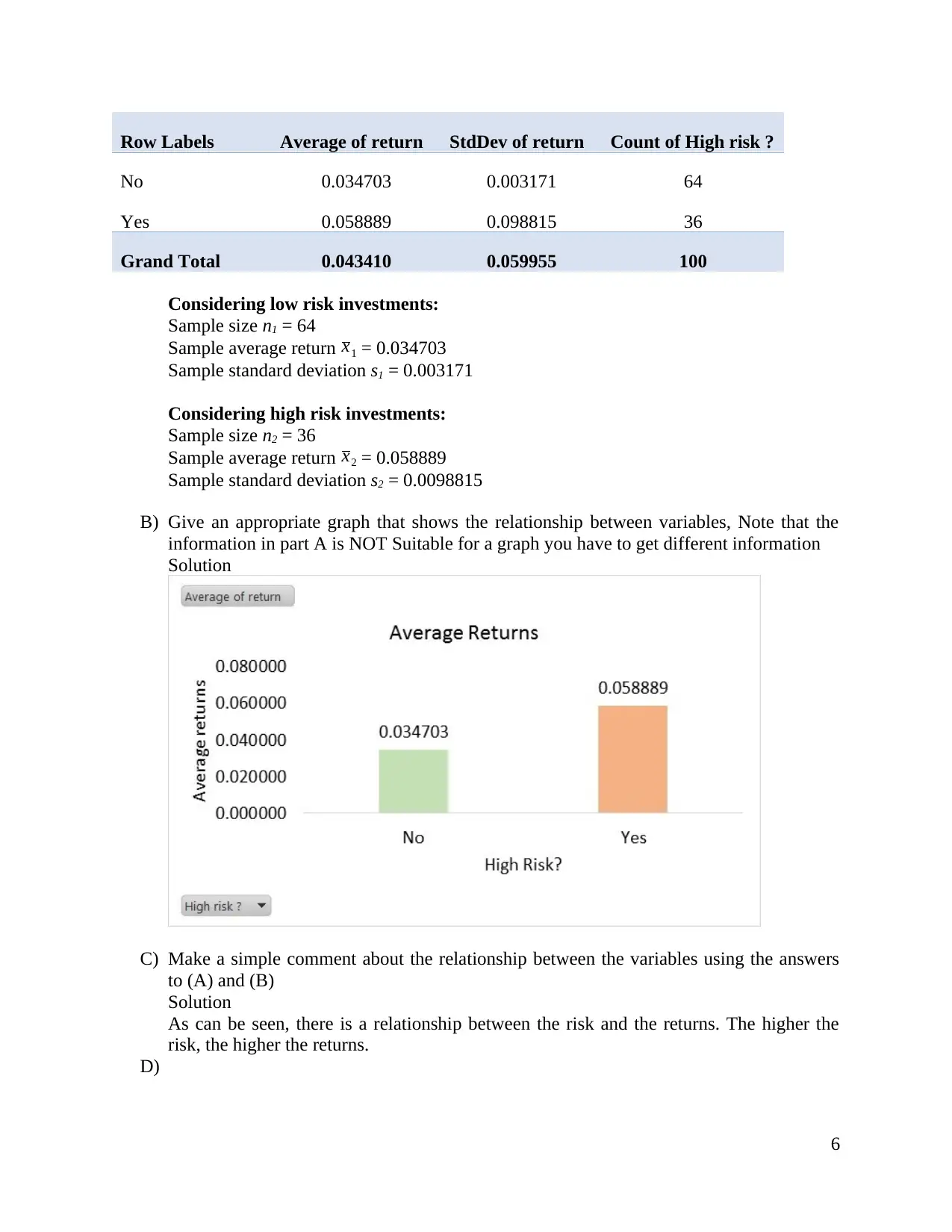
This document presents a complete solution to a business statistics assignment, covering various aspects of data analysis and interpretation. The assignment involves analyzing datasets using techniques like scatter plots, regression analysis, pivot tables, and hypothesis testing. The student estimates annual contributions based on income, calculates z-scores, and determines expected ranks. The analysis extends to comparing proportions of investment types, testing claims about differences in proportions, and finding confidence intervals. The assignment also incorporates the use of Excel for data summarization and graphing, along with the application of statistical tools like z-tests and p-value calculations. The final sections include an analysis of a student's assignment from 2015, focusing on consumer preferences for a snack food, and providing insights into market research and product development strategies. Overall, the document offers a comprehensive guide to statistical analysis in a business context, emphasizing practical application and interpretation of results.








1 out of 10
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.