Data Analysis Project: Healthcare Resource Allocation and Analysis
VerifiedAdded on 2020/07/22
|21
|2934
|250
Project
AI Summary
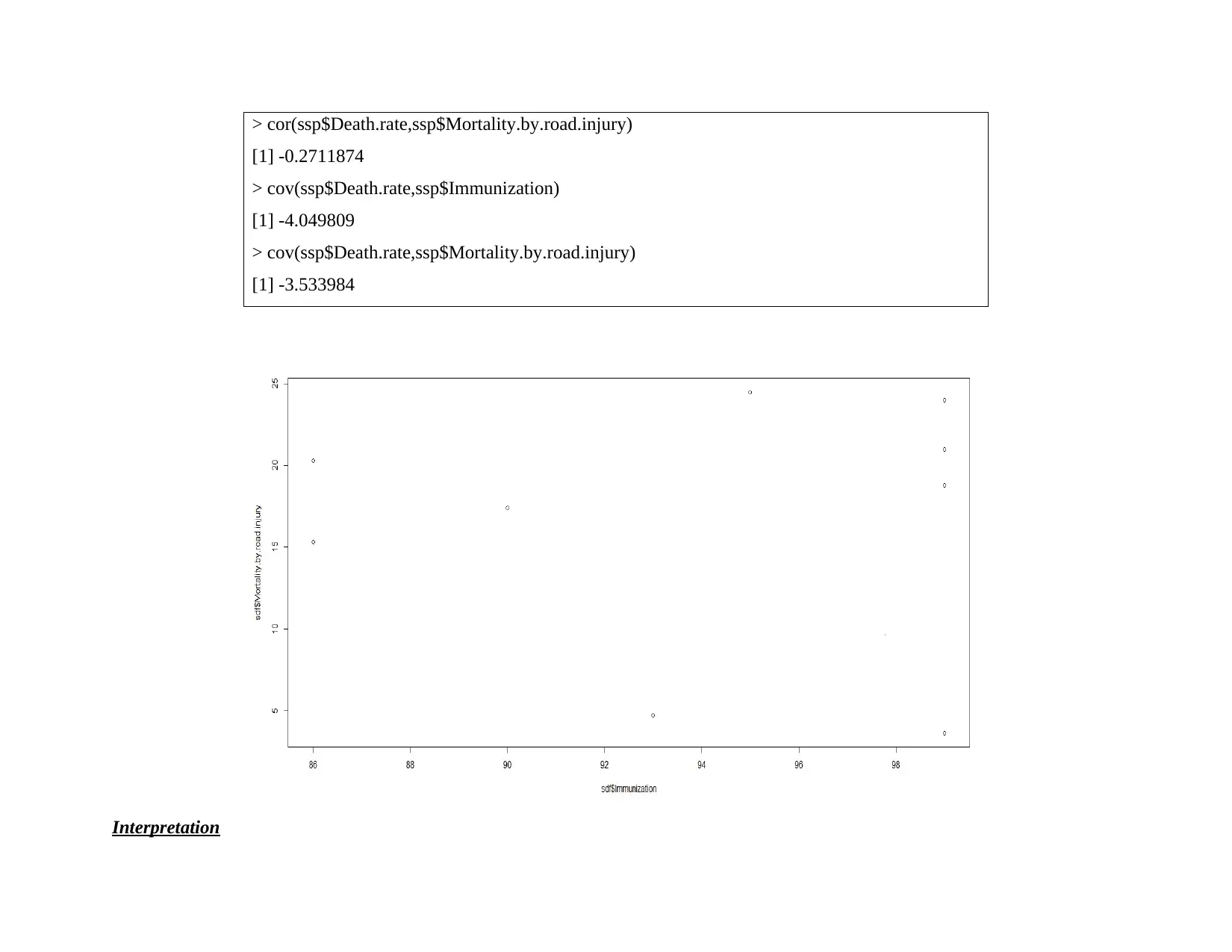
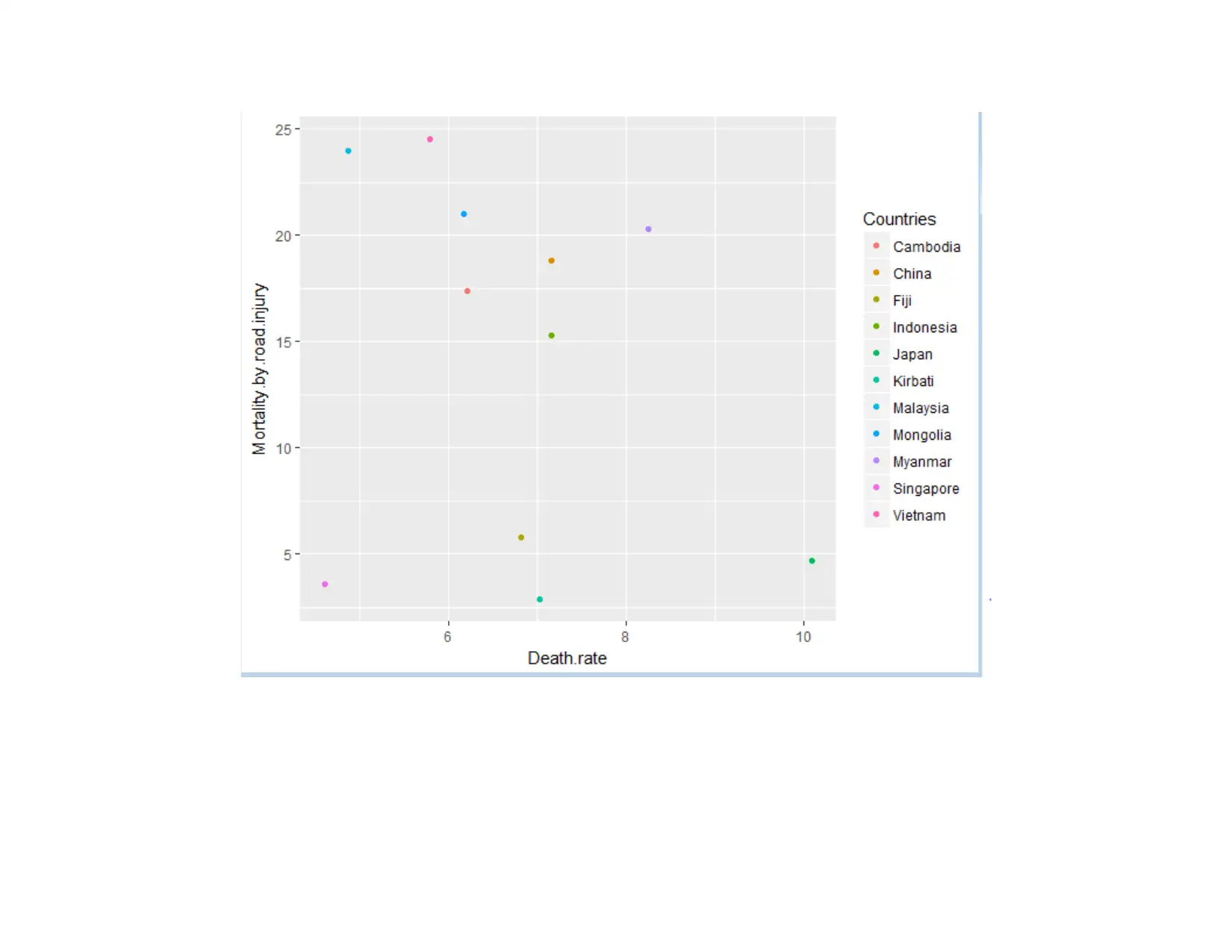
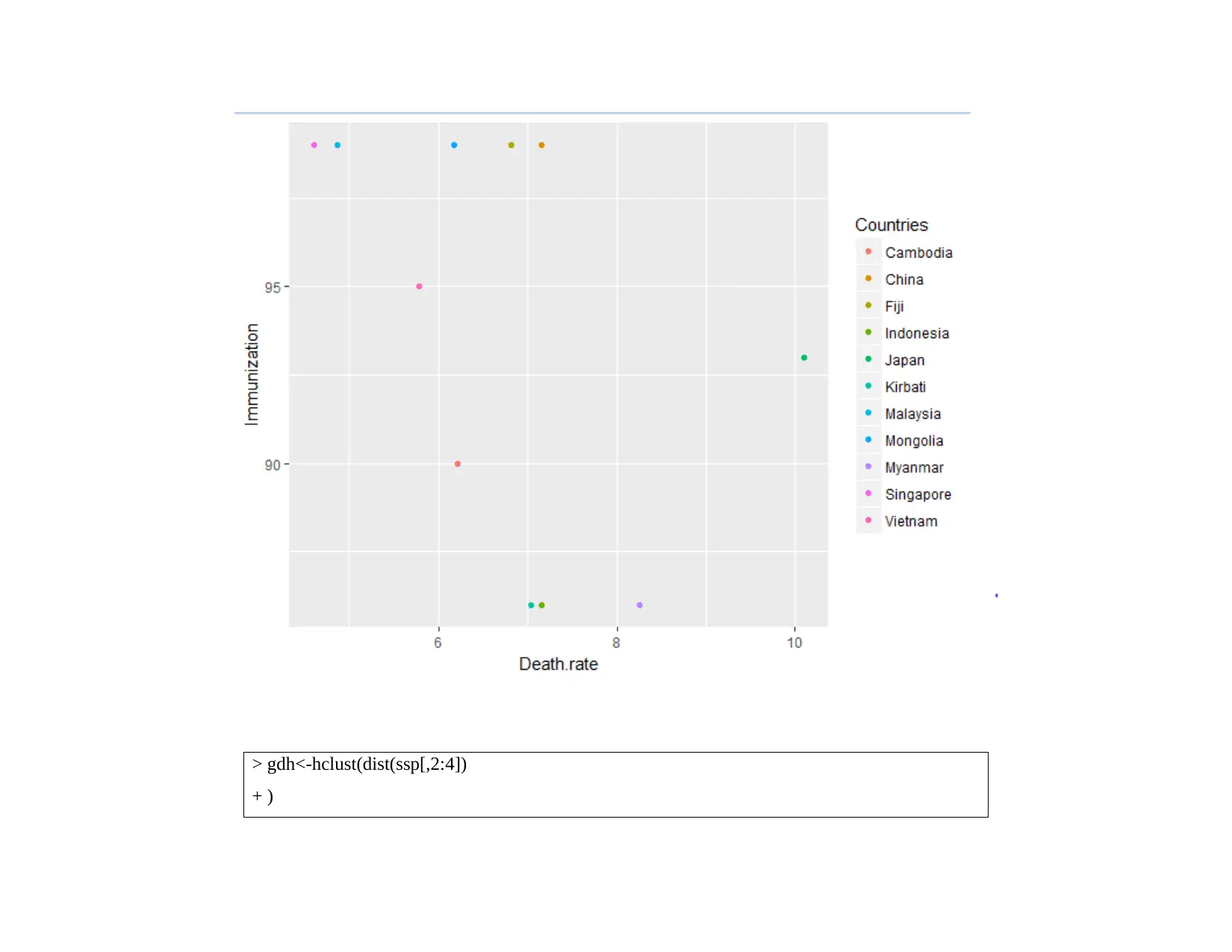
This data analysis project investigates healthcare resource allocation challenges faced by international firms. The project utilizes data from the World Bank website and employs cluster analysis (K-means and hierarchical clustering) and linear regression techniques to analyze relationships between variables such as death rate, immunization, and mortality by road injury. The analysis involves data setup in R, exploratory data analysis (one and two variable analysis), and advanced analysis including the application of K-means clustering to group countries based on similarities in health-related indicators. Linear regression is used to determine the significance of relationships between variables, testing hypotheses about the impact of immunization and road injuries on death rates. The findings suggest that resource allocation policies can be tailored to specific clusters of countries with similar health profiles. The conclusion highlights the key insights derived from the analysis, emphasizing the factors influencing death rates and the implications for healthcare resource management.









1 out of 21


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.