Data Analysis Using Rapidminer Report
VerifiedAdded on 2022/08/16
|12
|1567
|11
AI Summary
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Running head: DATA ANALYSIS USING RAPIDMINER
Data analysis using RapidMiner
Name of the Student
Name of the University
Authors note
Data analysis using RapidMiner
Name of the Student
Name of the University
Authors note
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

1DATA ANALYSIS USING RAPIDMINER
Introduction
Through the data Mining process by using the RapidMiner it becomes easy to explore
large amount of data. Through this data mining process, it can help the business organizations to
solve any business issue or trend. Through the analysis it is possible to find consistent patterns
or relationships among the different variables in the considered database.
For this data analysis project an insurance data set is selected which is publicly
available at https://www.kaggle.com/brandonyongys/insurance-charges/data. The dataset
includes 7 columns with the column headers age, sex, bmi, children, smoker, region, charges.
In this project detailed analysis on the selected data set is analyzed as well as two classification
and clustering models are applied. In the different sections of this report, the relation between
the different attributes and changes in the charges due to the changes in the remaining 6 factors
or attributes using the classification and clustering techniques.
Problem Statement
In this project the main objective is to track and predict the charges for the insurance
depending upon the different other factors such as age, BMI of an individual as recorded in data
set, their sex and if the individual is smoker or not.
Used Models
Naïve Bayes classifier
Naive Bayes is one of the widely used classification algorithm for both binary as well as
multi-class classification problems in data mining and knowledge generation process. This
method is a supervised learning as well as statistical method used for classification purpose. This
method depends on the underlying probabilistic model which helps in capturing the uncertainty
about the developed model in a upright through the determination of different probabilities of
different outcomes. Therefore, depending upon the probabilistic model it is capable of solving
predictive problems. The Naive Bayes classifier is based on the application of the Bayes'
theorem in the field of statistics that have strong or naive assumptions for developing the models.
The naive Bayes classifier work on the assumption that presence/ absence of some
specific feature or attribute is not related to the presence/absence of another feature in the
Introduction
Through the data Mining process by using the RapidMiner it becomes easy to explore
large amount of data. Through this data mining process, it can help the business organizations to
solve any business issue or trend. Through the analysis it is possible to find consistent patterns
or relationships among the different variables in the considered database.
For this data analysis project an insurance data set is selected which is publicly
available at https://www.kaggle.com/brandonyongys/insurance-charges/data. The dataset
includes 7 columns with the column headers age, sex, bmi, children, smoker, region, charges.
In this project detailed analysis on the selected data set is analyzed as well as two classification
and clustering models are applied. In the different sections of this report, the relation between
the different attributes and changes in the charges due to the changes in the remaining 6 factors
or attributes using the classification and clustering techniques.
Problem Statement
In this project the main objective is to track and predict the charges for the insurance
depending upon the different other factors such as age, BMI of an individual as recorded in data
set, their sex and if the individual is smoker or not.
Used Models
Naïve Bayes classifier
Naive Bayes is one of the widely used classification algorithm for both binary as well as
multi-class classification problems in data mining and knowledge generation process. This
method is a supervised learning as well as statistical method used for classification purpose. This
method depends on the underlying probabilistic model which helps in capturing the uncertainty
about the developed model in a upright through the determination of different probabilities of
different outcomes. Therefore, depending upon the probabilistic model it is capable of solving
predictive problems. The Naive Bayes classifier is based on the application of the Bayes'
theorem in the field of statistics that have strong or naive assumptions for developing the models.
The naive Bayes classifier work on the assumption that presence/ absence of some
specific feature or attribute is not related to the presence/absence of another feature in the

2DATA ANALYSIS USING RAPIDMINER
considered problem. As an example, a fruit will be identified as watermelon if the outside color
is green, round in shape, and about 6" in diameter. Even though the above-mentioned features
depend on each other, or the existence of one features depend on others, but naive Bayes
classifier assumes that all the attributes or properties are independently contribute to the
probability for the fruit being an watermelon.
While calculating the probability the naïve Bayes classifier does not attempt to calculate
values of every single attribute for a model P(a1, a2,a3|h), it calculates the probability by
assuming that attributes are conditionally independent and for the target value calculated as
P(a1|H) * P(a2|H) and so on.
Due to the precise nature of this model the naive Bayes classifiers is selected as one of
the models. Furthermore, the model can be trained efficiently in supervised environment. While
training the models for the real scenarios, parameter estimation for this classifier model utilizes
the technique of maximum likelihood of the attributes for next stage of classification from the
selected dataset.
Decision tree
The technique of classification is the systematic strategy for building the models of
classification from the data set of input. For instance, classifiers of decision tree, neural
networks, naïve Bayes, support vector machines and rule-based classifiers are the various
techniques for solving the classification problems.
Classifiers of decision tree are the widely used and simple classification techniques. This
applies the straightforward ideas for solving the classification problems.
K-means clustering
Clustering is the machine earning technique, which involves the data points grouping. By
the given data points set, the clustering algorithm can be used for classifying the each data point
in the particular groups. As per theory, the data points, which are in the single group needs to
have the same properties and features while the data points in various groups need to have the
dissimilar properties and the features. Clustering is the method of the unsupervised learning and
this is the common technique for the statistical data analysis that is utilized in multiple fields.
considered problem. As an example, a fruit will be identified as watermelon if the outside color
is green, round in shape, and about 6" in diameter. Even though the above-mentioned features
depend on each other, or the existence of one features depend on others, but naive Bayes
classifier assumes that all the attributes or properties are independently contribute to the
probability for the fruit being an watermelon.
While calculating the probability the naïve Bayes classifier does not attempt to calculate
values of every single attribute for a model P(a1, a2,a3|h), it calculates the probability by
assuming that attributes are conditionally independent and for the target value calculated as
P(a1|H) * P(a2|H) and so on.
Due to the precise nature of this model the naive Bayes classifiers is selected as one of
the models. Furthermore, the model can be trained efficiently in supervised environment. While
training the models for the real scenarios, parameter estimation for this classifier model utilizes
the technique of maximum likelihood of the attributes for next stage of classification from the
selected dataset.
Decision tree
The technique of classification is the systematic strategy for building the models of
classification from the data set of input. For instance, classifiers of decision tree, neural
networks, naïve Bayes, support vector machines and rule-based classifiers are the various
techniques for solving the classification problems.
Classifiers of decision tree are the widely used and simple classification techniques. This
applies the straightforward ideas for solving the classification problems.
K-means clustering
Clustering is the machine earning technique, which involves the data points grouping. By
the given data points set, the clustering algorithm can be used for classifying the each data point
in the particular groups. As per theory, the data points, which are in the single group needs to
have the same properties and features while the data points in various groups need to have the
dissimilar properties and the features. Clustering is the method of the unsupervised learning and
this is the common technique for the statistical data analysis that is utilized in multiple fields.

3DATA ANALYSIS USING RAPIDMINER
K-means algorithm is the iterative algorithm, which tries to divide the data set in the K-
predefined non-overlapping distinct cluster or subgroups, where the every data set belongs to the
single group. K-means clustering is the process of the vector quantization, which is from the
signal processing, which is well-known for the data mining cluster analysis. K-means algorithm
aims to divide the n observation into the k cluster in which the observations are into the cluster
with the mean value and serving as the cluster prototype. This cause in the portioning od the data
set in the cells. The algorithm k-means reduces the cluster into various distances, however not
regular distances that can be more difficult. The mean identifies the squared errors, where the
geometric median reduces the Euclidean distances.
This makes the data a point that is inter-cluster as same as the possible while keeping the
different cluster as far as possible. This assigns the data points to the cluster, as the squared
distance sum between the centroid of cluster and the data points is the minimum points.
The less variation in the cluster, the more of the similar or homogeneous data points are
in the similar cluster.
Below is the way in which k-means works such as:
Specifies the number of K (cluster)
This computes the centroids for cluster by taking average of the data set, which belongs
to every cluster.
SVM clustering
Support Vector Clustering different data values are plotted from complete data space
inside a definite high dimensional feature space. The plotting or the mapping is done through the
use of the Gaussian kernel.
Inside the feature space, least or the smallest sphere that is capable of enclosing the
features of a centroid is searched and plotted. The definite sphere is mapped back again inside
the data space
K-means algorithm is the iterative algorithm, which tries to divide the data set in the K-
predefined non-overlapping distinct cluster or subgroups, where the every data set belongs to the
single group. K-means clustering is the process of the vector quantization, which is from the
signal processing, which is well-known for the data mining cluster analysis. K-means algorithm
aims to divide the n observation into the k cluster in which the observations are into the cluster
with the mean value and serving as the cluster prototype. This cause in the portioning od the data
set in the cells. The algorithm k-means reduces the cluster into various distances, however not
regular distances that can be more difficult. The mean identifies the squared errors, where the
geometric median reduces the Euclidean distances.
This makes the data a point that is inter-cluster as same as the possible while keeping the
different cluster as far as possible. This assigns the data points to the cluster, as the squared
distance sum between the centroid of cluster and the data points is the minimum points.
The less variation in the cluster, the more of the similar or homogeneous data points are
in the similar cluster.
Below is the way in which k-means works such as:
Specifies the number of K (cluster)
This computes the centroids for cluster by taking average of the data set, which belongs
to every cluster.
SVM clustering
Support Vector Clustering different data values are plotted from complete data space
inside a definite high dimensional feature space. The plotting or the mapping is done through the
use of the Gaussian kernel.
Inside the feature space, least or the smallest sphere that is capable of enclosing the
features of a centroid is searched and plotted. The definite sphere is mapped back again inside
the data space
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
4DATA ANALYSIS USING RAPIDMINER
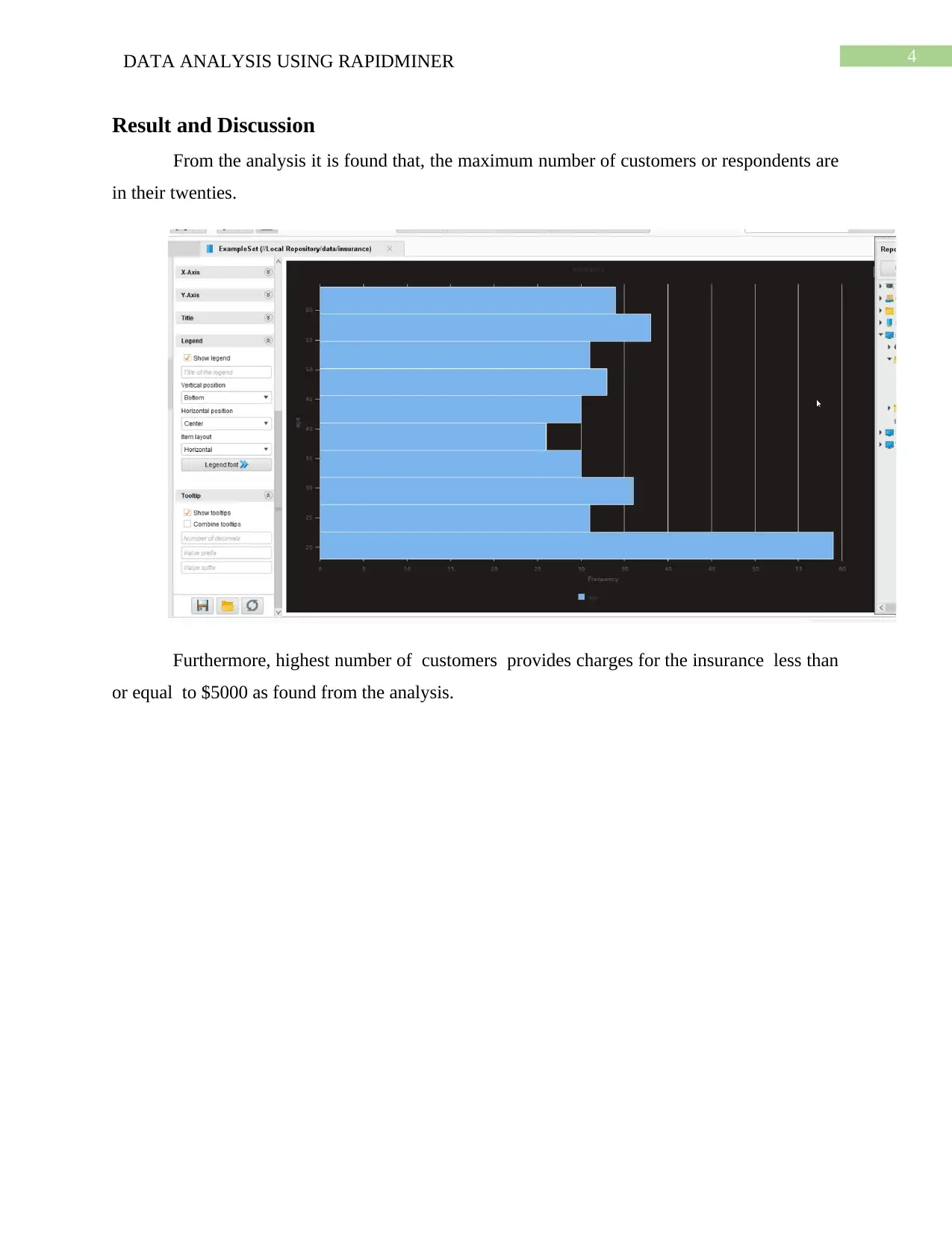
Result and Discussion
From the analysis it is found that, the maximum number of customers or respondents are
in their twenties.
Furthermore, highest number of customers provides charges for the insurance less than
or equal to $5000 as found from the analysis.
Result and Discussion
From the analysis it is found that, the maximum number of customers or respondents are
in their twenties.
Furthermore, highest number of customers provides charges for the insurance less than
or equal to $5000 as found from the analysis.
5DATA ANALYSIS USING RAPIDMINER
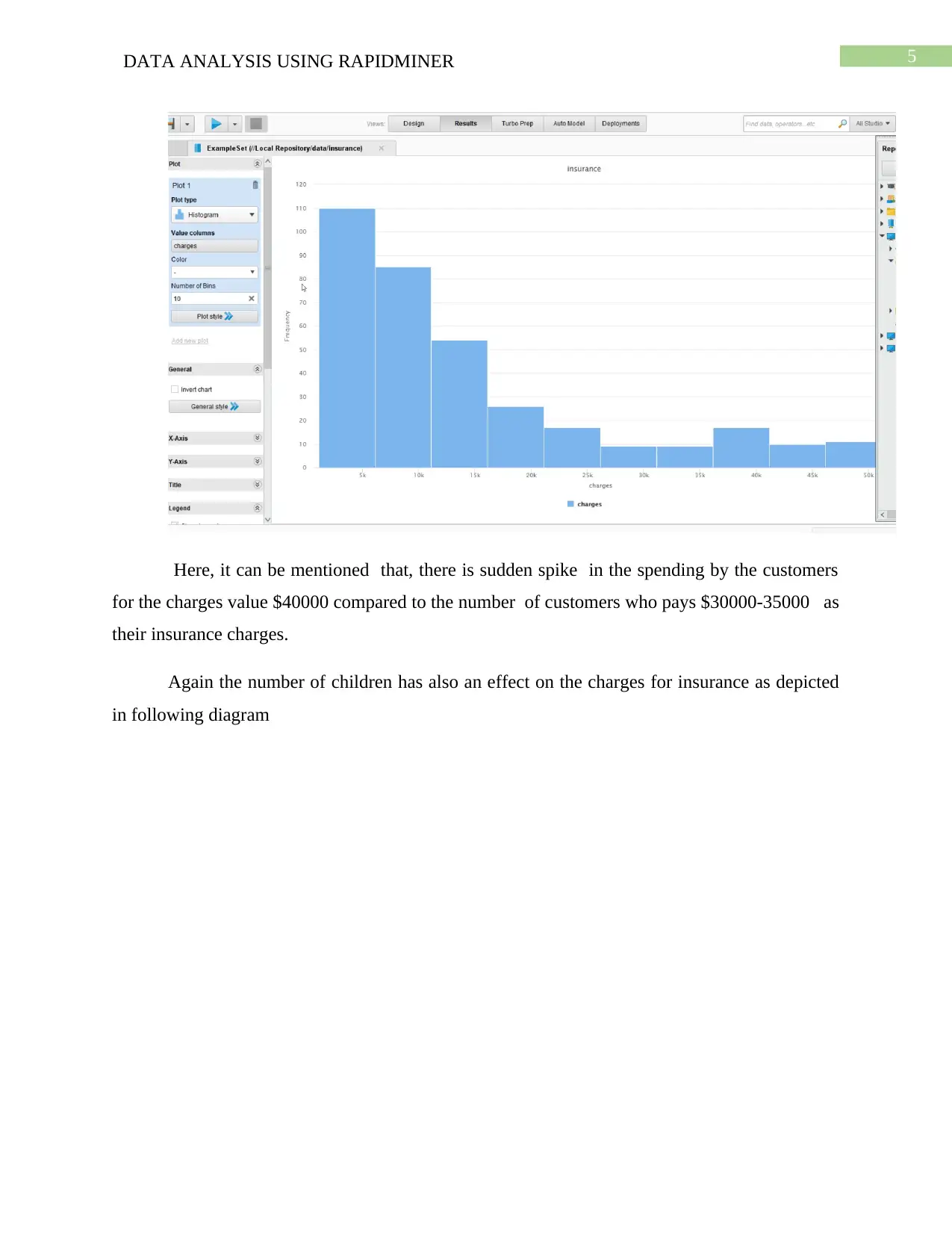
Here, it can be mentioned that, there is sudden spike in the spending by the customers
for the charges value $40000 compared to the number of customers who pays $30000-35000 as
their insurance charges.
Again the number of children has also an effect on the charges for insurance as depicted
in following diagram
Here, it can be mentioned that, there is sudden spike in the spending by the customers
for the charges value $40000 compared to the number of customers who pays $30000-35000 as
their insurance charges.
Again the number of children has also an effect on the charges for insurance as depicted
in following diagram
6DATA ANALYSIS USING RAPIDMINER
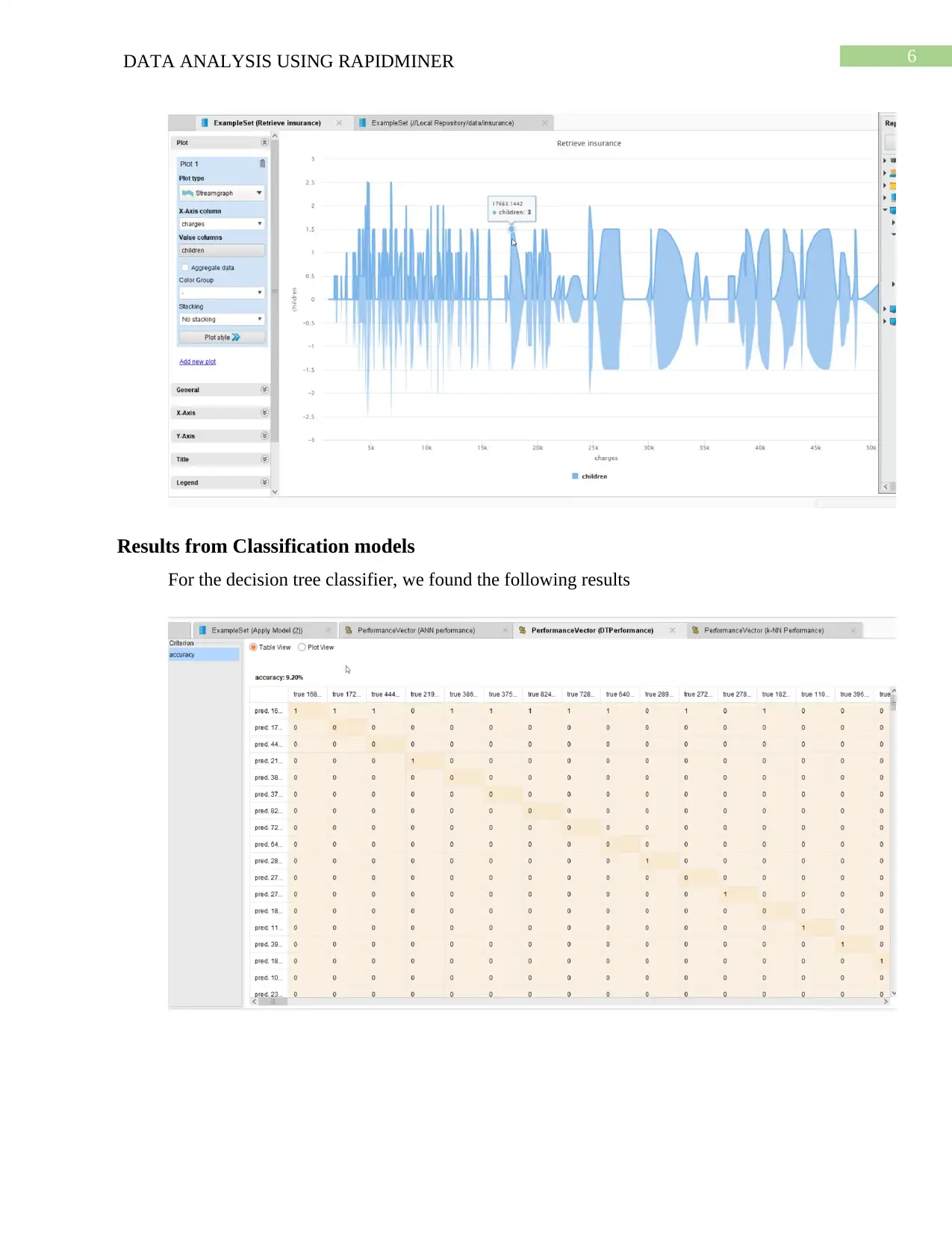
Results from Classification models
For the decision tree classifier, we found the following results
Results from Classification models
For the decision tree classifier, we found the following results
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

7DATA ANALYSIS USING RAPIDMINER
Here it can be found that, in the decision tree classifier the accuracy is very low marked
as 9.20%. On the other hand, another classifier used is the naïve Bayes. The obtained result was
given below;
Here, it can be seen that, the accuracy recorded is 100% thus it can be stated as the most
suitable classifier for the selected dataset.
Results from the Clustering model
In the clustering model the, in case of using the k-means clustering, the following results
are obtained.
Cluster 0: 87 items
Cluster 1: 58 items
Cluster 2: 68 items
Cluster 3: 77 items
Cluster 4: 58 items
Here it can be found that, in the decision tree classifier the accuracy is very low marked
as 9.20%. On the other hand, another classifier used is the naïve Bayes. The obtained result was
given below;
Here, it can be seen that, the accuracy recorded is 100% thus it can be stated as the most
suitable classifier for the selected dataset.
Results from the Clustering model
In the clustering model the, in case of using the k-means clustering, the following results
are obtained.
Cluster 0: 87 items
Cluster 1: 58 items
Cluster 2: 68 items
Cluster 3: 77 items
Cluster 4: 58 items
8DATA ANALYSIS USING RAPIDMINER
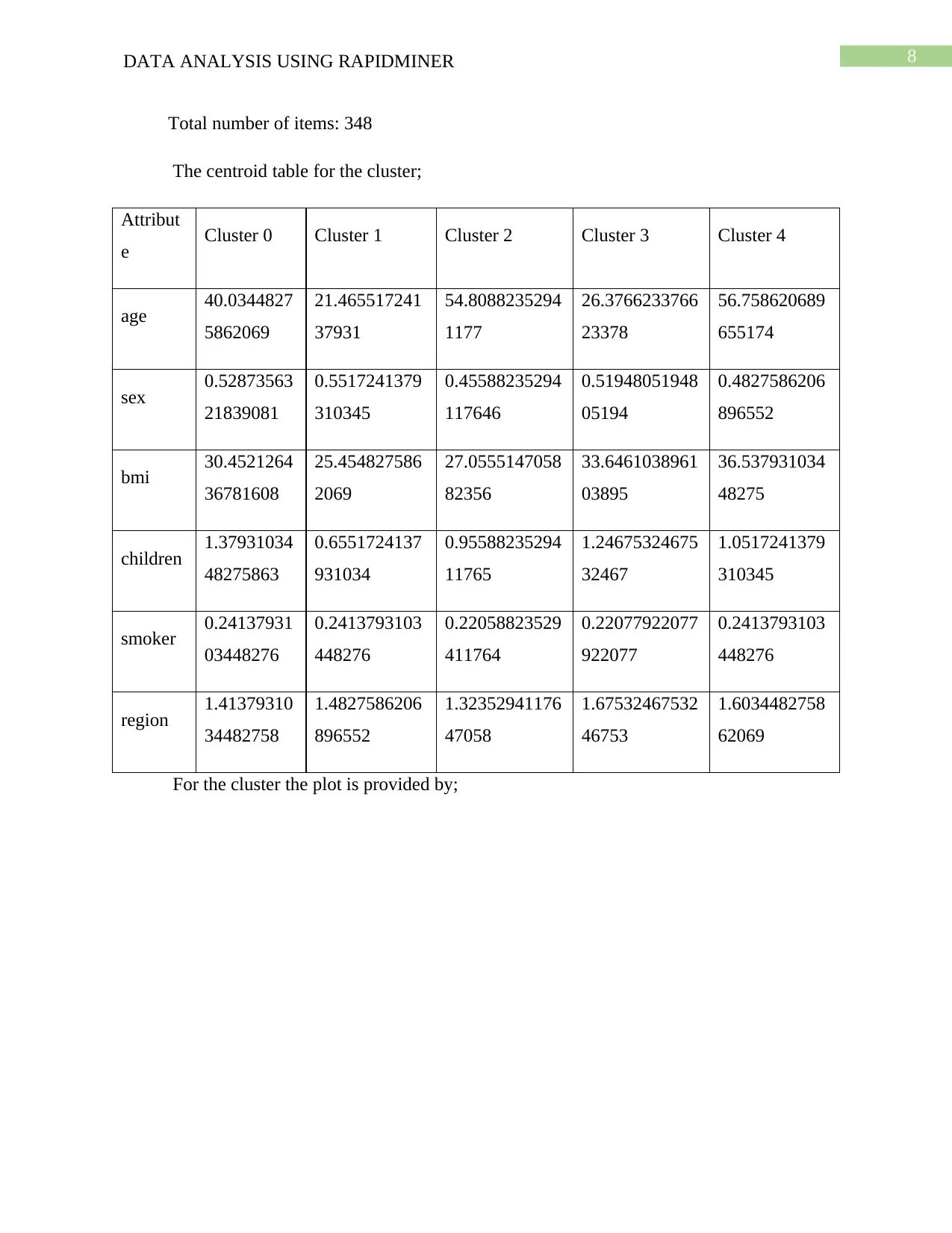
Total number of items: 348
The centroid table for the cluster;
Attribut
e Cluster 0 Cluster 1 Cluster 2 Cluster 3 Cluster 4
age 40.0344827
5862069
21.465517241
37931
54.8088235294
1177
26.3766233766
23378
56.758620689
655174
sex 0.52873563
21839081
0.5517241379
310345
0.45588235294
117646
0.51948051948
05194
0.4827586206
896552
bmi 30.4521264
36781608
25.454827586
2069
27.0555147058
82356
33.6461038961
03895
36.537931034
48275
children 1.37931034
48275863
0.6551724137
931034
0.95588235294
11765
1.24675324675
32467
1.0517241379
310345
smoker 0.24137931
03448276
0.2413793103
448276
0.22058823529
411764
0.22077922077
922077
0.2413793103
448276
region 1.41379310
34482758
1.4827586206
896552
1.32352941176
47058
1.67532467532
46753
1.6034482758
62069
For the cluster the plot is provided by;
Total number of items: 348
The centroid table for the cluster;
Attribut
e Cluster 0 Cluster 1 Cluster 2 Cluster 3 Cluster 4
age 40.0344827
5862069
21.465517241
37931
54.8088235294
1177
26.3766233766
23378
56.758620689
655174
sex 0.52873563
21839081
0.5517241379
310345
0.45588235294
117646
0.51948051948
05194
0.4827586206
896552
bmi 30.4521264
36781608
25.454827586
2069
27.0555147058
82356
33.6461038961
03895
36.537931034
48275
children 1.37931034
48275863
0.6551724137
931034
0.95588235294
11765
1.24675324675
32467
1.0517241379
310345
smoker 0.24137931
03448276
0.2413793103
448276
0.22058823529
411764
0.22077922077
922077
0.2413793103
448276
region 1.41379310
34482758
1.4827586206
896552
1.32352941176
47058
1.67532467532
46753
1.6034482758
62069
For the cluster the plot is provided by;
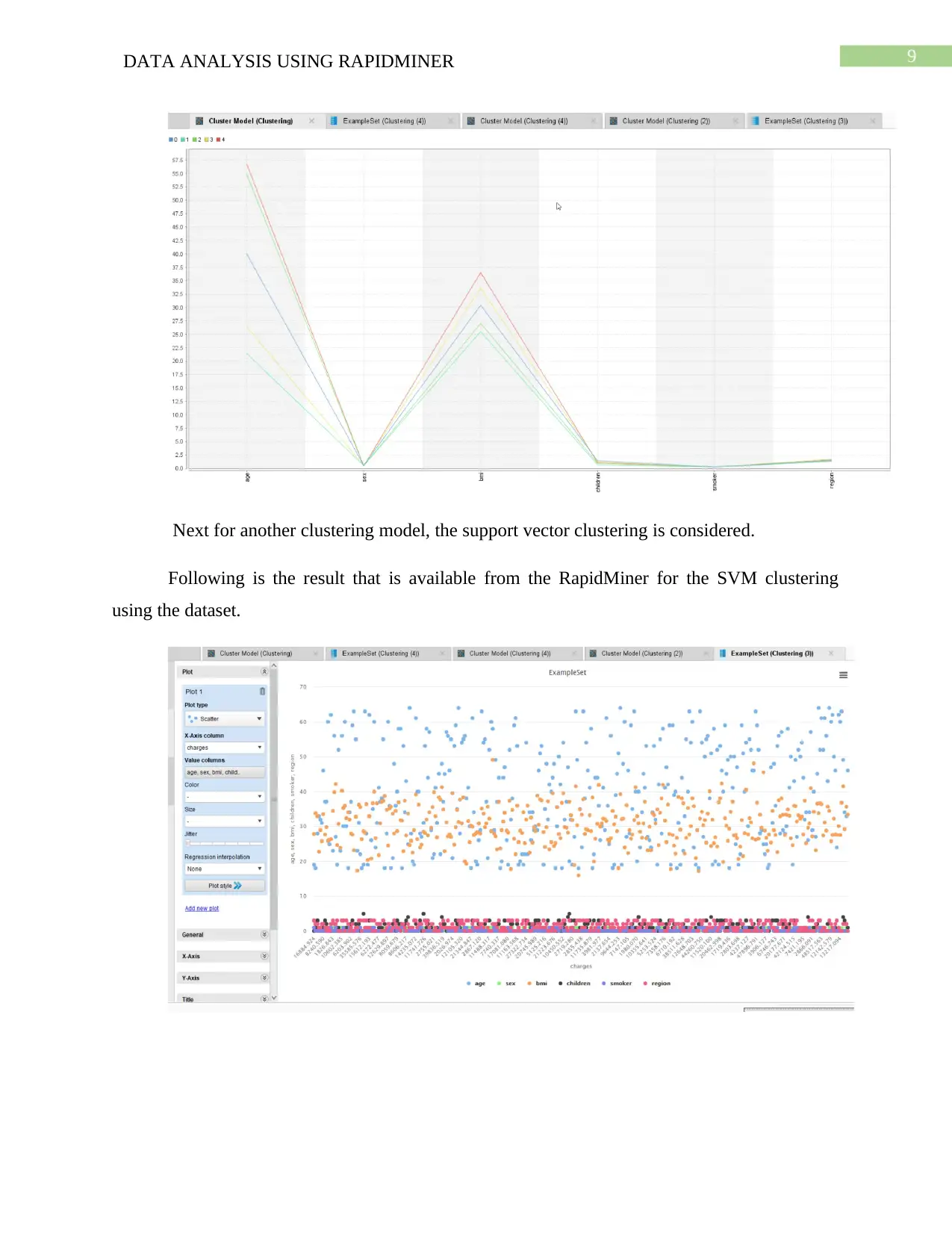
9DATA ANALYSIS USING RAPIDMINER
Next for another clustering model, the support vector clustering is considered.
Following is the result that is available from the RapidMiner for the SVM clustering
using the dataset.
Next for another clustering model, the support vector clustering is considered.
Following is the result that is available from the RapidMiner for the SVM clustering
using the dataset.
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

10DATA ANALYSIS USING RAPIDMINER
Conclusion
From the analysis of the data and their trends it can be stated that with the age and
smoking habits the cost or charges for the insurance changes accordingly. After this the patterns
are validated on the selected result by applying the explored patterns to the new and similar data
set the organization can make knowledge-based decisions. Data is generated from the numerous
sources and can be collected from after which it requires different data mining techniques in
order to extract and generate knowledge from the considered data that can be useful for a
specific purpose for an organization or market. This technique includes other classification,
clustering, prediction and so on.
Conclusion
From the analysis of the data and their trends it can be stated that with the age and
smoking habits the cost or charges for the insurance changes accordingly. After this the patterns
are validated on the selected result by applying the explored patterns to the new and similar data
set the organization can make knowledge-based decisions. Data is generated from the numerous
sources and can be collected from after which it requires different data mining techniques in
order to extract and generate knowledge from the considered data that can be useful for a
specific purpose for an organization or market. This technique includes other classification,
clustering, prediction and so on.

11DATA ANALYSIS USING RAPIDMINER
1 out of 12


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.