Data Mining and Visualization for Business Intelligence - Assignment 3
VerifiedAdded on 2024/05/31
|16
|2019
|331
AI Summary
This report analyzes the Business Requirements for pattern identification using data mining techniques. It focuses on comparing the performance of three classification algorithms: Decision Tree, Naïve Bayes, and K-Nearest Neighbor (k-NN) on the Soybean dataset. The analysis is conducted using Weka software, and the results are presented in terms of accuracy, precision, recall, and other performance metrics. The report concludes by discussing the strengths and weaknesses of each algorithm and recommending the most suitable algorithm for the given dataset.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

ITC 516
DATA MINING AND VISUALISATION FOR BUSINESS
INTELLIGENCE
ASSIGNMENT 3
Student Name: Gurwinder Singh
Student ID:
DATA MINING AND VISUALISATION FOR BUSINESS
INTELLIGENCE
ASSIGNMENT 3
Student Name: Gurwinder Singh
Student ID:
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Table of Contents
INTRODUCTION................................................................................................................................3
Task 1: DATA MINING TASK.............................................................................................................4
DECISION TREE.............................................................................................................................6
NAÏVE BAYES................................................................................................................................8
K-NEAREST NEIGHBOUR.............................................................................................................10
Task 2.............................................................................................................................................12
k-NN vs Naïve Bayes vs Decision Tree........................................................................................12
Algorithm Performance.............................................................................................................13
Conclusion......................................................................................................................................14
Reference.......................................................................................................................................15
List of table
Table 1: Analysis of k-NN, Naive Bayes and Decision Tree............................................................12
List of Figures
Figure 1: Weka Index Page..............................................................................................................4
Figure 2: Next Page..........................................................................................................................4
Figure 3: soybean.arff file................................................................................................................5
Figure 4: Soybean.arff file loaded in Weka for analysis..................................................................5
Figure 5: Accuracy of the Class using Decision Tree........................................................................6
Figure 6: Confusion Matrix by decision Tree Analysis.....................................................................6
Figure 7: Accuracy of the Class using Naive Bayes..........................................................................8
Figure 8: Confusion Matrix by Naive Bayes Analysis.......................................................................9
Figure 9: Accuracy of the Class using KNN Classifier.....................................................................10
Figure 10: Confusion Matrix by KNN Classifier Analysis................................................................11
INTRODUCTION................................................................................................................................3
Task 1: DATA MINING TASK.............................................................................................................4
DECISION TREE.............................................................................................................................6
NAÏVE BAYES................................................................................................................................8
K-NEAREST NEIGHBOUR.............................................................................................................10
Task 2.............................................................................................................................................12
k-NN vs Naïve Bayes vs Decision Tree........................................................................................12
Algorithm Performance.............................................................................................................13
Conclusion......................................................................................................................................14
Reference.......................................................................................................................................15
List of table
Table 1: Analysis of k-NN, Naive Bayes and Decision Tree............................................................12
List of Figures
Figure 1: Weka Index Page..............................................................................................................4
Figure 2: Next Page..........................................................................................................................4
Figure 3: soybean.arff file................................................................................................................5
Figure 4: Soybean.arff file loaded in Weka for analysis..................................................................5
Figure 5: Accuracy of the Class using Decision Tree........................................................................6
Figure 6: Confusion Matrix by decision Tree Analysis.....................................................................6
Figure 7: Accuracy of the Class using Naive Bayes..........................................................................8
Figure 8: Confusion Matrix by Naive Bayes Analysis.......................................................................9
Figure 9: Accuracy of the Class using KNN Classifier.....................................................................10
Figure 10: Confusion Matrix by KNN Classifier Analysis................................................................11

INTRODUCTION
Data Mining is a process that uses complicated data to order to gain some insight over that
Data using some complex Data Analytics measures to discover patterns that are known or
unknown. There are various tools that are to be used for the data analysis and processing phase
and can help in creating a better data analytics approach for finding a better understanding of
that data. To implement any Dataset a Knowledge Base is used that knowledge base is going to
help in making a better prediction task and help in analysing the data in a much better way
(Jadhav & Channe, 2016).
The aim of this report is to analyse the Business Requirements for the pattern identification.
This report is going to be focused on the different data mining problems that can help in
comparing the output pattern. In this report, critical analysis has been done for the data set
that is provided to analyse the data that is provided. There are several patterns that have been
analysed by the use of Weka software. Further, the Weka Software is going to provide the
better insight over the dataset.
The Dataset that is used in this analysis report is an ARFF data ARFF stands for Attribute-
Relation File Format that is a file format used by ASCII text files. It includes a list of all the
instances of the attributes. It is used in Weka Software for the Machine Learning Projects. This
report is going to be focused on three data classification algorithms and using the analysis
reports form them finding out which one is best in order to find out the better processing.
Data Mining is a process that uses complicated data to order to gain some insight over that
Data using some complex Data Analytics measures to discover patterns that are known or
unknown. There are various tools that are to be used for the data analysis and processing phase
and can help in creating a better data analytics approach for finding a better understanding of
that data. To implement any Dataset a Knowledge Base is used that knowledge base is going to
help in making a better prediction task and help in analysing the data in a much better way
(Jadhav & Channe, 2016).
The aim of this report is to analyse the Business Requirements for the pattern identification.
This report is going to be focused on the different data mining problems that can help in
comparing the output pattern. In this report, critical analysis has been done for the data set
that is provided to analyse the data that is provided. There are several patterns that have been
analysed by the use of Weka software. Further, the Weka Software is going to provide the
better insight over the dataset.
The Dataset that is used in this analysis report is an ARFF data ARFF stands for Attribute-
Relation File Format that is a file format used by ASCII text files. It includes a list of all the
instances of the attributes. It is used in Weka Software for the Machine Learning Projects. This
report is going to be focused on three data classification algorithms and using the analysis
reports form them finding out which one is best in order to find out the better processing.
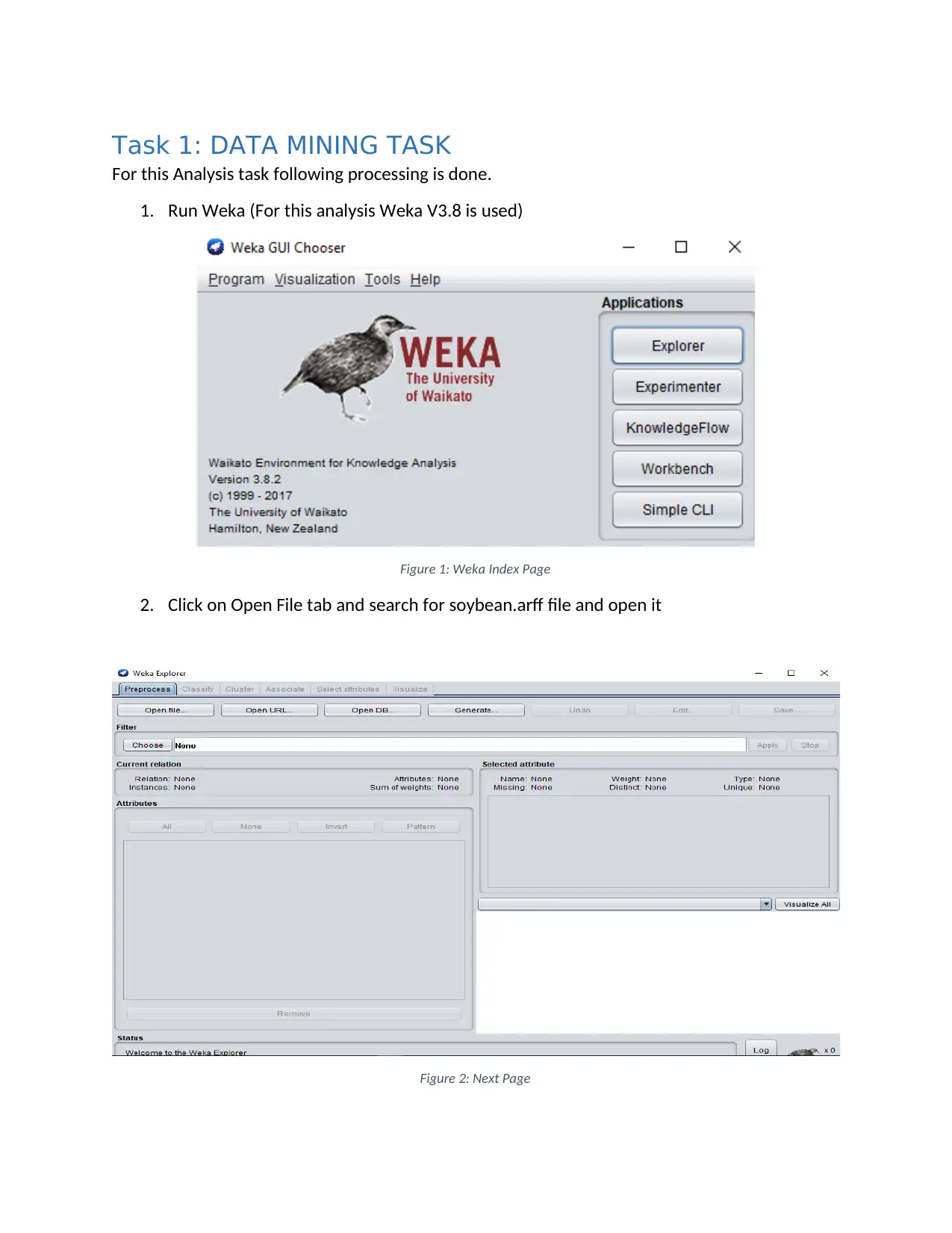
Task 1: DATA MINING TASK
For this Analysis task following processing is done.
1. Run Weka (For this analysis Weka V3.8 is used)
Figure 1: Weka Index Page
2. Click on Open File tab and search for soybean.arff file and open it
Figure 2: Next Page
For this Analysis task following processing is done.
1. Run Weka (For this analysis Weka V3.8 is used)
Figure 1: Weka Index Page
2. Click on Open File tab and search for soybean.arff file and open it
Figure 2: Next Page
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
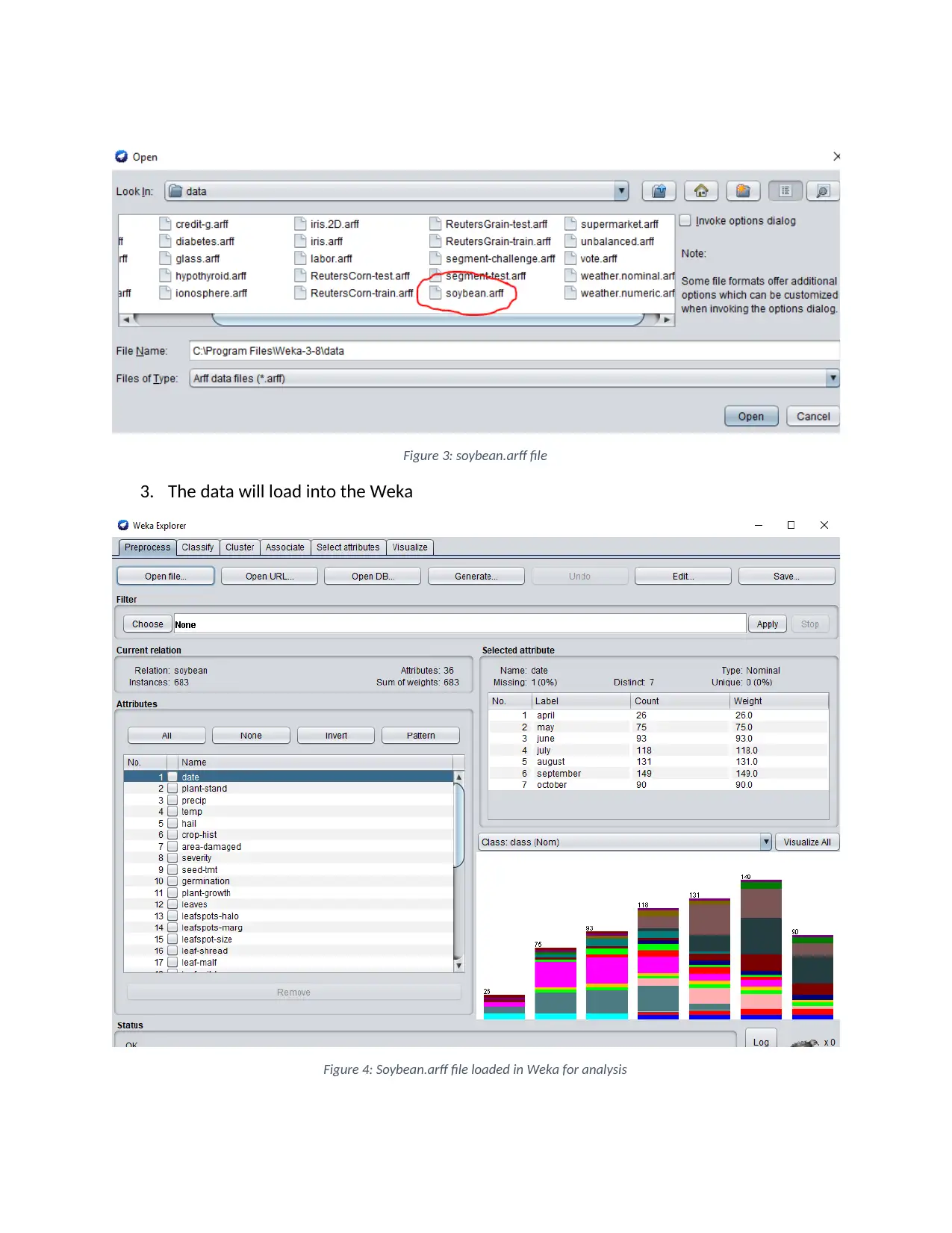
Figure 3: soybean.arff file
3. The data will load into the Weka
Figure 4: Soybean.arff file loaded in Weka for analysis
3. The data will load into the Weka
Figure 4: Soybean.arff file loaded in Weka for analysis


DECISION TREE
Decision tree is a Machine Learning Classifier that is used for analysing the data by visually or
Explicitly creating a decision tree that could help in making the decision. A decision tree is
drawn from upside down allowing the root node to be at the top and other internal nodes
follow by splitting the tree in edges and leaf nodes. The Decision tree is going to help in making
a tree-like structure that could help in creating a decision model for the Soybean dataset
(Barros, Basgalupp, de Carvalho & Quiles, 2012).
Figure 5: Accuracy of the Class using Decision Tree
Figure 3 is the Accuracy rate of the Whole Dataset by the Decision Tree by analysing this figure
the Precision comes out to be 0.917 that means the data is highly precise regarding this
dataset.
Figure 6: Confusion Matrix by decision Tree Analysis
Decision tree is a Machine Learning Classifier that is used for analysing the data by visually or
Explicitly creating a decision tree that could help in making the decision. A decision tree is
drawn from upside down allowing the root node to be at the top and other internal nodes
follow by splitting the tree in edges and leaf nodes. The Decision tree is going to help in making
a tree-like structure that could help in creating a decision model for the Soybean dataset
(Barros, Basgalupp, de Carvalho & Quiles, 2012).
Figure 5: Accuracy of the Class using Decision Tree
Figure 3 is the Accuracy rate of the Whole Dataset by the Decision Tree by analysing this figure
the Precision comes out to be 0.917 that means the data is highly precise regarding this
dataset.
Figure 6: Confusion Matrix by decision Tree Analysis
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Confusion Matrix Can help in finding out the method by which all the data can be linked. Figure
6 defines the Confusion Matrix that is going to help in making a prediction analysis over the
Soybean dataset.
6 defines the Confusion Matrix that is going to help in making a prediction analysis over the
Soybean dataset.

NAÏVE BAYES
Naïve Bayes Classifier Technique is simple classifier based on Bayes theorem it has an
independence assumption schema that can help in classification in much better and efficient
manner. The scalability in the Naïve Bayes is high and that requires a number of predictors for
creating a learning problem (Xiang, Yu & Kang, 2015).
Figure 7: Accuracy of the Class using Naive Bayes
Figure 7 shows the Accuracy rate of the Whole Dataset using the Naïve Bayes Classifier by
analysing this figure the Precision comes out to be 0.938 that means the data is highly precise
regarding this dataset and Naive Bayes can easily classify the dataset according to the different
attributes present within.
Naïve Bayes Classifier Technique is simple classifier based on Bayes theorem it has an
independence assumption schema that can help in classification in much better and efficient
manner. The scalability in the Naïve Bayes is high and that requires a number of predictors for
creating a learning problem (Xiang, Yu & Kang, 2015).
Figure 7: Accuracy of the Class using Naive Bayes
Figure 7 shows the Accuracy rate of the Whole Dataset using the Naïve Bayes Classifier by
analysing this figure the Precision comes out to be 0.938 that means the data is highly precise
regarding this dataset and Naive Bayes can easily classify the dataset according to the different
attributes present within.

Figure 8: Confusion Matrix by Naive Bayes Analysis
The Confusion Matrix helps in understanding all the attributes that are present in this soybean
data and help in defining the relationship between them. The aim of a confusion matrix is to
show how the other attributes will be related to each other. The diagonal of the matrix shows
the relationship between the attributes with other attributes
The Confusion Matrix helps in understanding all the attributes that are present in this soybean
data and help in defining the relationship between them. The aim of a confusion matrix is to
show how the other attributes will be related to each other. The diagonal of the matrix shows
the relationship between the attributes with other attributes
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

K-NEAREST NEIGHBOUR
K-Nearest Neighbour is also known as k-NN algorithm which is a Pattern Recognition Algorithm
use to depict the patterns in the data and help in classifying and applying regression over that
set of data. It produces Class Membership as an output. The input in this algorithm is the k
training closest examples that are used by this classifier as a feature space in the data (Yu,
Zhang, Huang & Xiong, 2009).
Figure 9: Accuracy of the Class using KNN Classifier
Figure 9 shows the Accuracy rate of the Whole Dataset using the K-Nearest Neighbour Classifier
by analysing this figure the Precision comes out to be 0.915 that means the data is highly
precise regarding this dataset but the performance of Naive Bayes is much more than the K-NN
Classifier. Further, this is a time-consuming process by which the performance is decreased to
this limit.
K-Nearest Neighbour is also known as k-NN algorithm which is a Pattern Recognition Algorithm
use to depict the patterns in the data and help in classifying and applying regression over that
set of data. It produces Class Membership as an output. The input in this algorithm is the k
training closest examples that are used by this classifier as a feature space in the data (Yu,
Zhang, Huang & Xiong, 2009).
Figure 9: Accuracy of the Class using KNN Classifier
Figure 9 shows the Accuracy rate of the Whole Dataset using the K-Nearest Neighbour Classifier
by analysing this figure the Precision comes out to be 0.915 that means the data is highly
precise regarding this dataset but the performance of Naive Bayes is much more than the K-NN
Classifier. Further, this is a time-consuming process by which the performance is decreased to
this limit.

Figure 10: Confusion Matrix by KNN Classifier Analysis
Confusion matrix helps in making the prediction based on the diagonal elements of the
attributes. Figure 10 shows the Confusion Matrix of the all those attributes present within the
overall attributes list and could help in making a better predictive modelling over the dataset
present.
Confusion matrix helps in making the prediction based on the diagonal elements of the
attributes. Figure 10 shows the Confusion Matrix of the all those attributes present within the
overall attributes list and could help in making a better predictive modelling over the dataset
present.
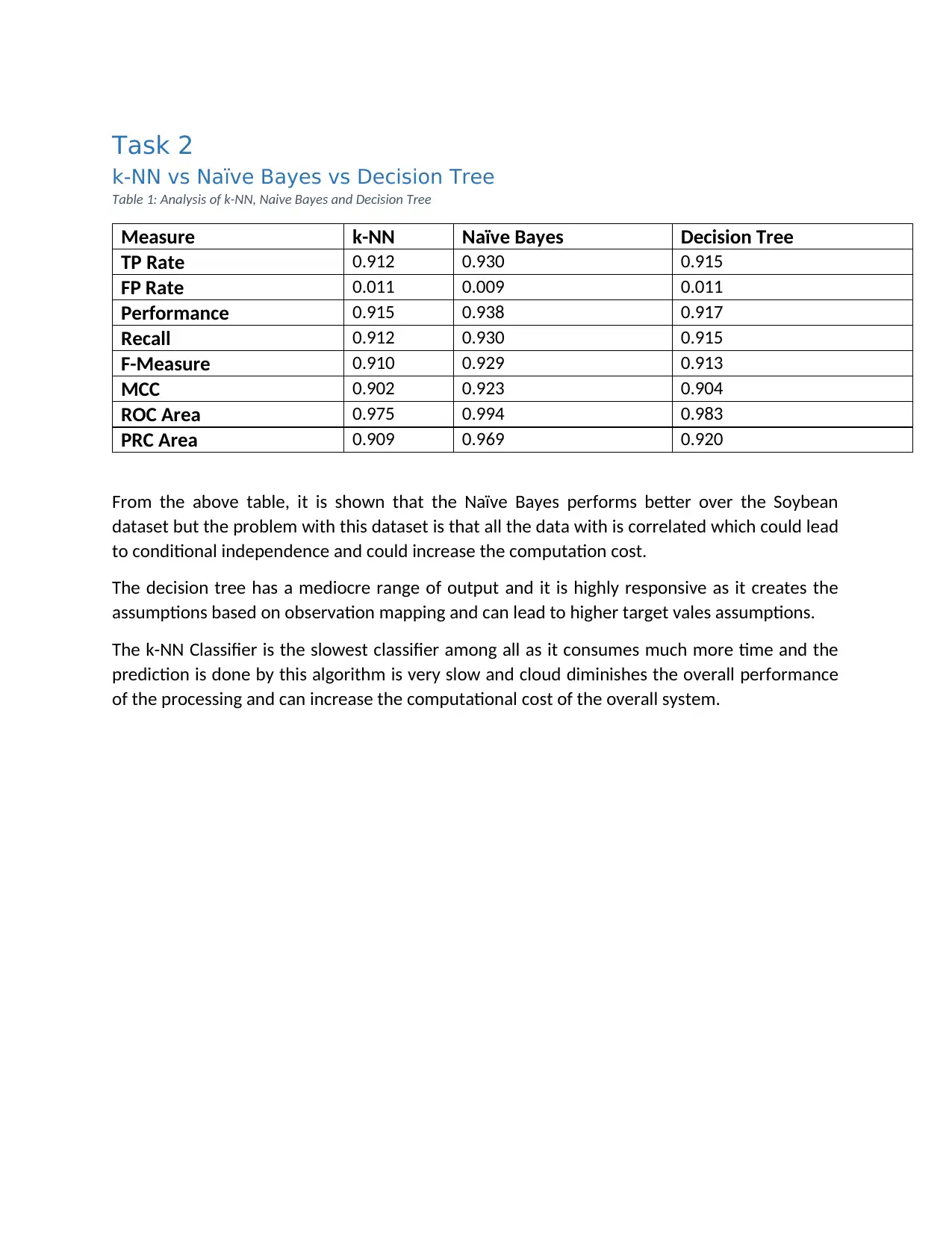
Task 2
k-NN vs Naïve Bayes vs Decision Tree
Table 1: Analysis of k-NN, Naive Bayes and Decision Tree
Measure k-NN Naïve Bayes Decision Tree
TP Rate 0.912 0.930 0.915
FP Rate 0.011 0.009 0.011
Performance 0.915 0.938 0.917
Recall 0.912 0.930 0.915
F-Measure 0.910 0.929 0.913
MCC 0.902 0.923 0.904
ROC Area 0.975 0.994 0.983
PRC Area 0.909 0.969 0.920
From the above table, it is shown that the Naïve Bayes performs better over the Soybean
dataset but the problem with this dataset is that all the data with is correlated which could lead
to conditional independence and could increase the computation cost.
The decision tree has a mediocre range of output and it is highly responsive as it creates the
assumptions based on observation mapping and can lead to higher target vales assumptions.
The k-NN Classifier is the slowest classifier among all as it consumes much more time and the
prediction is done by this algorithm is very slow and cloud diminishes the overall performance
of the processing and can increase the computational cost of the overall system.
k-NN vs Naïve Bayes vs Decision Tree
Table 1: Analysis of k-NN, Naive Bayes and Decision Tree
Measure k-NN Naïve Bayes Decision Tree
TP Rate 0.912 0.930 0.915
FP Rate 0.011 0.009 0.011
Performance 0.915 0.938 0.917
Recall 0.912 0.930 0.915
F-Measure 0.910 0.929 0.913
MCC 0.902 0.923 0.904
ROC Area 0.975 0.994 0.983
PRC Area 0.909 0.969 0.920
From the above table, it is shown that the Naïve Bayes performs better over the Soybean
dataset but the problem with this dataset is that all the data with is correlated which could lead
to conditional independence and could increase the computation cost.
The decision tree has a mediocre range of output and it is highly responsive as it creates the
assumptions based on observation mapping and can lead to higher target vales assumptions.
The k-NN Classifier is the slowest classifier among all as it consumes much more time and the
prediction is done by this algorithm is very slow and cloud diminishes the overall performance
of the processing and can increase the computational cost of the overall system.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Algorithm Performance
For this step all three classification algorithms are studied using the result from the previous
step and help in generating the better analysis result
1) To favor decision trees, have only a few attributes determine the correct answer, with all the
others useless distractions.
2) To favor Naive Bayes, construct 2n+1 attributes by choosing at random either n 1s and n+1 -
1s or n+1 1s and n -1s and assigning them to attributes at random. Make the right answer be
whether the bare majority is for +1 or -1.
3) To favor kNN, use two dimensional data and draw a broad spiral pattern of 1s in a
background of 0s, with about equal numbers of 0s or 1s. The right answer is whether you are
on a 0 or a 1.
kNN will certainly take up more memory at the time you are making decisions, as it has to
remember all the instances instead of boiling them down into weights and tree rules. It is also
expected that it will take more time at decision time, although there are libraries to attempt to
speed this up. Naive Bayes is probably the fastest and smallest.
There are a huge number of different ways to use decision trees, and some very sophisticated
developments of it, such as random forests, which could take a noticeable amount of time and
memory, but might do better on some data.
This performance is judged by creating a test dataset first by diving the whole dataset the ratio
of 60:40. The 60 % data is used for the testing phase as a classification model while the 40% I
used for the testing purpose.
After analyzing the Class Accuracy, it could be seen from the result and Table 1 that the
performance of Naïve Bayes is much better than both of the Classification techniques. The
naïve Bayes is going to help in making a better system model that can help in creating a much
more knowledgeable data information and could help in making the analysis much more
efficient.
For this step all three classification algorithms are studied using the result from the previous
step and help in generating the better analysis result
1) To favor decision trees, have only a few attributes determine the correct answer, with all the
others useless distractions.
2) To favor Naive Bayes, construct 2n+1 attributes by choosing at random either n 1s and n+1 -
1s or n+1 1s and n -1s and assigning them to attributes at random. Make the right answer be
whether the bare majority is for +1 or -1.
3) To favor kNN, use two dimensional data and draw a broad spiral pattern of 1s in a
background of 0s, with about equal numbers of 0s or 1s. The right answer is whether you are
on a 0 or a 1.
kNN will certainly take up more memory at the time you are making decisions, as it has to
remember all the instances instead of boiling them down into weights and tree rules. It is also
expected that it will take more time at decision time, although there are libraries to attempt to
speed this up. Naive Bayes is probably the fastest and smallest.
There are a huge number of different ways to use decision trees, and some very sophisticated
developments of it, such as random forests, which could take a noticeable amount of time and
memory, but might do better on some data.
This performance is judged by creating a test dataset first by diving the whole dataset the ratio
of 60:40. The 60 % data is used for the testing phase as a classification model while the 40% I
used for the testing purpose.
After analyzing the Class Accuracy, it could be seen from the result and Table 1 that the
performance of Naïve Bayes is much better than both of the Classification techniques. The
naïve Bayes is going to help in making a better system model that can help in creating a much
more knowledgeable data information and could help in making the analysis much more
efficient.

Conclusion
From the analysis done in the previous steps between the k-NN, Naïve Bayes and Decision Tree
as a Classification algorithm. It can be deduced that however, Naïve Bayes has a better
performance but Decision Tree is much better algorithm to process data because Decision Tree
is the Classification Algorithm that process more accurate results whilst having very fewer error
rates and it is very easy to implement than Naïve Bayes or the k-NN classifier. The knowledge
representation in the Decision tree is done by using a simple IF-THEN approach that is very
easier to understand by a human. The processing of the dataset is done by the use of WEKA
software and can help in implementing those outputs.
From the analysis done in the previous steps between the k-NN, Naïve Bayes and Decision Tree
as a Classification algorithm. It can be deduced that however, Naïve Bayes has a better
performance but Decision Tree is much better algorithm to process data because Decision Tree
is the Classification Algorithm that process more accurate results whilst having very fewer error
rates and it is very easy to implement than Naïve Bayes or the k-NN classifier. The knowledge
representation in the Decision tree is done by using a simple IF-THEN approach that is very
easier to understand by a human. The processing of the dataset is done by the use of WEKA
software and can help in implementing those outputs.

Reference
Jadhav, S., & Channe, H. (2016). Comparative Study of K-NN, Naive Bayes and Decision Tree
Classification Techniques. International Journal Of Science And Research (IJSR), 5(1), 1842-1845.
doi: 10.21275/v5i1.nov153131
Barros, R., Basgalupp, M., de Carvalho, A., & Quiles, M. (2012). Clus-DTI: improving decision-
tree classification with a clustering-based decision-tree induction algorithm. Journal Of The
Brazilian Computer Society, 18(4), 351-362. doi: 10.1007/s13173-012-0075-5
Yu, C., Zhang, R., Huang, Y., & Xiong, H. (2009). High-dimensional kNN joins with incremental
updates. Geoinformatica, 14(1), 55-82. doi: 10.1007/s10707-009-0076-5
Xiang, Z., Yu, X., & Kang, D. (2015). Experimental analysis of naïve Bayes classifier based on an
attribute weighting framework with smooth kernel density estimations. Applied
Intelligence, 44(3), 611-620. doi: 10.1007/s10489-015-0719-1
Jadhav, S., & Channe, H. (2016). Comparative Study of K-NN, Naive Bayes and Decision Tree
Classification Techniques. International Journal Of Science And Research (IJSR), 5(1), 1842-1845.
doi: 10.21275/v5i1.nov153131
Barros, R., Basgalupp, M., de Carvalho, A., & Quiles, M. (2012). Clus-DTI: improving decision-
tree classification with a clustering-based decision-tree induction algorithm. Journal Of The
Brazilian Computer Society, 18(4), 351-362. doi: 10.1007/s13173-012-0075-5
Yu, C., Zhang, R., Huang, Y., & Xiong, H. (2009). High-dimensional kNN joins with incremental
updates. Geoinformatica, 14(1), 55-82. doi: 10.1007/s10707-009-0076-5
Xiang, Z., Yu, X., & Kang, D. (2015). Experimental analysis of naïve Bayes classifier based on an
attribute weighting framework with smooth kernel density estimations. Applied
Intelligence, 44(3), 611-620. doi: 10.1007/s10489-015-0719-1
1 out of 16
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.