Statistics Assignment: Regression Analysis and Employee Performance
VerifiedAdded on 2023/06/11
|6
|796
|151
Homework Assignment
AI Summary
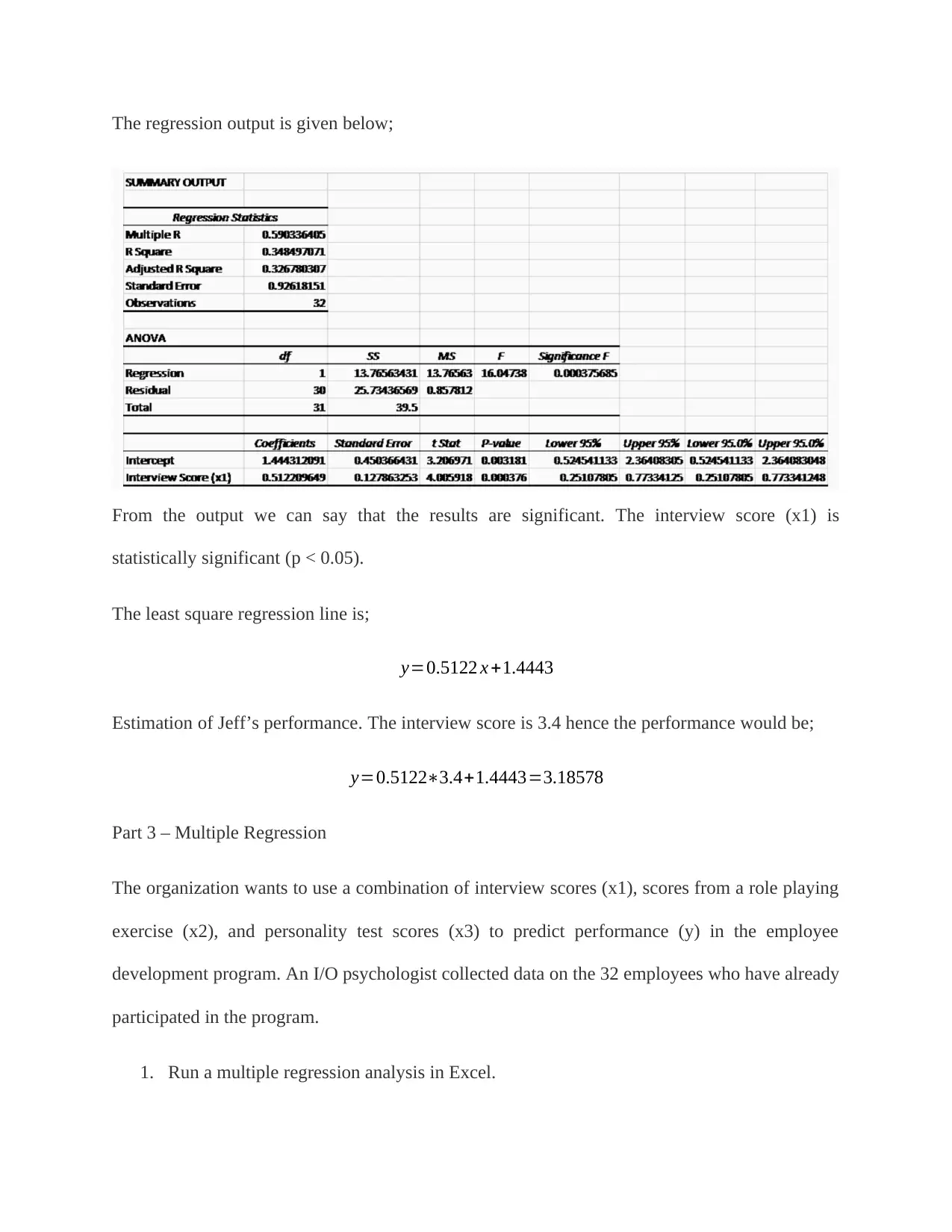
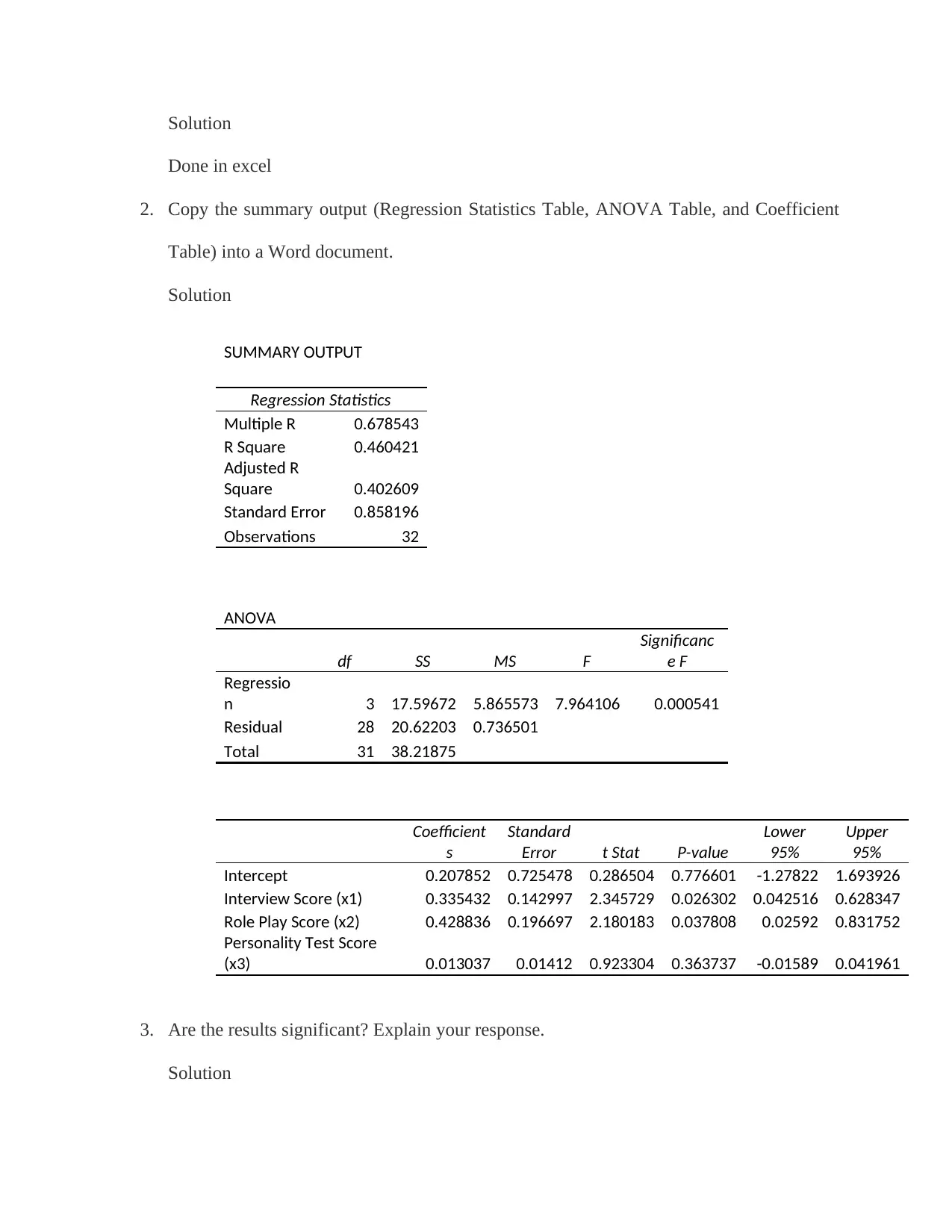
This statistics assignment provides a detailed solution covering various aspects of regression analysis. It begins by explaining key terminology such as R2, adjusted R2, beta, regression coefficient, hierarchical regression, multi-collinearity, curvilinear relationships, homoscedasticity, outliers, and residuals. The assignment then demonstrates simple linear regression, interpreting the significance of results and providing a least squares regression line. Furthermore, it delves into multiple regression analysis, using interview scores, role-playing exercise scores, and personality test scores to predict employee performance. The solution includes running a multiple regression analysis in Excel, interpreting the summary output, determining the significance of predictors, and estimating performance for candidates based on the regression model. Finally, a candidate is selected for an employee development program based on the regression analysis.




1 out of 6
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.