Comparative Study of KNN, J48, and Naive Bayes in Weka Environment
VerifiedAdded on 2023/06/07
|19
|2887
|140
Report
AI Summary
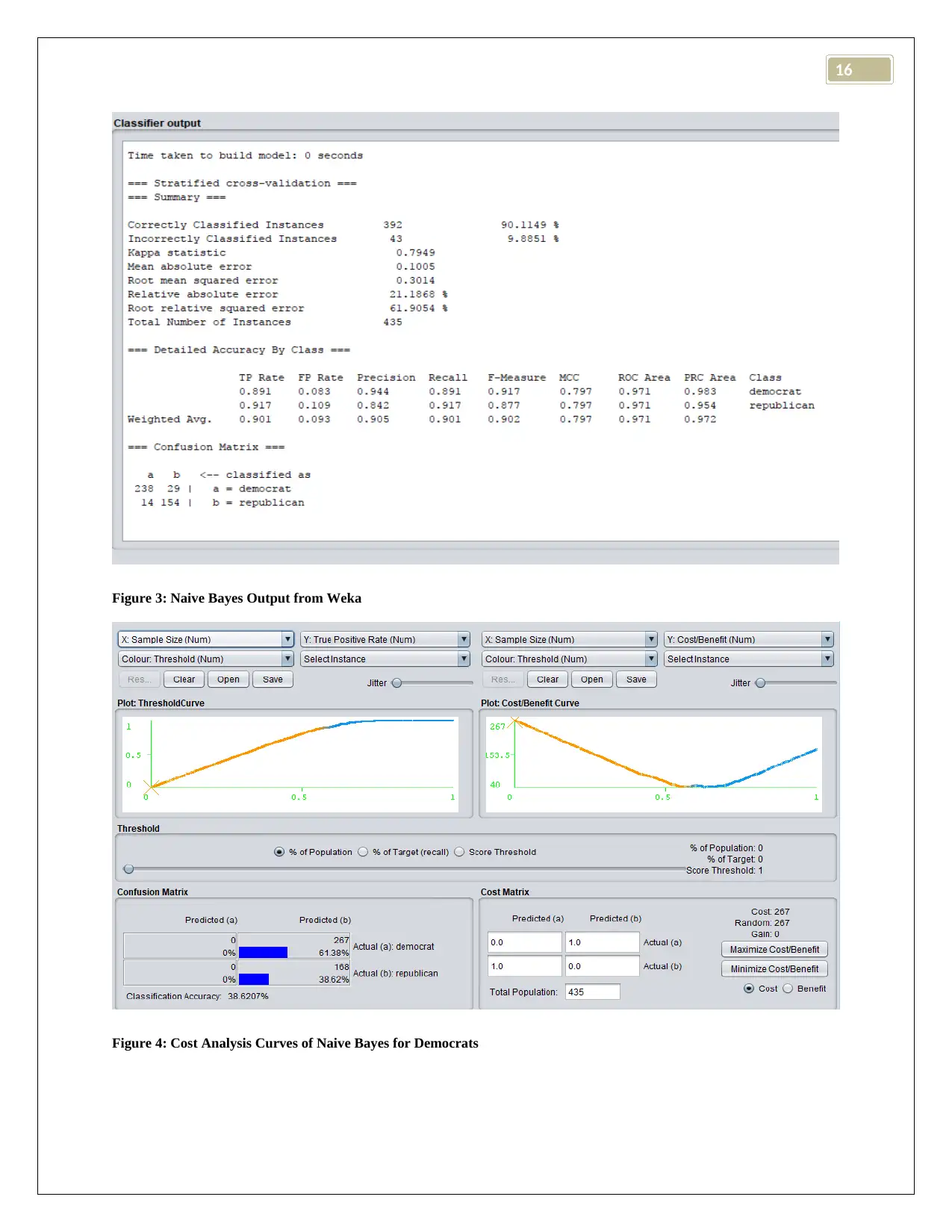
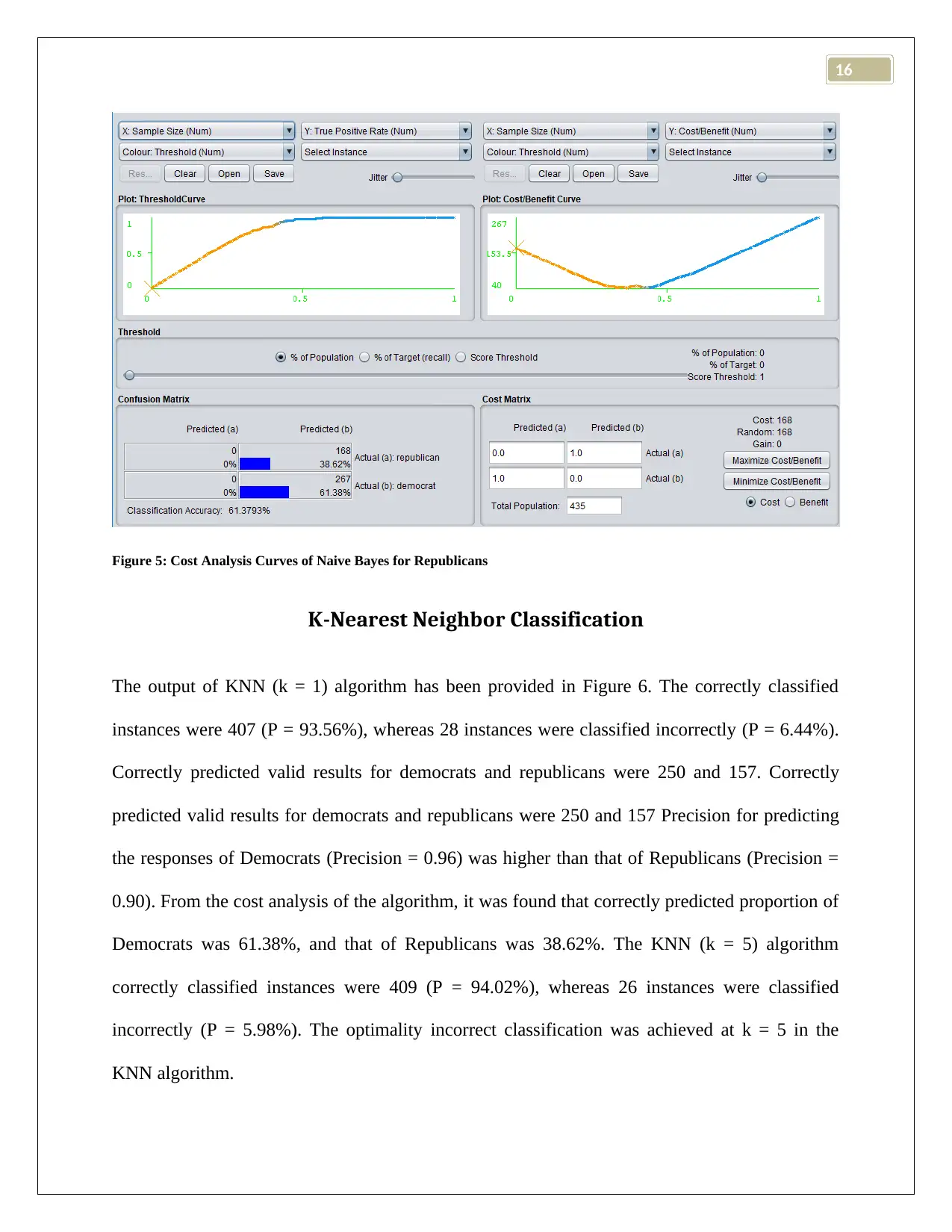
This report presents a comparative analysis of three classification algorithms: K-Nearest Neighbor (KNN), J48 (Decision Tree), and Naive Bayes, using the Weka data mining tool. The study utilizes the Vote.ARFF dataset and evaluates the performance of each algorithm based on metrics such as accuracy, precision, recall, and the confusion matrix. The report details the implementation of each classifier within the Weka environment, including the use of 10-fold cross-validation and the handling of missing values. The results section provides a comprehensive breakdown of each algorithm's performance, including correctly and incorrectly classified instances, precision for different classes, and cost analysis curves. The report concludes with a comparison of the algorithms, identifying J48 (Decision Tree) as the best-performing classifier for the given dataset and discussing the strengths and weaknesses of each approach, providing valuable insights for future research and application in data mining. The report highlights the importance of algorithm selection based on the specific dataset and application requirements.










1 out of 19
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.