SPSS Data Collection - Assignment
11 Pages1734 Words19 Views
Added on 2021-06-15
SPSS Data Collection - Assignment
Added on 2021-06-15
ShareRelated Documents

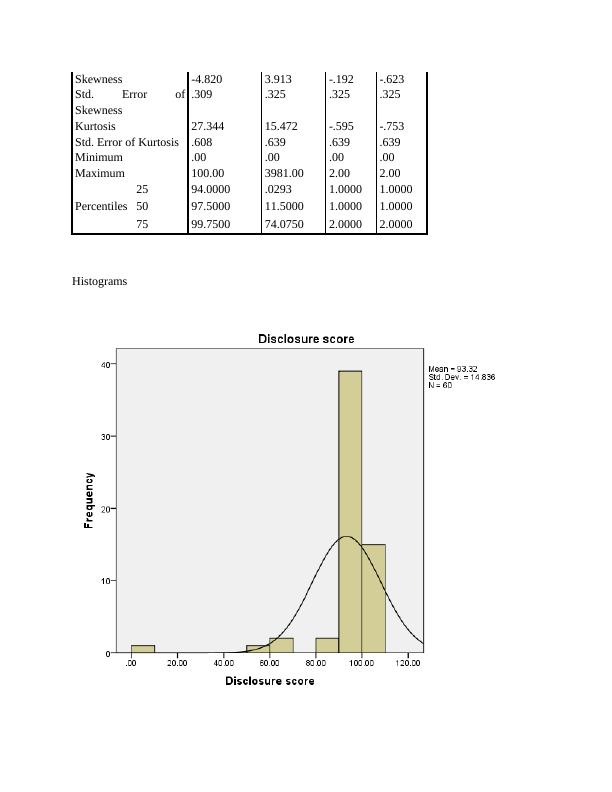
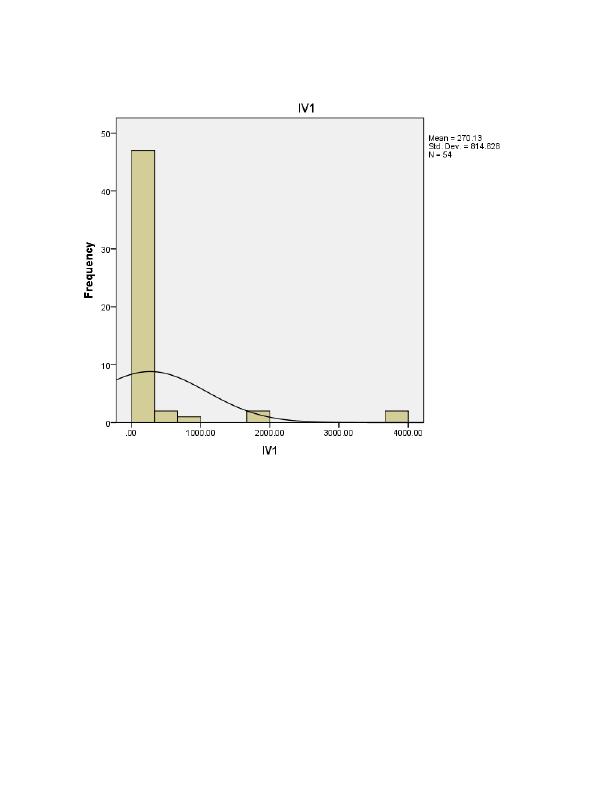
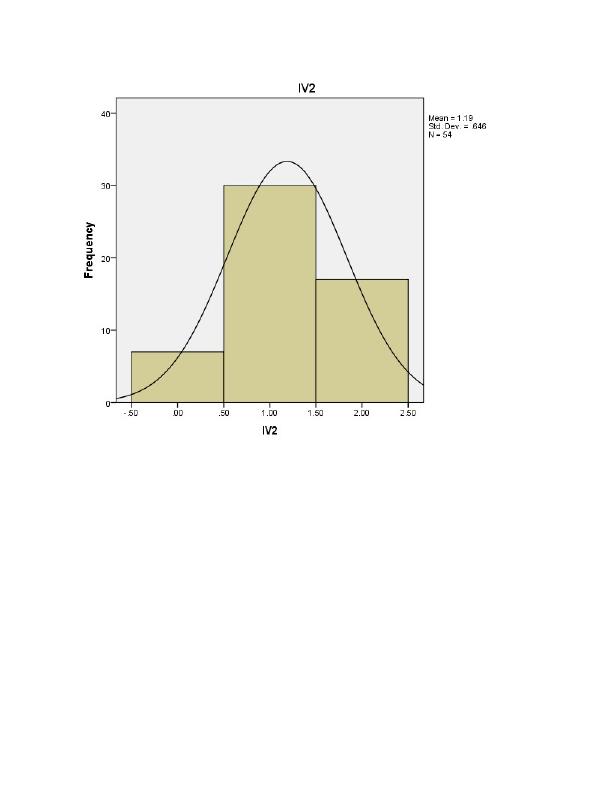
End of preview
Want to access all the pages? Upload your documents or become a member.
Data Collection and Analysis for Research Project
|15
|3138
|304
Data Collection and Descriptive Analysis of Coca Cola's Carbon Emission Data from 2011-2017
|13
|1877
|456
SPSS - Statistical Package for the Social Sciences
|12
|1701
|457
Frequencies and T-Test Analysis for Climate Change Management Incentives
|9
|564
|401
SPSS Bivariate and Multivariate Regression Analysis for Desklib
|31
|6069
|78
Quantitative Analysis: Summary Statistics, Histograms, Scatterplots, and Correlations
|12
|2069
|27